
前一篇我們快速帶過了 RL 的理論。今天我們藉由 RL 界的 Hello World —— CartPole 來認識如何實作 RL algorithm。
這篇是之前寫過的兩篇技術文的整合,有興趣可以點延伸閱讀的連結。
程式碼在 GitHub:pyliaorachel/knock-knock-deep-learning。很多都有參考其他人的 code,每個檔案上面都有標註。
RL 訓練都需要一個環境。OpenAI Gym 是一個開源的 RL 開發框架,提供數個知名專案的環境建設,包括我們今天要實作的 CartPole。其他還有 Atari、轉筆、賽車等等模擬環境,對想要上手 RL 的人是非常方便的框架。
Gym 可以從 pip install 之後 import 使用,就能從環境庫中使用設定好的環境:
import gym
env = gym.make('CartPole-v0')
環境包括以下 API:
env.render():將環境畫出來,方便從肉眼觀察訓練情況。不過會大幅降低訓練速度,如果想加速可以不用,或是 render 出來後把視窗點掉。env.observation_space:state 的設置,例如上下界等等。env.action_space:action 的設置,也提供 sample() method 可以隨機選擇 action。env.reset():重置環境,一回合重新開始。env.step(action):在環境中做出 action。會回傳 observation、rewards、done 回合結束與否、及 info 其他資訊。env.close():完成訓練後把環境完整關閉。CartPole 指的是讓小車上的柱子直立不倒的任務。

—— CartPole 環境。
Gym 提供的環境中,採用以下簡單的 formulation:
接下來介紹四種 algorithm 的實作。
首先是最簡單的 random action,可以熟悉一下 gym 怎麼使用,以及 RL 最簡易的架構。
# RL 訓練長度
N_EPISODES = 200
EPISODE_LENGTH = 200
# 建立環境
env = gym.make('CartPole-v0')
# 開始訓練
for i_episode in range(N_EPISODES):
observation = env.reset() # 把柱子擺好
rewards = 0
for t in range(EPISODE_LENGTH):
env.render()
# 隨機挑選 action,這邊是向左或向右
action = env.action_space.sample()
# 在環境中做出 action
observation, reward, done, info = env.step(action)
# 累加 reward
rewards += reward
if done: # 回合結束,可能柱子太傾斜或車子跑遠
print('Episode finished after {} timesteps, total rewards {}'.format(t+1, rewards))
break
env.close()
一個大致的 RL 訓練框架就完成了。
簡單看一下訓練過程中每回合的總 reward(柱子能撐多久):

的確像是隨機選擇,平均大概能撐 25 個 timestep。
接著就是改進挑選 action 這個動作。我們先從自己設定 policy 開始看起。
從隨機挑選 action 進階一點,我們可以自己設計簡單的 policy。例如柱子往左傾斜,我們車子就往右,反之亦然:
def choose_action(observation):
pos, v, ang, rot = observation # 車位置、車速度、柱角度、柱角速度
# 角度 < 0 選擇 action 0(車向左),否則選擇 action 0(車向右)
return 0 if ang < 0 else 1
然後把框架中隨機挑選 action 的部分改成:
action = choose_action(observation)
這樣就好啦。
來看一下效果如何:

