
既然 dropout 已經被去除了,接下來我們把目標瞄準到 batch normalization 優化吧,那該優化什麼呢?我們先來看看 batch normalization 在 tensorboard 上的狀態吧。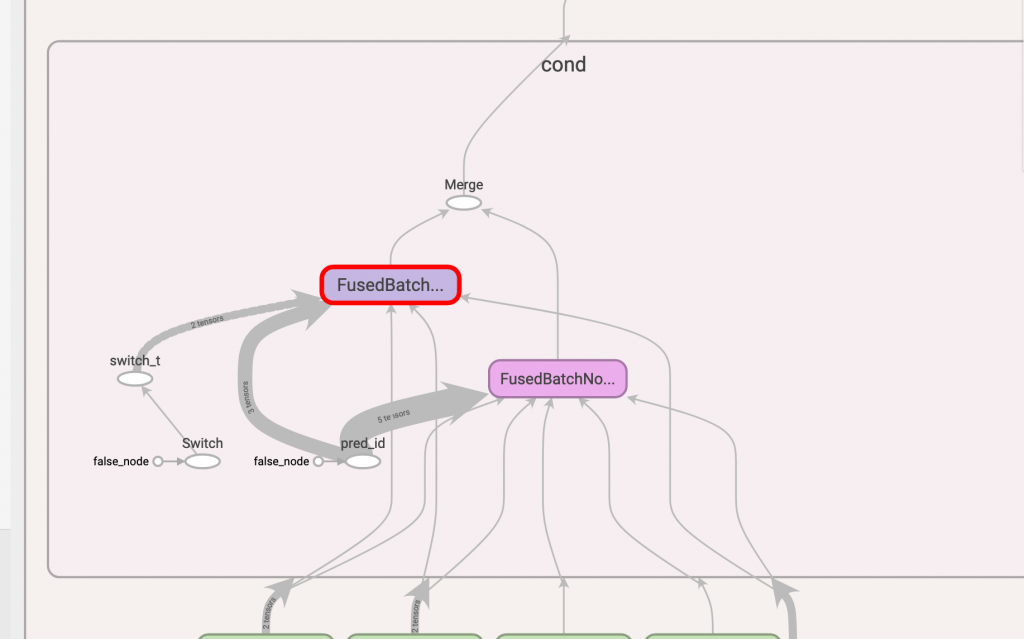
第一點:
有兩個 FusedBatchNorm ,在 day10 介紹了 batch normalization 在訓練和推論兩個模式下會有不同的行為,其中這次我們感興趣的是 FusedBatchNorm_1 這個節點,因為它含有 moving_mean 和 moving_var 是堆論模式下會所會用到的參數。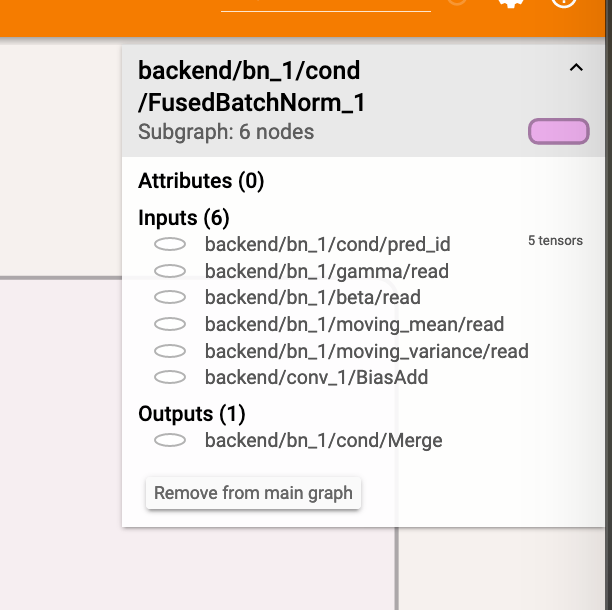
而從第一張圖來看,這兩個 FusedBatchNorm 都會指向到 merge 這個節點,所以我們優化的第一個重點就是只留 FusedBatchNorm_1 這條路啦!
