
在監督式學習中,演算法分為兩種,分別為分類 (Classification) 及迴歸分析 (Regression),在進一步介紹之前,我們先來看一下等一下要作為例子的資料如下圖:
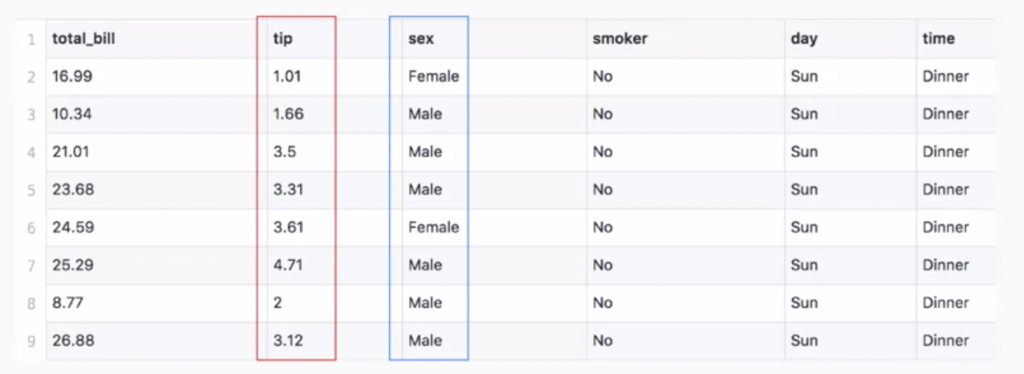
上面圖片是一個過往餐廳客人給小費的紀錄中,其中包含小費金額、客人性別、是否抽菸、星期、用餐時段等,而每一行都是一筆資料,我們想預測的項目叫做標籤 (Label) ,用來判斷預測項目的其他項目則叫做特徵 (Feature) ,以上圖為例,如果我們想預測客人可能會給的小費是多少,那在這種狀況下,小費數目就是我們的標籤,客人性別、是否抽菸、星期及用餐時段等則是用於預測的特徵。
繼續剛剛的例子,因為我們要預測的是小費金額,金額是一連串的數字,而且這,因此可以用迴歸分析,但如果要預測是的客人性別,客人性別並不是可以數列化的,因此用到的演算法則就會是分類。
雖然資料標籤是不是數字是可以用來判斷適合分類或迴歸分析演算法的一個判斷標準,但也不是一看到數字都認為一定可以用迴歸分析,還是要先確認該數字代表的是數字本身,而不是代表另一個意思,舉例來說,如果有一筆資料中把男性都以1標示,女性以2標示,其他則以3表示,如果你要把性別做為標籤時,就還是得用分類來進行演算,因為這些數字代表的並不單純為數字本身,而是會對應到其他涵義,如果硬要用迴歸分析,最後可能會得到性別是1.3這種答案出來,但1.3並無法對應到當初定義的任何一個性別,只好把他歸類為性別是秀吉,因此在選擇演算法之前還是要再了解原始資料個項目的涵義,如此才有辦法選擇到適用的演算法。

 iThome鐵人賽
iThome鐵人賽