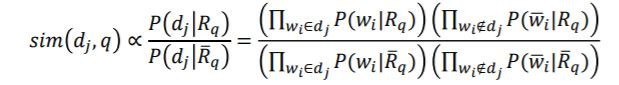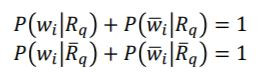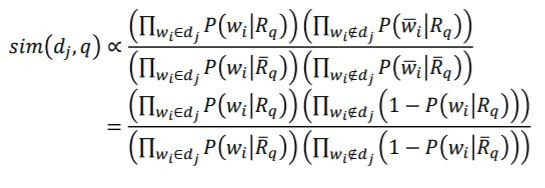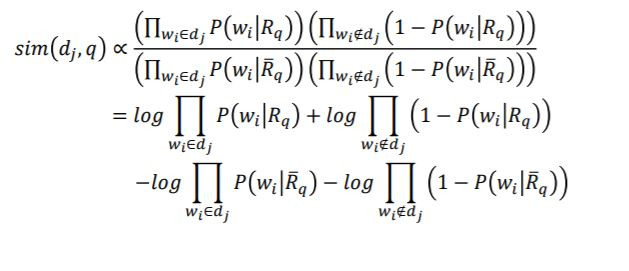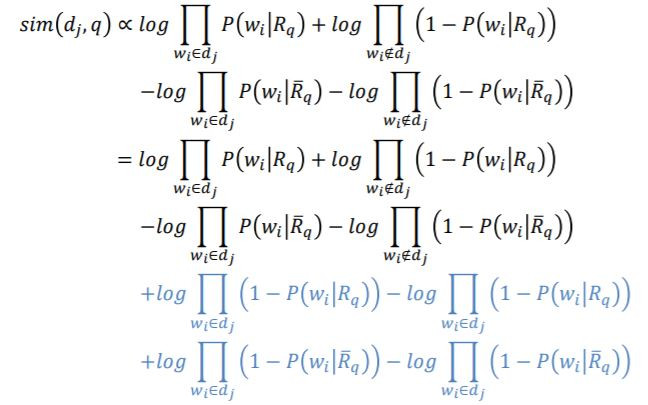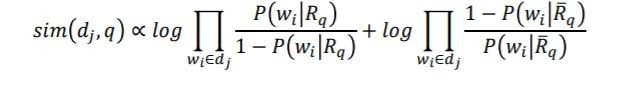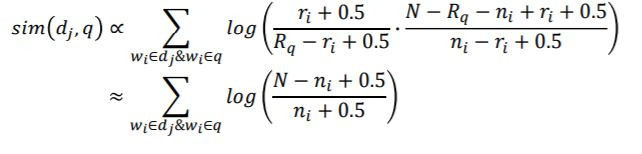第 12 屆 iThome 鐵人賽
分享至
機率模式 (Probabilistic Model) 為1976年由Roberston和Sparck Jones所提出的,它以機率的架構來解資訊檢索問題,嘗試計算文章和使用者問題的相關性機率值表示為:
假設
感謝分享。這很適合用在我的21點遊戲網站
IT邦幫忙
 。
。