那我們來撰寫 remove_merge 這個方法,這邊有個重點就是 Merge 這個節點會有兩個 input ,input[0] 的要保留,input[1] 不保留。
def remove_merge():
old_gd = tf.get_default_graph().as_graph_def()
old_nodes = old_gd.node
names_to_remove = {} # 產生一個dict記錄等等哪些節點要被砍掉
for node in old_nodes: # for所有節點
if node.op == 'Merge': # 當發現節點是Merge時
# FusedBatchNorm_1=0, FusedBatchNorm=1
# 將節點存到key,位置0存到value
names_to_remove[node.name] = node.input[0]
# 位置1因為要被砍,所以只存key
names_to_remove[node.input[1]] = None
print(f'remove merge: {names_to_remove}')
為什麼只保留 input[0] 而不保留 input[1] 呢?可以看到下圖中右上方資訊,第一個 input 是 FusedBatchNorm_1,位於 input[0],而我們不要的 FusedBatchNorm 是第二個輸入位於 input[1],所以 names_to_remove 就塞個 None 給它。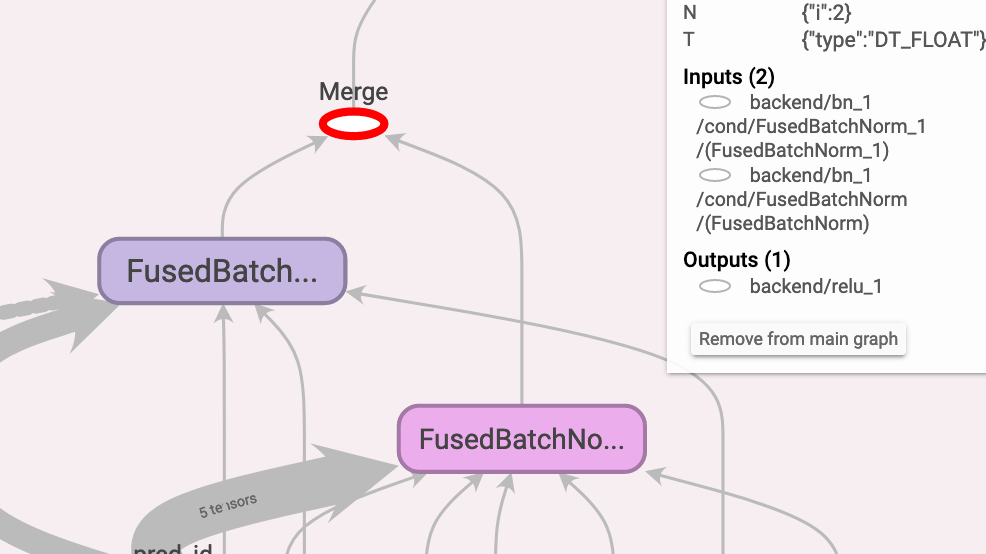
而 remove_merge 的後半段,跟前幾天的邏輯差不多,不一樣的地方在於多了要從 names_to_remove 找上個輸出這件事情,所以會多了 while 迴圈。
nodes_after_modify = []
for node in old_nodes: # for所有節點
if node.name in names_to_remove: # 如果是要被砍掉的就跳過
continue
new_node = node_def_pb2.NodeDef()
new_node.CopyFrom(node)
input_before_removal = node.input
del new_node.input[:]
for full_input_name in input_before_removal: # 檢查input節點
