大家幾年前一定看過很多人轉傳,非常逼真但不存在的人臉圖:

—— 不存在的人臉。[1]
也一定看到很多人在玩 FaceApp 或一些軟體,能將性別轉換、變老變年輕:

—— FaceApp 將性別轉換。[2]
這些技術背後的 ML 架構正是今天的主角 —— Generative Adversarial Nets (GAN)。讓我們從 generative models 說起,以及 GAN 為什麼能有讓人驚豔的效果,還同時啟發了無數變形架構且適用在非常廣泛的場合。
接下來要介紹的東西,很多要深入理解的話,背後都有複雜的數學。我們會盡量介紹到能理解應用即可。
有別於先前介紹的 model 多半只有單一預測目標做 supervised learning,generative models 旨在學習 output 多種答案,例如"人臉"可以有無限多種可能。
那這種 generative model 具體來說的學習目標是什麼?要怎麼訓練呢?
其中一種常見做法是將 model 目標設為模擬真實 data 的 probability distribution ,並用 Maximum Likelihood Estimation (MLE) 找出 parameters
來讓 training data 的 likelihood 最大:
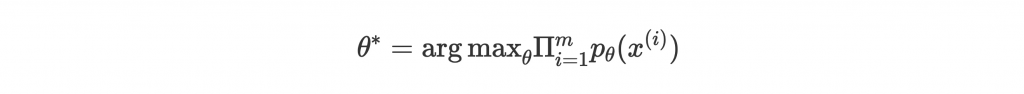
是 model 以 parameter
模擬的 data distribution,m 為 training data 的大小,
是能讓後面那項最大的
。
因為我們的目標 是真實世界所有可能 data 的分佈,但我們只會有其中一小群 m 個 sample,所以我們想模擬的其實是這 m 個 sample 的分佈
。數學上,上面 maximize likelihood 其實會等於 minimize
和
的分佈差距 KL divergence。
知道 model 目標後,接下來可以分類成很多不同的訓練方法:

—— Deep generative models 分類樹狀圖。[4]
MLE 下來分兩類:explicit density 和 implicit density。Explicit density 中,會把 density function 的實際 format 直接放在訓練中,並根據上面 MLE 的式子做 optimization。
例如在 PixelRNN 中,density function 會被分解成一連串的步驟:
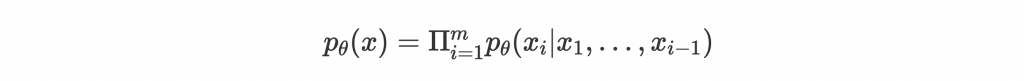
這個形式是 tractable density,也就是能用 closed-form 的形式表示,運算上比較不複雜。但缺點是要一步一步跑,算完一串步驟運算太花時間。
另一方面在 Variational Autoencoder (VAE) 中,用了不一樣的方式分解 density function:
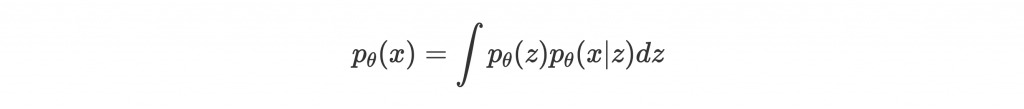
一個 autoencoder 做的事是把 input x encode 成 latent feature z,目標是讓 decoder 能根據 z decode 成原本的 input x,並用 x 和 decode 出來的 的差距當作 loss 訓練。而 VAE 因為是 generative model,要找出的是這個 latent feature z 的 probability distribution
而非單一值。
可以參考 [5] 的詳細解釋。
式子中 根據 z 預測 x 是 decoder,乘上 prior
,這部分都算 tractable。但 integration 要對所有 z 做這件事就不太實際了,因此整體來說屬於 intractable density,需要用 approximate 的方式讓他變 tractable。
簡單來說我們如果在 encoder 部分用 approximate
,那麼經過複雜數學推導 [3, p.61-70],會得到 maximize
等於 maximize 下面這個 tractible 的式子:
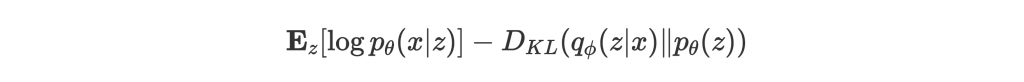
也就是訓練一個 autoencoder 讓 encoder 出來的分佈 接近 prior
,並讓 decoder 出來的結果是 input x 的 likelihood
越大越好。
雖然 VAE 用 approximation 方式解決了 PixelRNN 運算慢的問題,但實際 generate 出來的結果還是成效不佳,圖像相當模糊:

