
進入遊戲區體驗Fairness的機器學習,將會練習之前所說的不同的差異以及用子組合,來評估模型性能。
(本篇分成兩章文章)
資料:用成人普查收入數據集(Adult Census Income dataset),該數據集常常在機器學習文獻中使用。該數據是Ronny Kohavi和Barry Becker從1994年人口普查局數據庫中提取的。
目標:預測一年可以一個人賺超過5萬美金
首先要載入我們需要的module:
import os
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
import tensorflow as tf
import tempfile
!pip install seaborn==0.8.1
import seaborn as sns
import itertools
from sklearn.metrics import confusion_matrix
from sklearn.metrics import roc_curve, roc_auc_score
from sklearn.metrics import precision_recall_curve
from google.colab import widgets
# For facets
from IPython.core.display import display, HTML
import base64
!pip install facets-overview==1.0.0
from facets_overview.feature_statistics_generator import FeatureStatisticsGenerator
載入完畢的話會顯示:Requirement already satisfied: xxx(版號)以及Modules are imported.的字樣。
接著就是要使用我們的資料集-Adult Census Income dataset:
COLUMNS = ["age", "workclass", "fnlwgt", "education", "education_num",
"marital_status", "occupation", "relationship", "race", "gender",
"capital_gain", "capital_loss", "hours_per_week", "native_country",
"income_bracket"]
train_df = pd.read_csv(
"https://archive.ics.uci.edu/ml/machine-learning-databases/adult/adult.data",
names=COLUMNS,
sep=r'\s*,\s*',
engine='python',
na_values="?")
test_df = pd.read_csv(
"https://archive.ics.uci.edu/ml/machine-learning-databases/adult/adult.test",
names=COLUMNS,
sep=r'\s*,\s*',
skiprows=[0],
engine='python',
na_values="?")
# Drop rows with missing values
train_df = train_df.dropna(how="any", axis=0)
test_df = test_df.dropna(how="any", axis=0)
我們可以使用FACETS,
#@title Visualize the Data in Facets
fsg = FeatureStatisticsGenerator()
dataframes = [
{'table': train_df, 'name': 'trainData'}]
censusProto = fsg.ProtoFromDataFrames(dataframes)
protostr = base64.b64encode(censusProto.SerializeToString()).decode("utf-8")
HTML_TEMPLATE = """<script src="https://cdnjs.cloudflare.com/ajax/libs/webcomponentsjs/1.3.3/webcomponents-lite.js"></script>
<link rel="import" href="https://raw.githubusercontent.com/PAIR-code/facets/1.0.0/facets-dist/facets-jupyter.html">
<facets-overview id="elem"></facets-overview>
<script>
document.querySelector("#elem").protoInput = "{protostr}";
</script>"""
html = HTML_TEMPLATE.format(protostr=protostr)
display(HTML(html))
以用圖型化的上觀察是否資料集能使用,本次案例會得到這樣的圖型: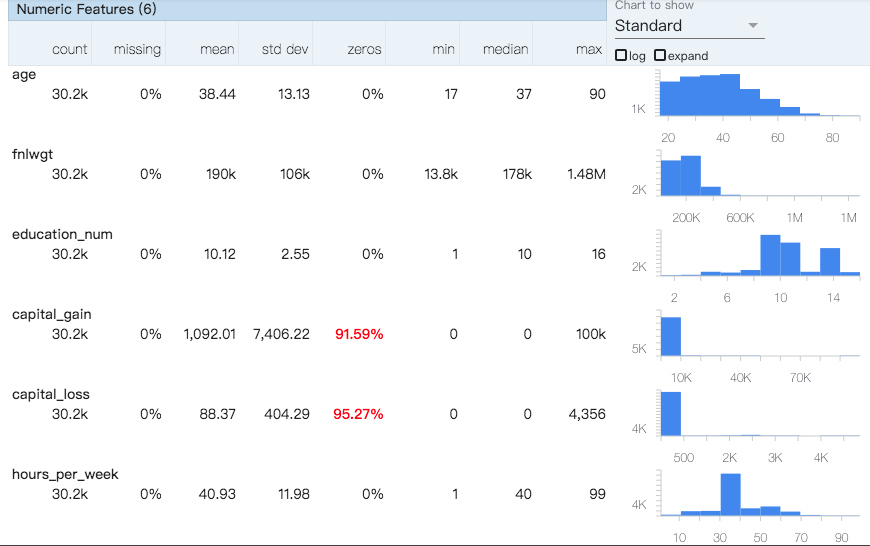
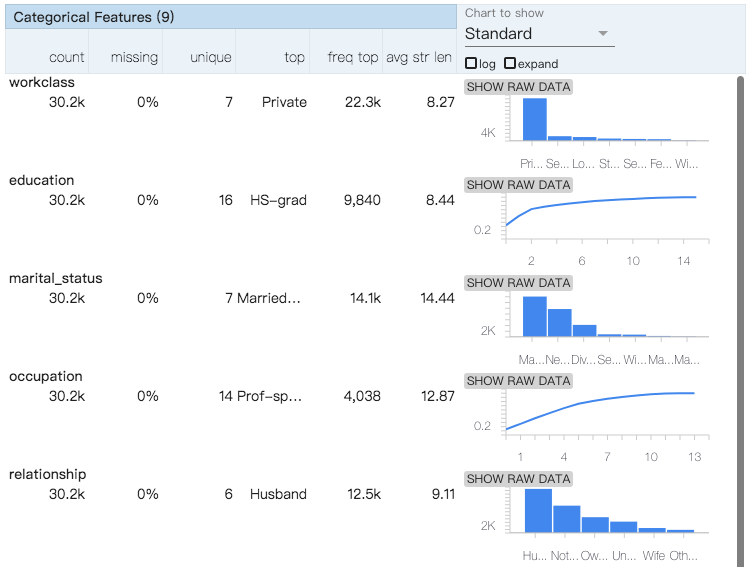
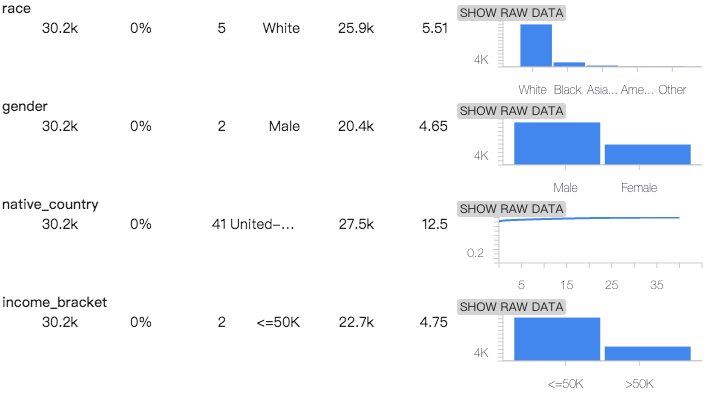
所以知道:
前置作業完成,接著下一回,可以玩Colab~

 iThome鐵人賽
iThome鐵人賽