# 去除名稱中其他符號
input_name = re.sub(r"^\^", "", full_input_name)
# 如果input_name是要被砍的,就進迴圈
while input_name in names_to_remove:
# 找上個輸入
full_input_name = names_to_remove[input_name]
# 去除名稱中其他符號
input_name = re.sub(r"^\^", "", full_input_name)
# 把FusedBatchNorm_1加到新節點
new_node.input.append(full_input_name)
nodes_after_modify.append(new_node) # 新增該節點
new_gd = graph_pb2.GraphDef()
new_gd.node.extend(nodes_after_modify)
return new_gd
去除 merge 後的 graph,可以看到只留下 FusedBatchNorm_1 囉: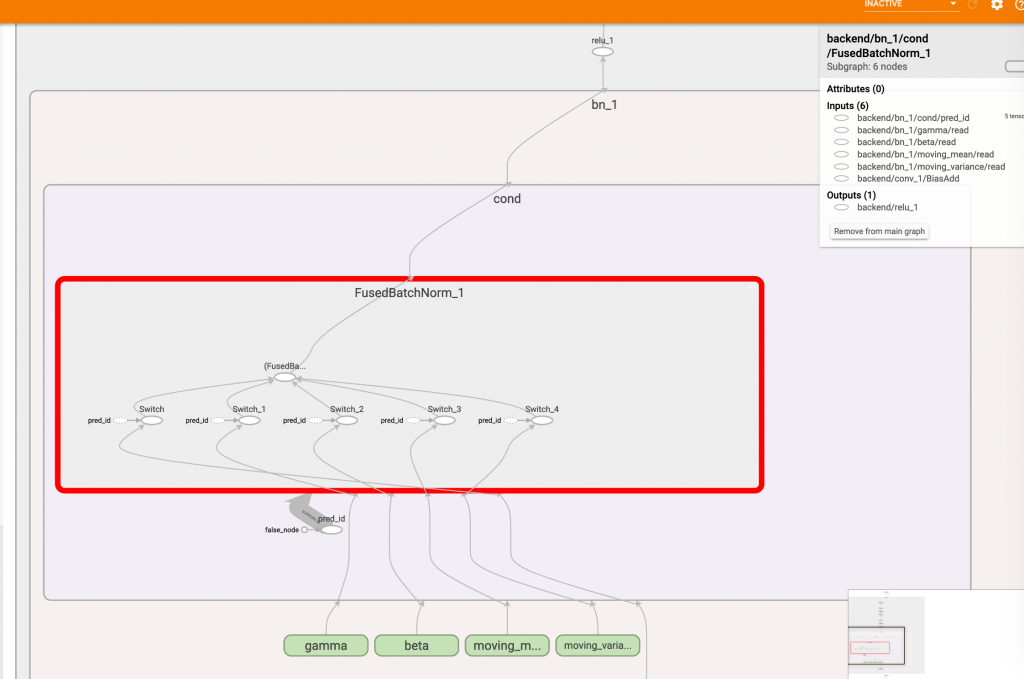
但各位有沒有注意到,圖中仍有個 false_node 指向 pred_id 節點再連接到 switch,這個東西就是用來控制要不要拿 gamma, beta, moving_mean, mean_var 的控制器,既然我們現在只要推論,那是不是連 switch 都可以拿掉呢?
當然可以,我們來撰寫 remove_switch() 的前半部,這次目標是找 switch,並且將這個 switch 的 input 檢查一遍,把 pred_id 以外的 input 存到 names_to_remove 這個 dict 中。
def remove_switch():
old_gd = tf.get_default_graph().as_graph_def()
old_nodes = old_gd.node
names_to_remove = {} # 產生一個dict記錄哪些節點要被砍掉
for node in old_nodes: # for所有節點
if node.op != 'Switch': # 當發現節點不是Switch時跳過
continue
for node_i in node.input: # 檢查Switch的input