—— VAE 圖像生成結果。[3]
因為 GAN 是今天要介紹的重點,上面兩個方法就簡單介紹到這邊,有興趣可以去延伸閱讀細看 paper。接下來我們就來看一下 GAN 如何不明確使用 density function (implicity density),也能找到方法生成好的圖像。
上面我們簡單介紹了兩種從 density function 出發,學習 data 的分佈並生成圖像的方法。而本篇的主角 —— Generative Adversarial Nets (GAN),則是選擇繞過找出明確 density function 這條路,直接學習怎麼把一個 random noise 轉換成圖像。結果來說,GAN 的成效打破了其他 generative model 的 performance,也因為他有趣有彈性的架構,從提出以來一直是學術界很熱門的研究主題,也能找到很多有趣的應用。
讓我們先從架構和訓練概念介紹起吧!
前面可以看到直接企圖找出 training data 的 distribution 用來 sample 新的 data 實在太難了。GAN 決定換個方向走:隨意的產生 random noise,並透過 neural network 學習把 random noise 轉換成真的 data 的方法。
在 GAN 中,我們會先定義一個 generator G,把 random noise z 轉換成 output G(z)。但要怎麼知道生成結果 G(z) 是不是真的可以假裝是從原本的 data distribution sample 出來的呢?
為了提供訓練的 signal,GAN 中另外定義了一個 discriminator D,學習怎麼區分好與壞的結果。也就是把 G(z) 丟進 D 裡,output 出好與壞兩種結果,或更好一點,output 介於 0 和 1 的分數:越靠近 0,代表 discriminator 覺得生成結果是假的;越靠近 1,代表他覺得結果是真的。而在訓練 D 時,我們會把 G(z) 假結果跟真的 data x 都丟給 D,讓他學習判別。
Generator 訓練目標是讓 discriminator 覺得自己的生成結果是真的,也就是盡量讓 D(G(z)) 靠近 1。而 discriminator 訓練目標是駁回 generator 的結果,也就是盡量讓 D(G(z)) 靠近 0。透過這樣的 two-player game 互相學習之後,generator 的生成結果越來越能欺騙 discriminator,也就是越來越接近真實的 data 了。

—— GAN framework。G 和 D 透過 two-player game 互相學習。[4]
上圖為 two-player game 的架構。為了訓練 D 區分真的和假的結果,會給他真實 data(左)和 generator 的假結果(右)學習。而 G 會從 D 給的分數 D(G(z)) 學習。
這樣的架構形成了一個 minimax game,訓練目標是讓 D 學習 parameters 來 maximize D(x) 靠近 1 且 D(G(z)) 靠近 0 的機會:
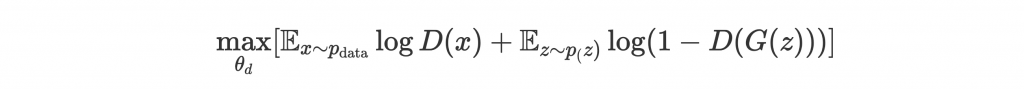
右項指 1 - D(G(z)) 越靠近 1 越好,意同 D(G(z)) 越靠近 0 越好。
反之要讓 G 學習 parameters 來 minimize D(G(z)) 靠近 0 的機會:
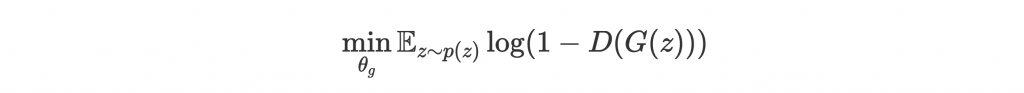
這樣 G 和 D 的訓練目標就定義完成了!
因為 log 會讓 D(G(z)) 在靠近 0 的時候,
的 gradient 太小而難以學習,所以實際上會以
來訓練 G。Minimize 某式 = maximize 某式的負值!
整個架構略顯龐大,且需要兩個 network 交互訓練。作者很貼心的提供了 pseudo-code 來讓訓練過程更清楚:

—— GAN 訓練框架。[6]
每個 iteration 中,我們先訓練 discriminator k 次。每次提供 m 個真實 data x 和假的 G(z) 做 supervised learning。讓 discriminator 先訓練,是為了提供 generator 有用的分數反饋。
接著再訓練 generator,讓生成結果 G(z) 給 discriminator 打分數並修正自己。
如此循環幾個 iteration。
成功訓練的話,兩邊的理想訓練趨勢大概是這樣:

—— GAN 交互訓練理想圖。綠線:generator 生成分佈。黑點線:真實 data 分佈。藍點線:discriminator 區分界線。黑箭頭:generator 將 random noise 轉換成 data。[6]
一開始 (a) 中 discriminator 大致能把真實 data 和假結果區隔開來。經過訓練後,(b) 中 discriminator 學會了更嚴謹的判別。接著 (c) 中訓練 generator,藉由 discriminator 的反饋,慢慢往真實分佈調整。最後達到 (d) 之後,discriminator 就再也沒有可靠訊息有效區分兩者,generator 學會生成擬真的結果。
最後來看一下 GAN 的生成結果。

—— GAN 生成四種 dataset 的圖像。最右邊是 training set 中最接近的 data,可以證明 GAN 學到的不是直接照抄。[6]
原始 GAN paper 提供的結果。Paper 比較偏理論,圖像算是實驗性質,有些模糊,但不難看出 GAN 的一些潛力。
之後很多 GAN 的變形,能生成越來越好的圖像。最簡單從改用 CNN 開始的 DCGAN:

—— DCGAN 生成假房間照片。[7]
甚至能把學到的 representation 拿來玩加減:

—— DCGAN representation 做加減:戴墨鏡的男子 - 男子 + 女子 = 戴墨鏡的女子。[7]
從 GAN 有趣的 framework 提出以後,學術界中關於 GAN 的發表開始爆炸,越來越多有的沒的 GAN 變形被提出,收羅成 The GAN Zoo。
稍微改造一下 GAN,就能做很多應用:給圖像框架提供著色、風格轉換、提升解析度、生成圖像中被遮住的部分等等。而 GAN 的概念不只能被應用在 CV 領域中,例如做 NLP 生成還能選擇 SeqGAN!
GAN 有趣又有效的架構啟發了無數 CV 界的應用,堪稱經典。下一篇要來介紹我在 CS231n 用 CycleGAN 做的 project:字型風格轉換。也是我做過最滿意的 project!


 iThome鐵人賽
iThome鐵人賽