因為沒有在學習,趨勢肯定是平的。不過平均每回合的總 reward 明顯比隨機來得好,大概能撐兩倍時間。
接下來就真的要做訓練,來讓總 reward 越來越好。
首先是 Q-table,一個 Q-learning 非常簡單的實現法。複習一下我們在前篇提到 Q-learning,是用一個 model 來 approximate Q-value function,並藉由下面的 update rule 來訓練這個 model:
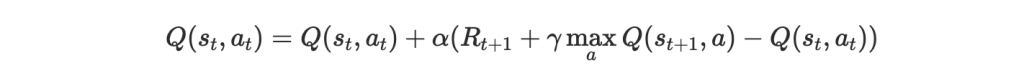
Q-table 是用 lookup table 來 approximate Q-value function,並用 Q-learning 訓練的一個方法。這個 lookup table 會將每個 state-action pair (s, a) 對應到 approximation Q(s, a),一開始 table 裡的 Q-value 隨機設置,並在訓練過程中更新這些 Q-value。所以我們其實沒有在訓練一個 model 更新參數讓預測數值更接近 Q-value,而是直接用一個 table 記錄這些值並更新。
另外我們的 state 是連續值,這樣會有無限多個可能的 state-action pair,因此我們要 discretize 這些值才能建立一個 lookup table。
例如實作中我們把 state 的 4 個 feature (position, velocity, angle, rotation rate) 分別 discretize 成 (1, 1, 6, 3) 個 bucket,6 個 bucket 就代表 angle 的範圍 [-0.5, 0.5] 被切成 6 個區間,區間中的值都對應到相同的 discrete value。
整個 discretization 大概是這樣:
# state bucket 設定
n_buckets = (1, 1, 6, 3)
# action 已經是 discrete value
n_actions = env.action_space.n
# 建立 Q-table
q_table = np.zeros(n_buckets + (n_actions,))
# 設定好每個 state feature 的上下界
state_bounds = list(zip(env.observation_space.low, env.observation_space.high))
state_bounds[1] = [-0.5, 0.5]
state_bounds[3] = [-math.radians(50), math.radians(50)]
# 將 env 給的 state 轉換成 discretized state
def get_state(observation, n_buckets, state_bounds):
state = [0] * len(observation)
for i, s in enumerate(observation):
# 每個 feature 上界、下界
l, u = state_bounds[i][0], state_bounds[i][1]
if s <= l: # 低於下界屬於第 1 個 bucket
state[i] = 0
elif s >= u: # 高於下界屬於最後一個 bucket
state[i] = n_buckets[i] - 1
else: # 其他看你在哪個區間,決定你在哪個 bucket
state[i] = int(((s - l) / (u - l)) * n_buckets[i])
return tuple(state)
再來是 -greedy 的使用,這個前一篇也有提到。選擇 action 時,有
的機率隨機選擇以增加 exploration,其他時間照著現有 policy 選擇:
def choose_action(state, q_table, action_space, epsilon):
if np.random.random_sample() < epsilon: # 隨機
return action_space.sample()
else: # 根據 Q-table 選擇最大 Q-value 的 action
return np.argmax(q_table[state])
最後就是做出 action 收集到 observation 和 reward 後,就可以 update Q-table:
# 算出下個 state
next_state = get_state(observation, n_buckets, state_bounds)
# Q-learning
q_next_max = np.amax(q_table[next_state])
q_table[state + (action,)] += lr * (reward + gamma * q_next_max - q_table[state + (action,)])
# Transition 到下個 state
state = next_state
剩下就跟前面的框架差不多了。
實作中,還另外加了一些方法讓訓練成果更好,例如因為訓練後期有比較好的 policy,讓 隨著訓練降低以減少 exploration,以及讓 learning rate 降低使訓練能收斂。
get_epsilon = lambda i: max(0.01, min(1, 1.0 - math.log10((i+1)/25)))
get_lr = lambda i: max(0.01, min(0.5, 1.0 - math.log10((i+1)/25)))
# 每回合更新 epsilon 和 lr
epsilon = get_epsilon(i_episode)
lr = get_lr(i_episode)
我們來看看成果:

