在介紹布林模型(Boolean Model)之前我們要先定義一個名詞為Index term。每篇文章都由一些index term或是關鍵字(keywords)所組成的。而每一個Index term是由一個詞(word)或一群連續詞(word)所組成。
布林模型(Boolean Model)於1973年提出,它是一個最簡單的檢索模型主要基於幾何理論 (set theory) 和布林代數(Boolean algebra)。中心思想是把所有文章建立成Index term by document的矩陣,透過布林(Boolean)運算可以計算出哪幾篇文章是使用者所想要的。
假設今天有一群文章
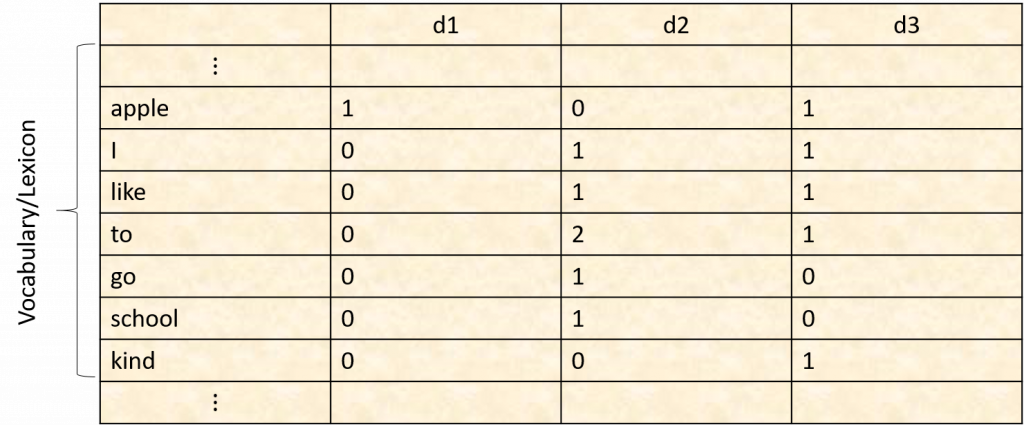
首先,我先建立一個Index term by document的矩陣。其中列(row)表示所有文章出現過的term,行(column)表示每篇文章在這裡總共有三篇文章。
若下一個query為school,則school=[0 1 0],answer=。
若下一個query為"school" and "go",則school^go=[0 1 0]^[0 1 0]=[0 1 0],answer=。
若下一個query為"apple" or "apple",則apple or school=[1 0 1] or [0 1 0]=[1 1 1],answer=&
&
今天介紹了最早使用的檢索模型布林模型(Boolean Model)並做優缺點分析。明天會介紹比較複雜一些的機率模型 (Probabilistic Model)給各位

