RNN 和 CNN 兩大 model 講解完,也知道他們常分別用在 NLP 和 CV 領域中。但其實文字也有結構,運用 CNN 能幫助捕捉結構上的特徵;而圖像也有序列, 和 RNN 結合可以完成時序方面的任務。
今天就要來介紹幾個 CV x RNN、NLP x CNN 實例。
CV 跟 NLP 重疊的任務很多,所以結合 RNN 的例子滿多的,包括 image captioning、visual question answering 等等。此外 video 相關任務、手寫字順序等等也包含了時序特徵,也都可以用 RNN 捕捉時間關係。
下面分別介紹典型的 CV x RNN 任務:image captioning,以及稍微有趣一點的進階應用:visual language navigation 的架構設計。
(Xu et al. 2016) Show, Attend and Tell: Neural Image Caption Generation with Visual Attention
這篇 paper 的任務和架構都很簡單,目標是給定圖片,輸出圖片的文字描述。
架構如下:

—— Image captioning model。
首先當然用 CNN 提取圖片特徵。提取完之後的 hidden state 會進入 RNN decoder 產生一句描述。
Model 中自然也加入了 attention,因為在 decoding 的每一個輸出字都跟圖片中的不同部位有關,所以需要把注意力放在不同位置。這也是 attention 為什麼對 model interpretation 幫助很大:

—— Attention over time。上下兩排分別用了不同的 attention 機制。
這樣的架構算是早期滿典型的設計。接下來介紹有趣一點的應用。
Visual Language Navigation (VLN) 目標是讓一個機器人根據文字指令結合他所看見的世界找到下一個 action。
因此找出 action 需要三個要素:文字分析、圖像分析、和機器人本身的歷史軌跡。這個 cross-modal reasoning navigator 大致架構如下:

—— Cross-modal reasoning navigator at step t。
我們來看看裡面包含的幾個元件:
Vision encoder
最上方 vision encoder 找出當下所見的 encoding,paper 中是用了 pre-trained CNN 來 encode。
Trajectory encoder
中間綠色區塊,本身是 LSTM encoder。 是當前的 history context,是根據之前的 history context、前一步的 action、和當前所見到的 vision encode 而成的:
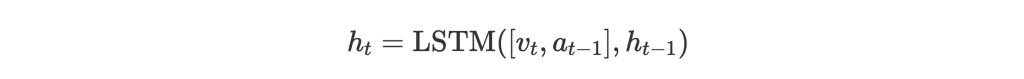
這邊 也是經過 attention 取得。
Language encoder
左邊藍色區塊,也是 LSTM encoder。
將文字 encode 後,會和 vision 經由 attention 結合成 ,來知道 vision 中的哪些地方和指令比較有關。也會和 history context 經由 attention 結合成
,知道指令中哪些文字和之前做過的事和現在看到的東西最有關。
Action predictor
中間紅色區塊的 action predictor 最後根據 、
、和
選擇最佳的動作。
除了圖像中的時序外,文字中也含有架構。比較直覺的例如中文字的結構其實跟字意相當有關係。但這邊我們介紹兩個英文任務,一個是在英文字中抓取 character-level embedding,另一個是利用 CNN 抓取句子中的局部訊息來做 classification。這兩篇中展示的也是比較常用的技巧!
(Kim et al., 2015) Character-Aware Neural Language Models
英文字雖然不像中文字有明顯結構,但其實還是有一些 pattern,最常見例如 -ly、-ing 字尾跟字意就會很有關係。這時候可以利用 CNN 來提取字根字首字尾的這些 pattern 來豐富最後的 word embedding。

—— Language model with character-level embedding。
Paper 中的 model 把字中的每個 charcter embedding 合在一起成為 matrix,並透過 convolutional layer 提取字中的局部特徵,經過幾層後,最後形成 word embedding 進入主要的 LSTM model。接下來的故事就跟一般 NLP x RNN 的 model 差不多了。
而用 character-level embedding 的好處是,parameter 量減少了 60%,但 performance 卻能表現得跟 state-of-the-art 一樣好,甚至能在 morphological-rich(形態豐富)的語言上表現得更好。
(Conneau et al., 2017) Very Deep Convolutional Networks for Text Classification
接下來介紹這篇用 CNN 做 text classification,主要是在這項任務裡,文字中的時序特徵對預測來說並不是特別重要,因此能產生跟 RNN 一樣甚至更好的效果。也因為使用 CNN,parallel computing 能讓訓練速度提升許多。
Paper 中的 model VDCNN 架構如下:

—— VDCNN 架構。
圖中的 convolutional block 是 Temp Conv - Temporal Batch Norm - ReLU - Temp Conv - Temporal Batch Norm - ReLU 的幾層 layer。
首先整個 model 也是 character-level,input 是 s 個 character,每個 character embedding 大小為 16,所以疊在一起後 input matrix 是 。
接著進入所謂 Temp Conv (Temporal Convolution),其實就是上面介紹的把 convolution 作用在 input matrix 上。因為是 convolve over temporal location 而不是 spatial location,所以稱作 temporal convolution。
之後一連串的 conv layer 提取時間和結構上的特徵。這邊每兩個 block 就 pool 一次,主要是讓 output 變成一半的大小,也就是 temporal resolution 減半,增加之後幾層每個 hidden node 的 receptive field,同時不讓運算負擔增加 [4]。而 temporal resolution 減半的同時,我們也讓學習的 feature(i.e. filter 數量)加倍。
幾層之後就會像這樣:

—— A stack of temporal convolution layers。[4]
Dilation 可以從 [5] 視覺化理解!
最後進入 fully-connected layer 做 classification 預測結果。
這樣的架構搭配 residual connection 可以訓練得很深,尤其對比較大的 dataset 訓練結果更好。也因此 paper 中用這個 model 在很多 text classification 任務上取得了超越 state-of-the-art 的成績。
(Li et al., 2019) VisualBERT: A Simple and Performant Baseline for Vision and Language
Day 14 我們介紹過 BERT,一個建立在 transformer 之上的架構。利用 BERT,我們甚至可以同時捕捉文字和圖像的種種關係。
VisualBERT 就是一個能用在 vision and language task 的 pre-trained model。他的架構大致如下:

—— VisualBERT 架構。
在 BERT 中 input 是兩個句子。而 VisualBERT 為了捕捉文字與圖像之間的關係,input 一個是句子,一個是圖像。圖像部分,主要部分會先用 object detector 偵測,取得該 bounding box 的 feature embedding,之後和先前介紹的一樣,結合 segment embedding 和 position embedding。
BERT 中訓練的兩個任務,也都變得跟 image 相關:
而 VisualBERT 也在四個 visaion and language task 中取得了持平或更好的成績,顯示 BERT 也能和 vision 結合得很好。
這篇裡我們舉了幾篇 paper 來介紹一些 CV 和 RNN、NLP 和 CNN 結合的架構,以學習文字和圖像中都會存在的結構和時序方面的關係。最後也用 VisualBERT 認識了 transformer 與文字和圖像的結合。
而這些 paper 的好結果也證明根據任務的特性思考最適合的架構,才能達到最好的效果。


 iThome鐵人賽
iThome鐵人賽