今天開始,我們來聊聊非監督式的學習。前面所提的演算法,大部分都是監督式學習,也就是通常都是Label好的資訊 (Ex: 透過已經蒐集到的股價資訊或者已經Label好的圖片) 。
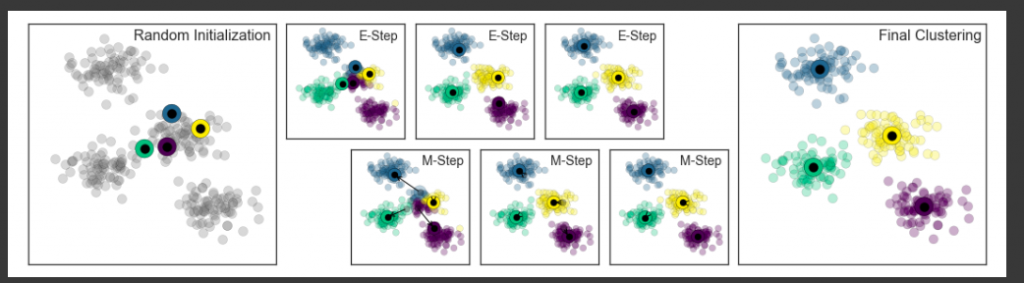
非監督式學習則是當今天資料都是沒有Label,如何透過特徵找出一些特徵群組。常見的使用場景:資料分群 (Ex: 客戶分群)、特徵降維 (Ex: PCA)...等。經典的非監督式學習就是 K-Means,大家應該都有聽過這個演算法。簡單來說,它就是透過資料相似度 (Ex: 歐式距離計算) 針對資料點做分群。
針對Deep learning,也有許多許多非監督式的模型。尤其最近很夯的DeepFake可以把任何影片中的人物無縫轉變成你想要變成的人 (使用GAN)。
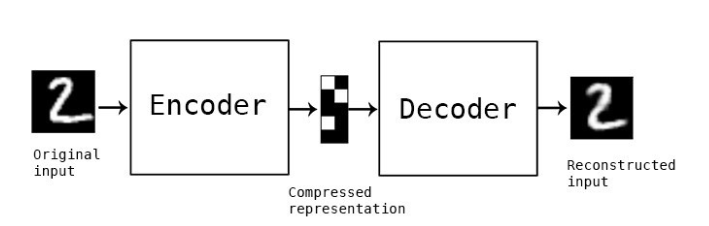
今天所討論的就是Deep learning中,最基本的非監督式網路 - AutoEncoder。AutoEncoder 中文稱為自動編碼器 (聽起來是不是怪怪的XD),核心概念有兩個部分 Encoder(編碼器)及 Decoder(解碼器) 。Encoder 可被理解為將資料中最重要的抽象特徵萃取出來 。Decoder就是透過這些重要的抽象特徵回推出原始的資料樣態。
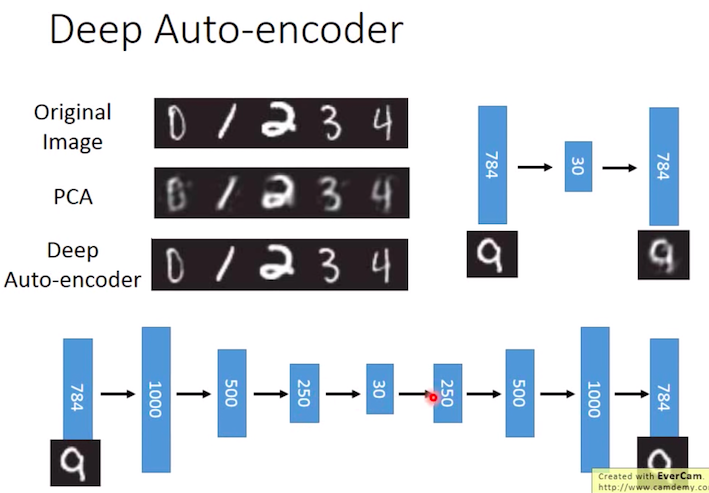
AutoEncoder的流程就是透過Enocder 將資料壓縮,或者可以看成投射到低維度的空間,最後利用 Decoder 將資料解碼到相同維度,並希望 input 資料與 output 資料要越相似越好。其中下圖的 Compressed representation 可被理解為低維度中的重要特徵或者最精簡且重要的representation。
而Encoder 跟 Decoder 的架構其實就是使用Deep Neural Network來train AutoEncoder,而架構不一定要symmetric。
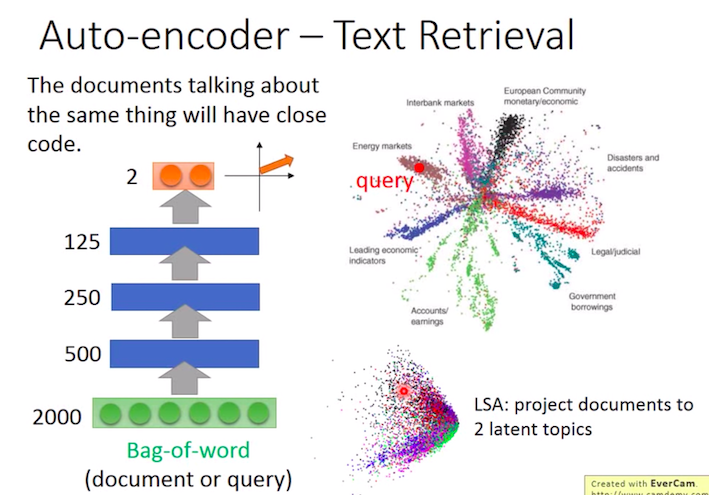
在應用上,以NLP為例,可透過AutoEncoder 針對 Bag of Word 進行句子或文章分群,最後可以針對這先分群做解釋並tagging。
今天將AutoEncoder介紹完,明天我們來實作看看AutoEncoder在 tf 2.0上。感謝大家漫長的閱讀~