
今天討論的主題主要是Google這篇曾經在2016年release 在Google Play的app上所做的推薦系統,而他有被open source 在 Tensorflow上。
針對Google所提出的Recommendation System的架構為下圖: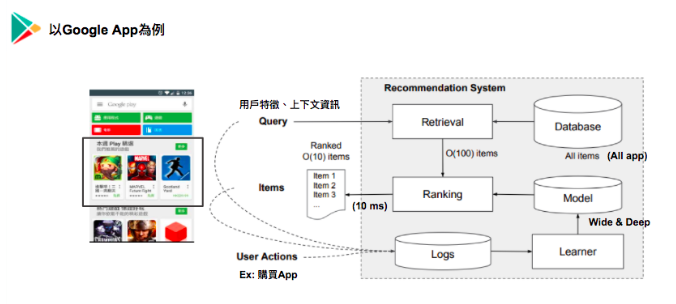
當使用者進入 Google Play,系統會針對使用者特徵以及頁面資訊對DB做檢索,從DB選出Top item針對Model 預測出來的結果做排序,並推薦產品。而Model所training的資料則是從使用者的行為資料所萃取出來。

其中,Wide & Deep 對 Google來說,是有設定 Wide & Deep 各自的任務。Wide Model希望利用歷史資料進行學習。透過歷史曾經發生的關係,達到精準預測(將歷史資料發揮淋漓盡致)。Deep Model 希望透過這個模型找到新的特徵組合,以增加模型預測結果的多樣性。
接下來簡單的說明Deep & Wide各自的模型:
針對Wide來說,其實就是使用Logistic Regression來預測。但主要比較特別的地方,在特徵處理的部分,他使用的Cross product的transformation,Ex: Cross_product_transformatopn ( feature [ Gender , Age] ) -> feature [ M X 0_18 , M X 19_25, ... ] )
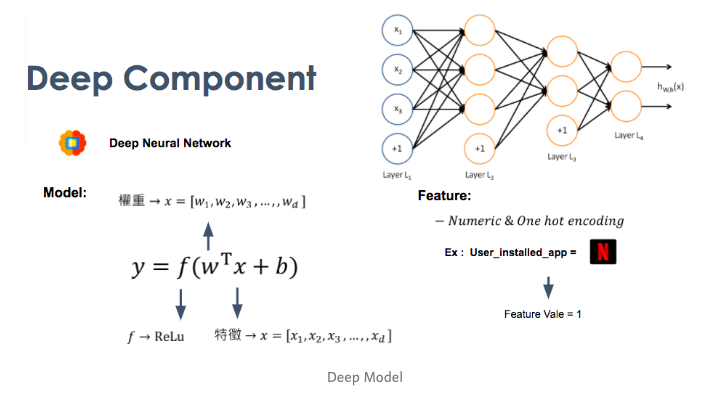
針對Deep來說,其實就是使用DNN來預測。使用One-hot encode去轉categorical 的特徵,並會放到Embedding layers。
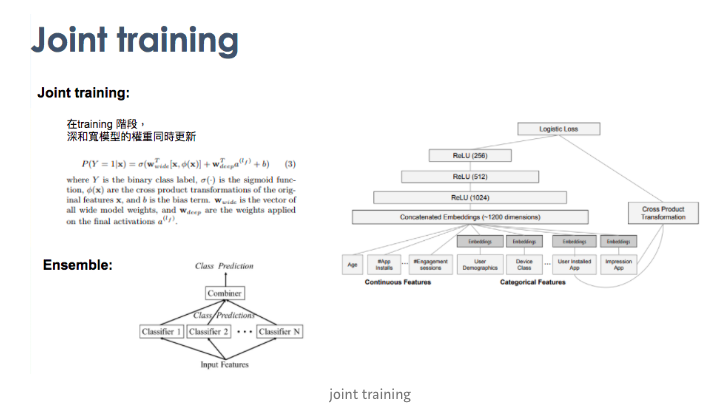
最後會把兩個 Joint training,有點類似Ensemble的概念。
接下來我們來跑一下 Deep & Wide:
首先我們會使用這份Data ,這份Data也是官方Deep & Wide tutorial的Dataset!