我們每回合的最長時間 EPISODE_LENGTH 是 200,所以訓練到後期能達到 200 代表柱子已經能夠持續站在小車上了。
Q-table 的表現不錯,但他有個問題就是如果 state 和 action 很多,table 也會需要很多空間。用 neural network 學習預測 Q-value 的話,所需的空間就不會隨著 state 和 action 變多而劇增。
Deep Q-network (DQN) 在前一篇 Atari 的 paper 介紹過,簡單來說就是用 neural network 來預測 Q(s, a)。Input 是 state,可以是連續值,而 output 總數等於 action 的數量,CartPole 裡會是 2,每個 output 預測這個 action 未來會帶來的總 reward。
我們先定義一個簡單的 neural network,由一層 fully-connected layer 接到 output layer:
class Net(nn.Module):
def __init__(self, n_states, n_actions, n_hidden):
super(Net, self).__init__()
self.fc1 = nn.Linear(n_states, n_hidden)
self.out = nn.Linear(n_hidden, n_actions)
nn.init.xavier_normal_(self.fc1.weight)
nn.init.xavier_normal_(self.out.weight)
def forward(self, x):
x = self.fc1(x)
x = F.relu(x)
action_values = self.out(x)
return action_values
前面 paper 中提過幾個技巧,第一個是建立兩個 network,一個是實際互動的 eval net,一個是一陣子才更新一次的 target net,以避免頭追尾的情況發生。另一個技巧是 memory buffer 把和環境互動的經驗記錄起來,存到一定量再從 buffer 中提取經驗訓練。
所以我們的 DQN 大概需要:
class DQN(object):
def __init__(self, n_states, n_actions, n_hidden, batch_size, lr, epsilon, gamma, target_replace_iter, memory_capacity):
self.eval_net = Net(n_states, n_actions, n_hidden)
self.target_net = Net(n_states, n_actions, n_hidden)
self.target_replace_iter = target_replace_iter # target net 多久 update 一次
self.learn_step_counter = 0 # 現在學多久了
# memory buffer, 每一筆經驗是 (state + next state + reward + action)
self.memory = np.zeros((memory_capacity, n_states * 2 + 2))
self.memory_counter = 0 # buffer 中幾筆經驗了
# 其他訓練需要的
self.optimizer = torch.optim.Adam(self.eval_net.parameters(), lr=lr)
self.loss_func = nn.MSELoss()
...
選擇 action 也是 -greedy:
def choose_action(self, state):
x = torch.unsqueeze(torch.tensor(state, dtype=torch.float), 0)
if np.random.uniform() < self.epsilon:
action = np.random.randint(0, self.n_actions)
else:
# eval net 預測 Q-value
action_values = self.eval_net(x)
# 選 Q-value 最大的 action
action = torch.argmax(action_values).item()
return action
當 buffer 有足夠經驗,我們讓 eval net 學習:
def learn(self):
# 從 buffer 中隨機挑選經驗,將經驗分成 state、action、reward、next state
sample_index = np.random.choice(self.memory_capacity, self.batch_size)
b_memory = self.memory[sample_index, :]
b_state = torch.tensor(b_memory[:, :self.n_states], dtype=torch.float)
b_action = torch.tensor(b_memory[:, self.n_states:self.n_states+1], dtype=torch.long)
b_reward = torch.tensor(b_memory[:, self.n_states+1:self.n_states+2], dtype=torch.float)
b_next_state = torch.tensor(b_memory[:, -self.n_states:], dtype=torch.float)
# 計算 eval net 的 Q-value 和 target net 的 loss
q_eval = self.eval_net(b_state).gather(1, b_action) # 經驗當時的 Q-value
q_next = self.target_net(b_next_state).detach()
q_target = b_reward + self.gamma * q_next.max(1).values.unsqueeze(-1) # 目標 Q-value
loss = self.loss_func(q_eval, q_target)
# Backpropagation
self.optimizer.zero_grad()
loss.backward()
self.optimizer.step()
# Target network 一陣子更新一次
self.learn_step_counter += 1
if self.learn_step_counter % self.target_replace_iter == 0:
self.target_net.load_state_dict(self.eval_net.state_dict())
定義好 DQN,最後就能整合進框架了:
# 建立 DQN
dqn = DQN(n_states, n_actions, n_hidden, batch_size, lr, epsilon, gamma, target_replace_iter, memory_capacity)
...
# 用 DQN 挑選 action
action = dqn.choose_action(state)
...
# 將經驗存起來
dqn.store_transition(state, action, reward, next_state)
...
# 存到一定量開始學習
if dqn.memory_counter > memory_capacity:
dqn.learn()
接著就能開始訓練。成果如下圖:

訓練起來非常的不穩定。原本 4000 episode 以前還有在慢慢上升,突然又崩潰之後,又慢慢上升⋯⋯ 到 10000 episode 後,也沒有辦法讓柱子穩定站在車上。
從這個結果其實就知道訓練 DQN 並沒有想像中容易,而且需要很久時間才能讓 model 調適好狀態。主要原因是 reward 只要是柱子還在車上,都是 +1,也就是無論你是亂控制車子,還是真的讓車子往柱子倒的反方向平衡,reward 都是一樣的!這樣我們的 agent 怎麼會知道哪個動作合理,哪個不合理呢?
所以這邊有個能加快訓練的方法。我們作弊一下,把原本 gym 給的 reward function 加入更多資訊:
x, v, theta, omega = next_state
# reward 1: 車子越靠中間越棒
r1 = (env.x_threshold - abs(x)) / env.x_threshold - 0.8
# reward 2: 柱子越靠中間越棒
r2 = (env.theta_threshold_radians - abs(theta)) / env.theta_threshold_radians - 0.5
reward = r1 + r2
這下我們讓平衡狀態越好的情況獲得越多 reward,agent 就能更清楚知道哪些 action 會比其他 action 更好,學得也能更快了。
果然改了 reward function 後,agent 在 400 episode 就能成功學會平衡:

由此可以看出,reward function 的設計對 RL 的成效影響也是很大的!
本篇中由簡單到複雜實作了四種 algorithm 讓車子上的柱子能保持平衡。Q-table 效果不錯,能成功學會平衡,但只適用於 state 和 action 簡易的情況下。DQN 較不受限制,但訓練起來非常困難,成效不彰。不過改善 reward function 後,network 訓練中更知道如何改進,最後也成功學會讓柱子站立。
從 CartPole 認識 RL 實作的框架後,未來想要帶入自己的環境並將 RL 應用在自己的任務上就有了比較清楚的概念。
