In the previous lesson we did extracting, analyzing, and translating text from images. And this time we are going to classify text into categories by using Cloud Natural Language API.
The Cloud Natural Language API lets you extract entities from text, perform sentiment and syntactic analysis, and classify text into categories. In this lesson, we'll focus on text classification. Using a database of 700+ categories, this API feature makes it easy to classify a large dataset of text.
Wow look like we are gonna handle a huge amount of data now 
Don't panic! We can do it one step at a time~
Open Google Cloud Platform ( follow the step in A Tour of Qwiklabs and Google Cloud )
Activate Cloud Shell
Like what we did in the previous lesson.
Make sure Cloud Natural Language API is enabled
Go to APIs & services in Google Cloud Platform.
Search for Cloud Natural Language API and select it.
Click Enable to enable it.
Create an API Key
Like what we did in the previous lesson.
Classify a news article
Creare a request.json with the following sample text:
{
"document":{
"type":"PLAIN_TEXT",
"content":"A Smoky Lobster Salad With a Tapa Twist. This spin on the Spanish pulpo a la gallega skips the octopus, but keeps the sea salt, olive oil, pimentón and boiled potatoes."
}
}
Send this text to the Natural Language API's classifyText method with the following curl command:
curl "https://language.googleapis.com/v1/documents:classifyText?key=${API_KEY}" \
-s -X POST -H "Content-Type: application/json" --data-binary @request.json
Here is the response: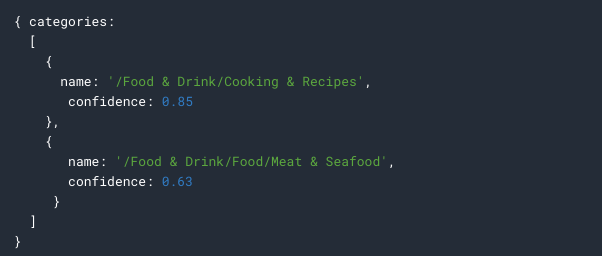
Run the following command to save the response in the result.json file:
curl "https://language.googleapis.com/v1/documents:classifyText?key=${API_KEY}" \
-s -X POST -H "Content-Type: application/json" --data-binary @request.json > result.json
6-1. Create a BigQuery table for our categorized text data
Go to BigQuery in Google Cloud Platform.
Click on the name of your project, then click Create dataset.
Name the dataset news_classification_dataset, then click Create dataset.
Click on the name of the dataset, then select Create Table.
Click Add Field and add the following 3 fields: articletext, category, and confidence.
Click Create Table.
6-2. Classify news data and storing the result in BigQuery
Run the following commands to create a service account:
gcloud iam service-accounts create my-account --display-name my-account
gcloud projects add-iam-policy-binding $PROJECT --member=serviceAccount:my-account@$PROJECT.iam.gserviceaccount.com --role=roles/bigquery.admin
gcloud iam service-accounts keys create key.json --iam-account=my-account@$PROJECT.iam.gserviceaccount.com
export GOOGLE_APPLICATION_CREDENTIALS=key.json
Create a file classify-text.py and add the following code:
from google.cloud import storage, language, bigquery
# Set up our GCS, NL, and BigQuery clients
storage_client = storage.Client()
nl_client = language.LanguageServiceClient()
# TODO: replace YOUR_PROJECT with your project name below
bq_client = bigquery.Client(project='YOUR_PROJECT')
dataset_ref = bq_client.dataset('news_classification_dataset')
dataset = bigquery.Dataset(dataset_ref)
table_ref = dataset.table('article_data')
table = bq_client.get_table(table_ref)
# Send article text to the NL API's classifyText method
def classify_text(article):
response = nl_client.classify_text(
document=language.types.Document(
content=article,
type=language.enums.Document.Type.PLAIN_TEXT
)
)
return response
rows_for_bq = []
files = storage_client.bucket('qwiklabs-test-bucket-gsp063').list_blobs()
print("Got article files from GCS, sending them to the NL API (this will take ~2 minutes)...")
# Send files to the NL API and save the result to send to BigQuery
for file in files:
if file.name.endswith('txt'):
article_text = file.download_as_string()
nl_response = classify_text(article_text)
if len(nl_response.categories) > 0:
rows_for_bq.append((str(article_text), nl_response.categories[0].name, nl_response.categories[0].confidence))
print("Writing NL API article data to BigQuery...")
# Write article text + category data to BQ
errors = bq_client.insert_rows(table, rows_for_bq)
assert errors == []
Start classifying articles and importing them to BigQuery:
python3 classify-text.py
In BigQuery, you can input SQL in Query Table and query data.