資料欄位包含 : 性別、年齡、教育 等等。長得如以下: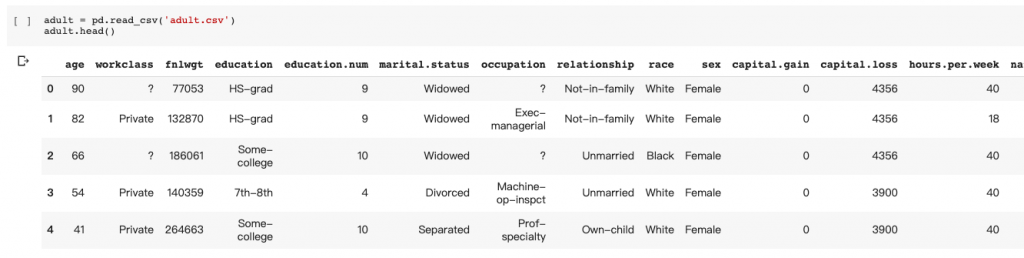
CSV_COLUMNS = [
"age", "workclass", "fnlwgt", "education", "education_num",
"marital_status", "occupation", "relationship", "race", "gender",
"capital_gain", "capital_loss", "hours_per_week", "native_country",
"income_bracket"
]
接下來,會使用轉變資料欄位,在 tf 2.0裡面,tf.feature 這個api,可以用來定義資料轉換。 相當於之前的 tf.contrib 裡面的一些api。 tf.feature_column 這個api下。
Ex : 使用 tf.feature_column.categorical_column_with_vocabulary_list
gender = tf.feature_column.categorical_column_with_vocabulary_list(
"gender", ["Female", "Male"])
或者說用hash bucket轉化類別型資料
occupation = tf.feature_column.categorical_column_with_hash_bucket(
"occupation", hash_bucket_size=1000)
而像前面所提到的Cross featuce transform就可以直接使用這個api
crossed_columns = [
tf.feature_column.crossed_column(
["education", "occupation"], hash_bucket_size=1000),
tf.feature_column.crossed_column(
[age_buckets, "education", "occupation"], hash_bucket_size=1000),
tf.feature_column.crossed_column(
["native_country", "occupation"], hash_bucket_size=1000)
]
另外,看一些 tf 1.X 的 api 的時候,若在 tf 2.0 找不到,可以去找 tf.compat.v1下面找 , Ex : tf.compat.v1.estimator.inputs.pandas_input_fn
接下來我們使用 tensorflow 裡面的api來定義training function
def build_estimator(model_dir, model_type):
"""Build an estimator."""
if model_type == "wide":
m = tf.estimator.LinearClassifier(
model_dir=model_dir, feature_columns=base_columns + crossed_columns)
elif model_type == "deep":
m = tf.estimator.DNNClassifier(
model_dir=model_dir,
feature_columns=deep_columns,
hidden_units=[100, 50])
else:
m = tf.estimator.DNNLinearCombinedClassifier(
model_dir=model_dir,
linear_feature_columns=crossed_columns,
dnn_feature_columns=deep_columns,
dnn_hidden_units=[100, 50])
return m
最後就可以直接 train 跟 Evaluatue了
m = build_estimator(model, model_type='wide_n_deep')
train_and_eval('/content/model','wide_n_deep',10,False,False)
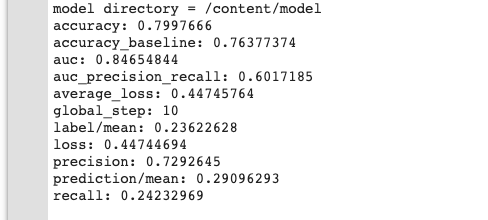
針對推薦系統,Google後來又要推出一個進階版本 Cross and Deep大家可以參考。此外,其實現今有需多推薦系統大家可以參考使用像是 DeepFM (Wide 取代成 Factorization Machines) 也都有不錯的效果。在這邊推薦一個 Python的套件DeepCTR 這個套件實作了很多相關的演算法。拿來做performance的測試是一個不錯的方式。
此外今天Keras作者出了一個 Colab的 tutorial 比較 tf 2.0 跟 tf 1.X 大家可以參考看看。


