
這是第三十篇文章,今天想和大家分享的是 tf.lite,身處在大家人手一台智慧型手機的時代,神經網路能運用的地方無所不在,如果你今天想將模型部署到手機上面,那使用 Google 專門為移動式設備使用的模型 tf.lite 實在是再適合不過啦!
要產生 tf.lite 模型很簡單,你只要有符合的 pb 模型即可,而產生模型,你需要 tf.lite.TFLiteConverter,然後告訴你的輸入和輸出節點。
def main():
converter = tf.lite.TFLiteConverter.from_frozen_graph('../pb/frozen_shape_28.pb',
['new_input_node'], ['final_dense/MatMul'])
converter.optimizations = [tf.lite.Optimize.OPTIMIZE_FOR_LATENCY]
tflite_model = converter.convert()
with open("../tflite/model.lite", "wb") as f:
f.write(tflite_model)
而這邊我使用 pycharm 執行會有以下錯誤。
所以我後來是使用 command line 來執行。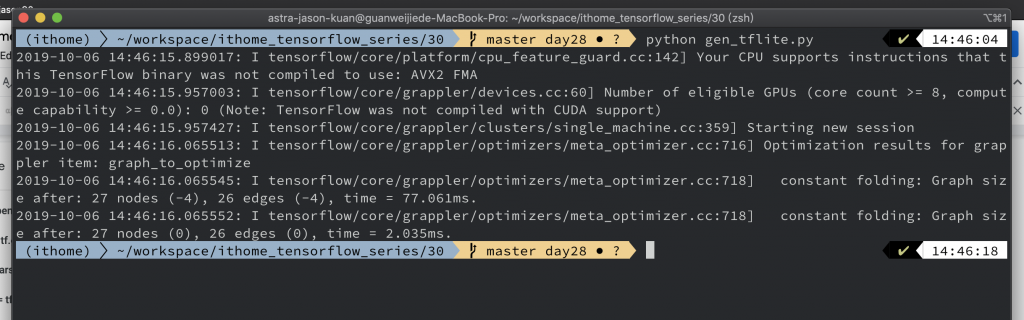
而產生出來的 lite 模型可以看到又比 pb 檔更小了。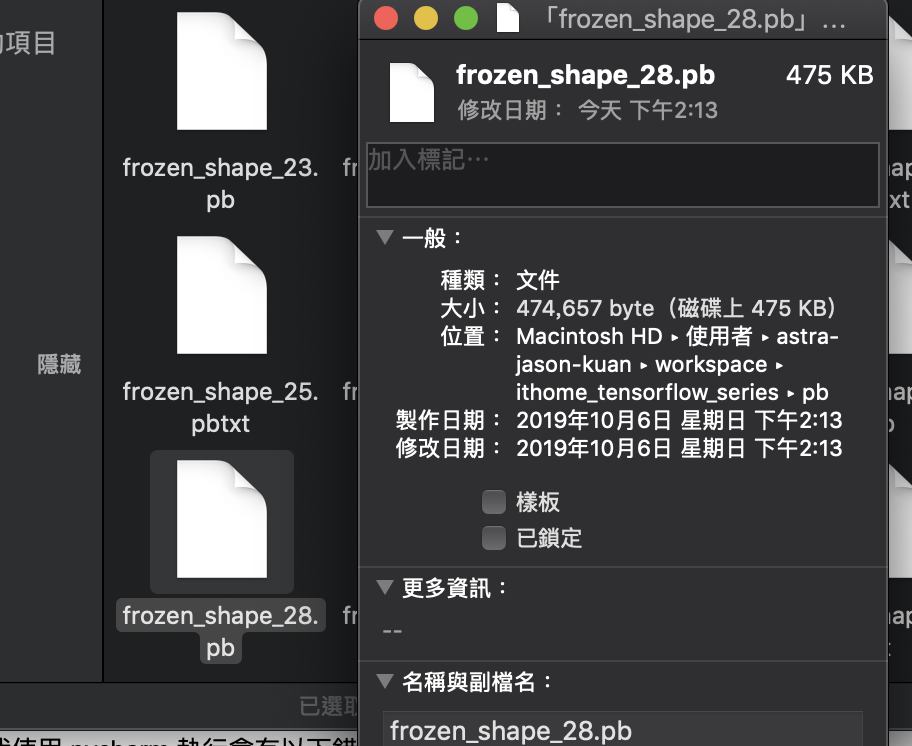
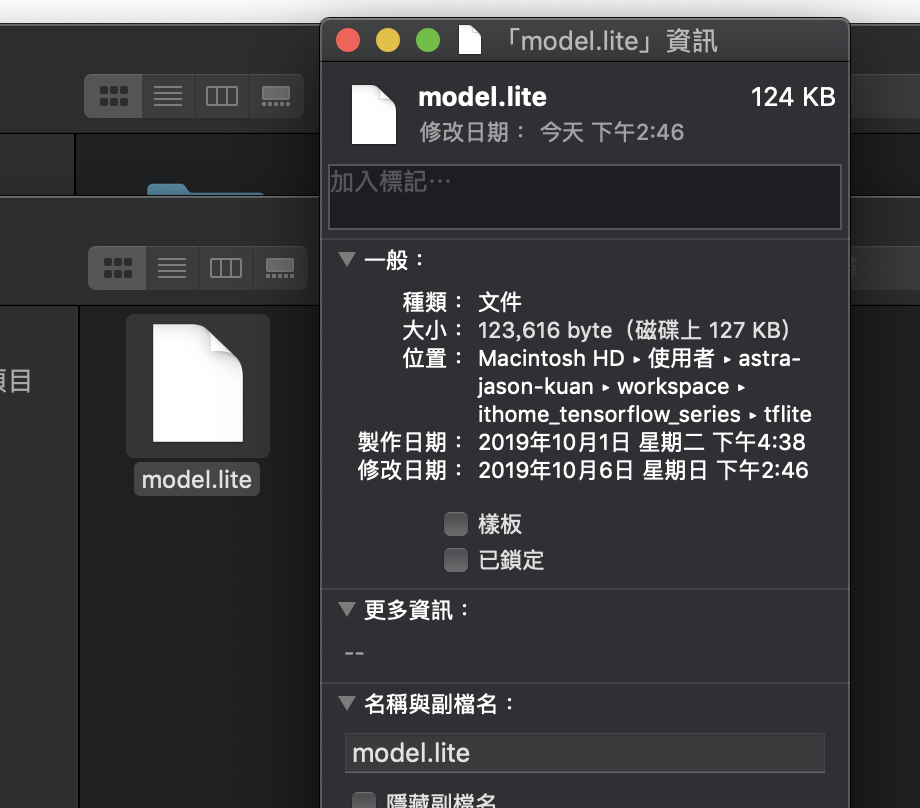
接下來測試推論速度,程式碼如下:
TIMES = 1000
def main():
