上一篇中進行資料的降維後,現在來看列也就是筆數,看筆數中有甚麼不妥之處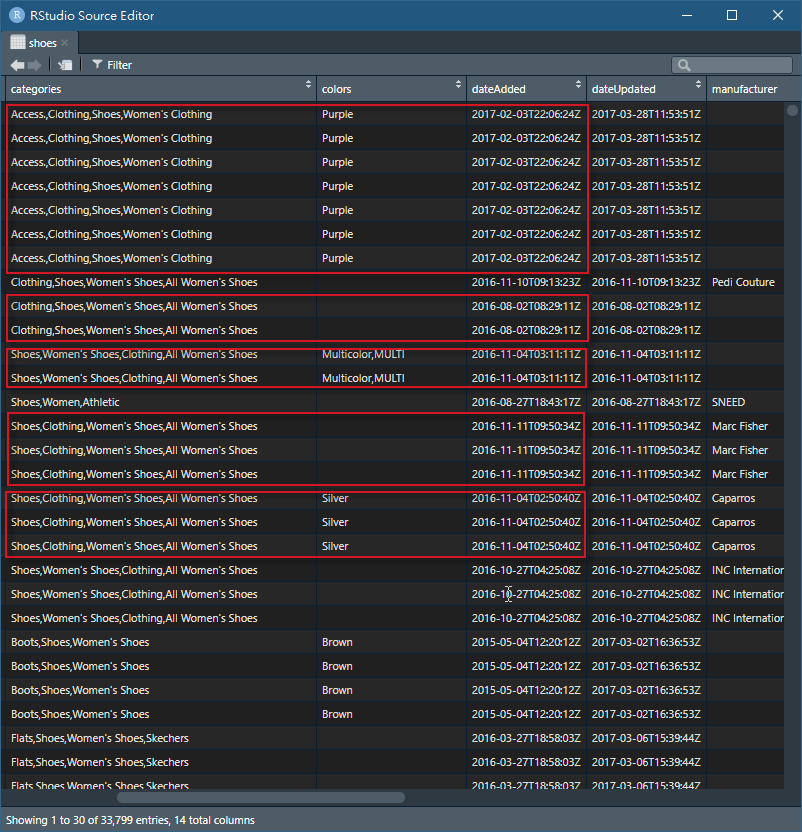
我們看到紅框dateAdded可謂進貨時間,而時間到秒換言之,不可能進貨時間到秒都一樣,可合理推論3萬3千多筆的資料有重複資料,接著再繼續觀察

上圖由標示五個紅框以下說明
1.第一個紅框我們可以看所有的筆數進貨時間、上架時間、最低價錢、最高價錢都是一樣的,所以合理推論刪除其他重複只留下一筆。
2.第二個紅框有兩組資料(也就是四筆資料),首先第一筆和第二筆進貨時間和上架時間是一樣的,但看到最低價錢和最高價錢兩筆是不一樣,第三和第四筆狀況相同,所以可能是同時間進貨但貨品不一樣,所以判定不是重複資料。
3.第三個、第四、第五個紅框都可上述一樣,進貨及上架一樣,但價錢不一樣。
所以我們可以歸納出進貨時間、上架時間、最低價錢、最高價錢,這四個欄位都相同才能判定該筆是重複資料。
很好知道規則,程式該如何寫,這是個好問題,不瞞各位為了這個問題我試過if、for、loop等判斷式,但結果只需程式碼一行即可解決,為了這一行中括號裏有括弧,括弧內有中括號,大腸包小腸,小腸裏面有蒜頭,只能用一張圖表達我的心聲
shoes_dup <- shoes[!duplicated(shoes[,5:9]),]
str(shoes_dup)
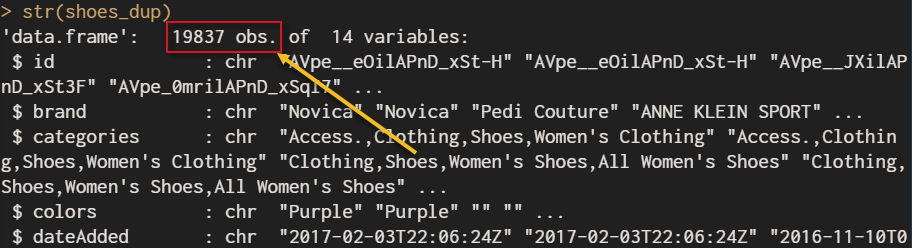
是的!本來原始資料有3萬3千多筆,經重複資料刪除有1萬9千多筆;其實當初我只看到進貨時間我就認定是重覆資料,程式碼如下
shoes_dup <- shoes[!duplicated(shoes$dateAdded),]
str(shoes_dup)
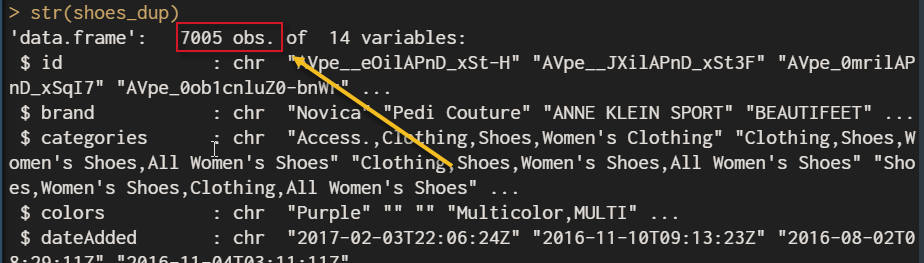
是的!你沒看錯經刪除重複資料後剩下7005筆資料,從3萬刪到7千也不是不可能只是心理覺得毛毛的,後來再觀察才發現前面各位看到紅框的判斷,才會作了不同判斷式來解決,顯而易見!效果不是很好!把函式英文狠K了一遍,才出現大腸包小腸,所以人說資料清理最花時間。
看完筆數!現在看欄位內容若有NA值反而不怕,怕的是有沒有亂碼、符號、全形夾半形、全形這是最難處理,這部分我不知道R能否處理,若有大神或同好知道的話請不吝告知,造福我們這些小小碼農,幸虧這份資料集是沒有,但還是無法判斷最常見的問題,大小寫問題!因為一些詞彙字首大寫後面小寫,要不全部都大寫,而R是分大小寫所以統計分析時就會計算錯。
因為看到欄位就很細了,所以我們先將資料集縮小,就以brand欄位為主並以Nike品牌的資料先檢核,先檢查品牌名稱都是大寫NIKE、Nike、nike。
nike <- shoes_dup %>%
filter(brand == "NIKE")

所以搜尋出來NIKE有6筆、Nike有201、nike為0筆,所以我們可以判定其他品牌的名稱有相同的問題,所以將品牌名稱全部改成小寫,以方便後續的分析。
shoes_dup$brand <- tolower(shoes_dup$brand)
View(shoes_dup)