BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
以往為了解決不同的 NLP 任務,我們會為該任務設計一個最適合的神經網路架構並做訓練。設計這些模型並測試其 performance 是非常耗費成本的(人力、時間、計算資源)。
* 如果有一個能直接處理各式 NLP 任務的通用架構該有多好?
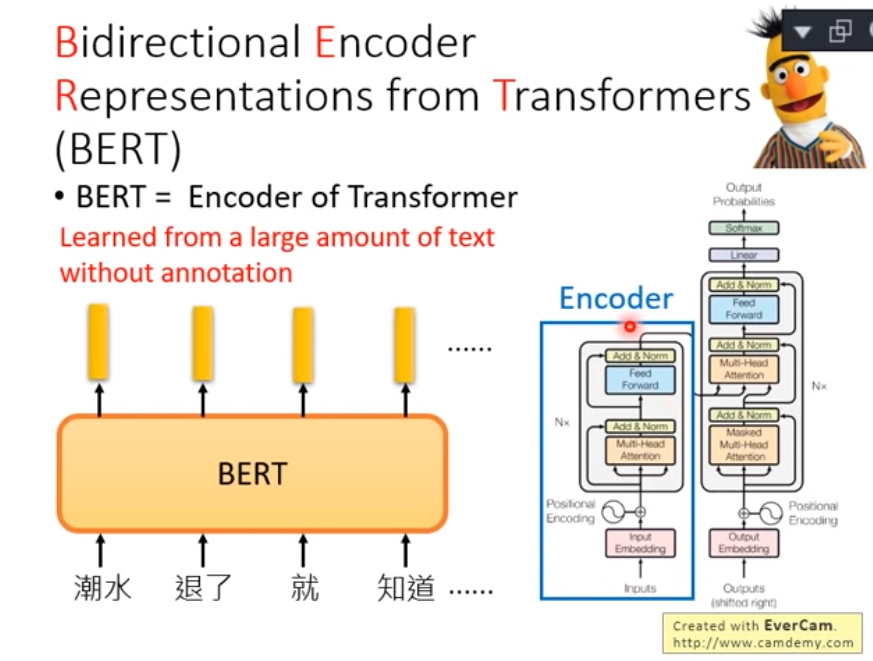
* BERT 論文的作者們使用 Transfomer Encoder、大量文本以及兩個預訓練目標,事先訓練好一個可以套用到多個 NLP 任務的 BERT 模型,再以此為基礎 fine tune 多個下游任務。
這就是近來 NLP 領域非常流行的兩階段遷移學習:
Google 在預訓練 BERT 時讓它同時進行兩個任務:
ELMo link 利用獨立訓練的雙向兩層 LSTM 做語言模型並將中間得到的隱狀態向量串接當作每個詞彙的 contextual word repr.;
GPT 則是使用 Transformer 的 Decoder 來訓練一個中規中矩、從左到右的單向語言模型。可以參考另一篇文章:直觀理解 GPT-2 語言模型並生成金庸武俠小說來深入了解 GPT 與 GPT-2。
BERT 跟它們的差異在於利用 MLM(即克漏字)的概念及 Transformer Encoder 的架構,擺脫以往語言模型只能從單個方向(由左到右或由右到左)估計下個詞彙出現機率的窘境,訓練出一個雙向的語言代表模型。這使得 BERT 輸出的每個 token 的 repr. Tn 都同時蘊含了前後文資訊,真正的雙向 representation。
跟以往模型相比,BERT 能更好地處理自然語言,在著名的問答任務 SQuAD2.0 也有卓越表現。
參考一: 進擊的BERT:NLP 界的巨人之力與遷移學習
參考二: ELMO, BERT , GPT李宏毅教授講解目前 NLP 領域的最新研究是如何讓機器讀懂文字的


 iThome鐵人賽
iThome鐵人賽