interpreter = tf.lite.Interpreter(model_path="../tflite/model.lite")
interpreter.allocate_tensors()
input_index = interpreter.get_input_details()[0]["index"]
output_index = interpreter.get_output_details()[0]["index"]
image = cv2.imread('../05/ithome.jpg')
image = cv2.resize(image, (128, 128))
image = image.astype(np.float32)
start = timeit.default_timer()
for _ in range(0, TIMES):
interpreter.set_tensor(input_index, np.expand_dims(image, axis=0))
interpreter.invoke()
interpreter.get_tensor(output_index)
print(f'cost time:{(timeit.default_timer() - start)} sec')
結果: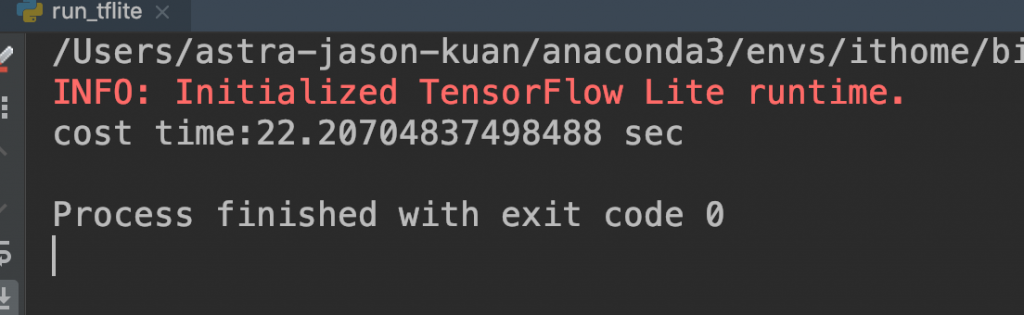
你會發現推論超級慢,這是因為我使用的是 Mac 去跑這個模型,tf.lite 因為主要的部屬環境是像手機等移動端,所使用的 CPU 是 ARM 架構,而我的 Mac 是 x86_64 架構,在這上面的表現並沒有很好。
有關 tf.lite 的短暫介紹就到這邊,謝謝讀著大家的閱讀!有關最後心得文我想發在 Day31 就等明天囉!

 iThome鐵人賽
iThome鐵人賽