Let's try to query all the data from the articles:
SELECT * FROM `YOUR_PROJECT.news_classification_dataset.article_data`
The result will be: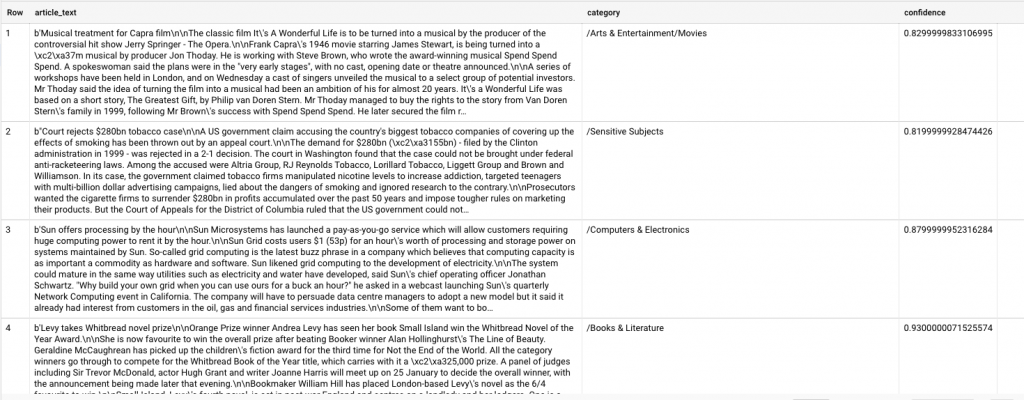
The category column has the name of the first category the Natural Language API returned for the article, and confidence is a value between 0 and 1 indicating how confident the API is that it categorized the article correctly.
Next, let's see which categories were most common in the dataset.
SELECT
category,
COUNT(*) c
FROM
`YOUR_PROJECT.news_classification_dataset.article_data`
GROUP BY
category
ORDER BY
c DESC
You will see this category /News/Politics is the most common: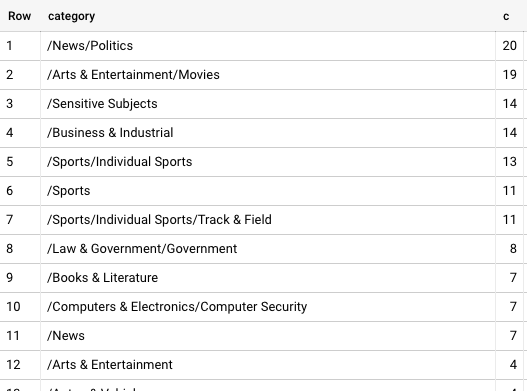
Next, let's find the article has a more obscure category like /Arts & Entertainment/Music & Audio/Classical Music:
SELECT * FROM `YOUR_PROJECT.news_classification_dataset.article_data`
WHERE category = "/Arts & Entertainment/Music & Audio/Classical Music"
There's one result for this obscure category:
Lastly, let's try to find the confidence score greater than 90%:
SELECT
article_text,
category
FROM `YOUR_PROJECT.news_classification_dataset.article_data`
WHERE cast(confidence as float64) > 0.9
These articles have confidence score greater than 90%: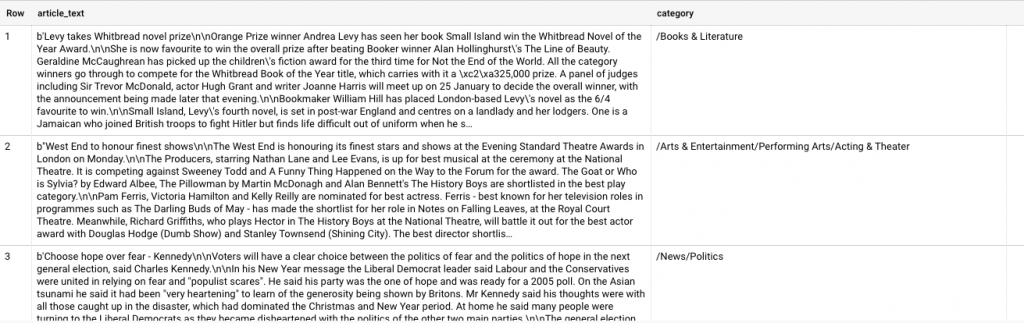
So this is how to classify text into categories and query data as desired 
Yah~ today's lesson is not so long~ 
Really appreciate how natural language has done all these tedious analyzing and categorizing works for us.
Hope you enjoy today's lesson~