# 若input是pred_id,把pred_id以外的input存到dict
if node_i.split('/')[-1] == 'pred_id':
names_to_remove[node.name] = [
x for x in node.input if x.split('/')[-1] != 'pred_id'
後半段的部分也和之前差不多,即跑一次所有節點,然後檢查每個節點的 input 是不是 switch,如果是就把上半部 dict 中的 input 補回去,程式碼如下:
nodes_after_modify = []
for node in old_nodes: # for所有節點
if node.name in names_to_remove:
continue # 如果是要被砍掉的就跳過
new_node = node_def_pb2.NodeDef() # 產生新節點
new_node.CopyFrom(node) # 拷貝舊節點資訊
input_before_removal = node.input
del new_node.input[:] # 去掉所有input
for full_input_name in input_before_removal:
if full_input_name in names_to_remove: # 如果此節點input是switch
for input_name in names_to_remove[full_input_name]:
# 就把names_to_remove的所有input補上
new_node.input.append(input_name)
else: # 不然一切照舊
new_node.input.append(full_input_name)
nodes_after_modify.append(new_node)
new_gd = graph_pb2.GraphDef()
new_gd.node.extend(nodes_after_modify)
return new_gd
再來看看執行後的成果吧: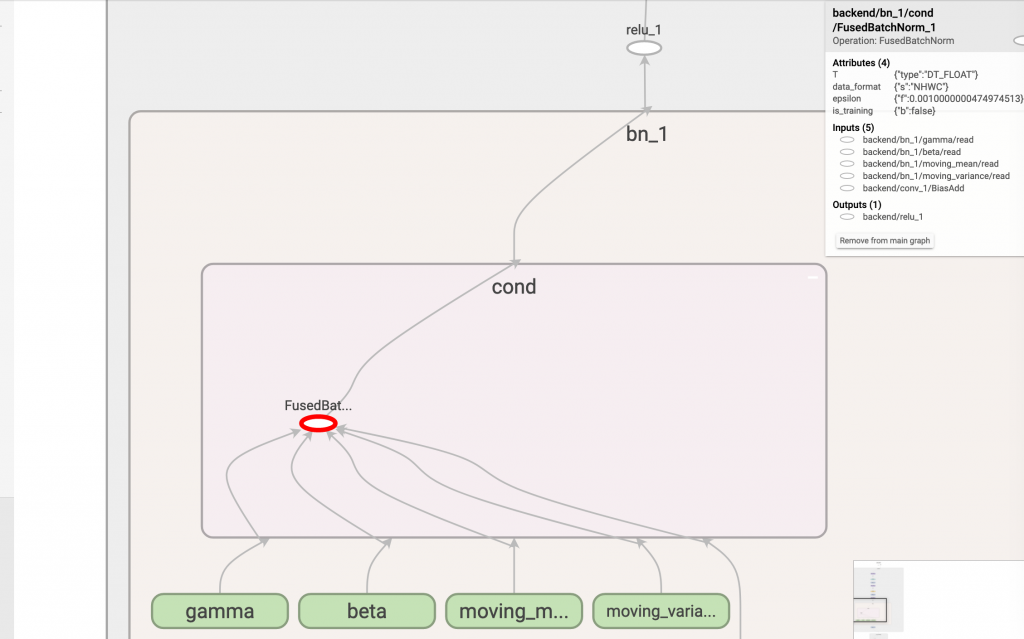
整個 FusedBatchNorm_1 變成一個節點,輸入直接連上 gamma, beta, moving_mean, mean_var 沒經過 switch,一看就很清爽!
再來是驗證數值的時候啦!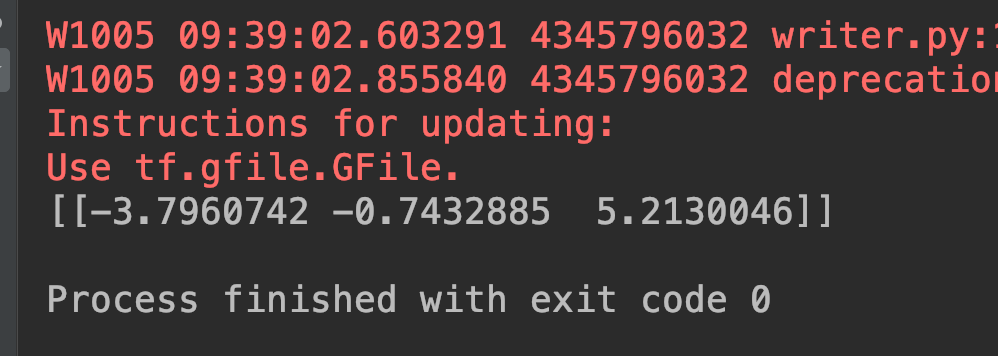
數值一樣,PASS !
