資料集來自Kaggle網站,該網站主要由企業或研究者將資料集PO到該平台,資料由資料科學的愛好者進行建模、分析、預測並將結果進行競賽並獲得獎金,在2017年被谷哥大神買下,所以資料集都是合法並真實。
資料及下載位置https://drive.google.com/file/d/1_CQ9F0Iwkd-XBF5O4QmoN4SK9kAqKFg4/view?usp=sharing
本次的資料集是店商網站女鞋的相關資訊,先用Execl開啟來看一下
看到都暈了!還是先關起開R比較實在,並將資料集導入至R,並觀看資料結構
library(ggplot2)
library(dplyr)
shoes <- read.csv("D:/工作區/我的筆記/程式筆記/R/Ironman Challenge/shoes/7210_1.csv",
stringsAsFactors=FALSE,
sep=",",encoding="UTF-8",na.strings=NA,fill=TRUE)
str(shoes)
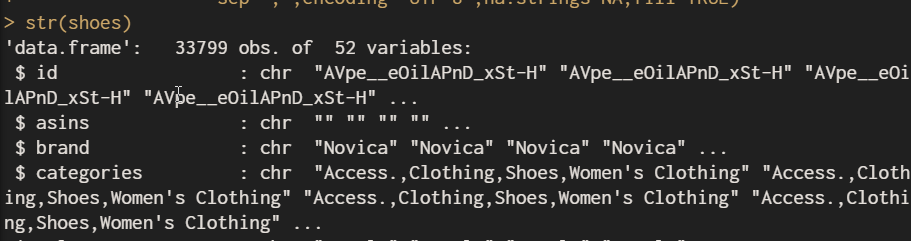
可以看到該資料集有33,799筆資料52個變數,以及變數的資料型態,看一下資料表
View(shoes)
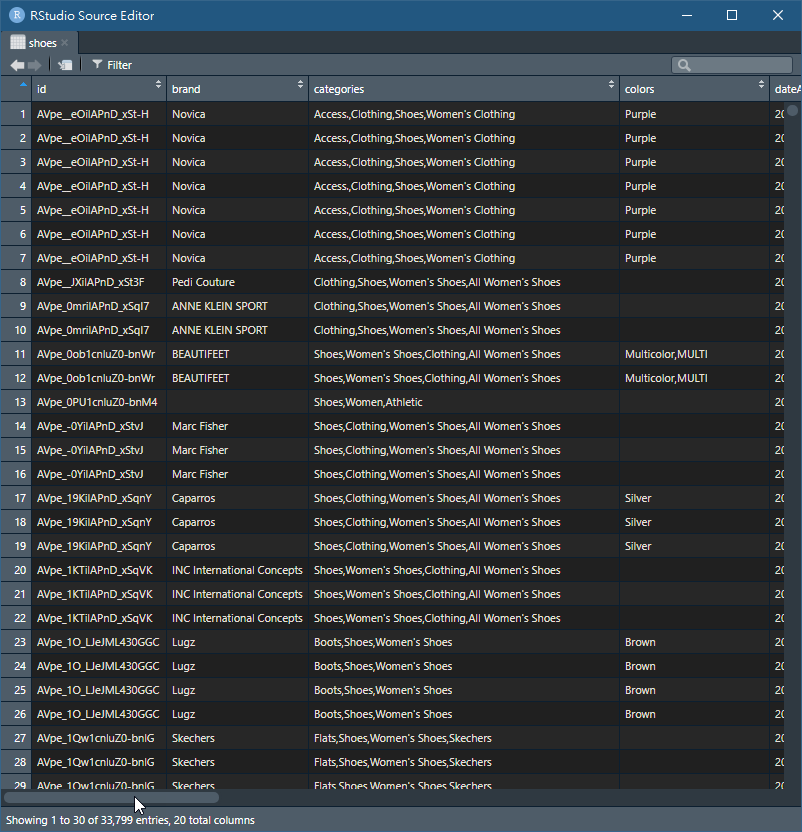
看起來舒服多了!順便研究哪一些變數可以刪除,而本次的刪除原則如下
1.與本分析毫無相關欄位如條碼、產品影像路徑、功能目錄等等。
2.需要其他資料集關聯才能分析的欄位刪除。
3.變數內幾乎都是空值沒有分析的意義
shoes <- shoes[,-c(2,6,9:16,18:20,23:24,26,28:30,32:35,37:41,43:50)]
此時觀看資料表,發現後面有x2和x3變數,判斷應該將資料匯R中自動產生,當然也是刪除
shoes <- shoes[,-c(15:16)]
str(shoes)
View(shoes)

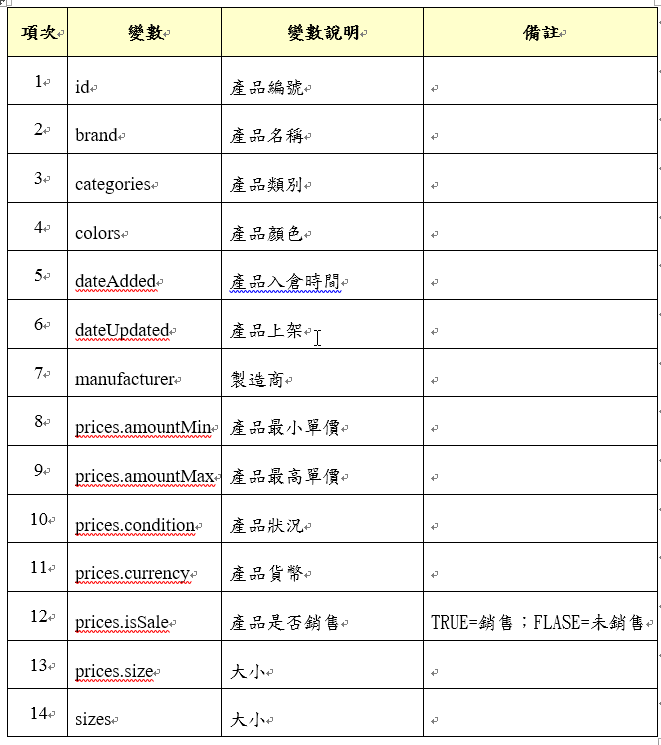
所以目前有14個變數,刪除變數在資料探勘中稱之為降維,若你的維度太大會造成計算的成本增加及影響模型的準確度,當然如何刪除變數是依據你的分析需求而定,而目前的預測模型的語言都會建議你選擇變數的套件,這是題外話了!所以我們將這14個變數整理如下表