RNN 有字數限制, 最多到200字, 超過效果不好。The fall of RNN / LSTM
針對基於CNN和RNN的Seq2Seq模型(註)存在的不足,2017link 《Attention is all you need》這篇論文提出了一種完全基於Attention Mechanism(Self Attention)的Transformer架構:拋棄CNN和RNN,基於Attention來構造Encoder和Decoder ,搭建完全基於Attention的Seq2Seq模型。Attention机制详解
當我們完成實作並訓練出一個 Transformer 以後,除了可以英翻中以外,我們還能清楚地了解其是如何利用強大的注意力機制(Encoder-Decoder 模型 + 注意力機制)來做到精準且自然的翻譯。淺談神經機器翻譯 & 用 Transformer 英翻中
根據不同的任務可以選擇不同的編碼器和解碼器(可以是一個 RNN ,但通常是其變種 LSTM 或者 GRU )
具體實現 Encoder-Decoder 的時候,編碼器和解碼器都不是固定的,可選的有CNN/RNN/BiRNN/GRU/LSTM等等,你可以自由組合且各自獨立。比如說,你在編碼時使用BiRNN,解碼時使用RNN,或者在編碼時使用RNN,解碼時使用LSTM等等。
例如語言翻譯,Encoder 把輸入的句子做處理後所得到的隱狀態向量交給 Decoder 來生成目標語言。link
你可以想像兩個語義相同的法英句子雖然使用的語言、語順不一樣,但因為它們有相同的語義,Encoder 在將整個法文句子濃縮成一個嵌入空間(Embedding Space)中的向量後,Decoder 能利用隱含在該向量中的語義資訊來重新生成具有相同意涵的英文句子。
這樣的模型就像是在模擬人類做翻譯的兩個主要過程:
當然人類在做翻譯時有更多步驟、也會考慮更多東西,但 Seq2Seq 模型的表現已經很不錯了。
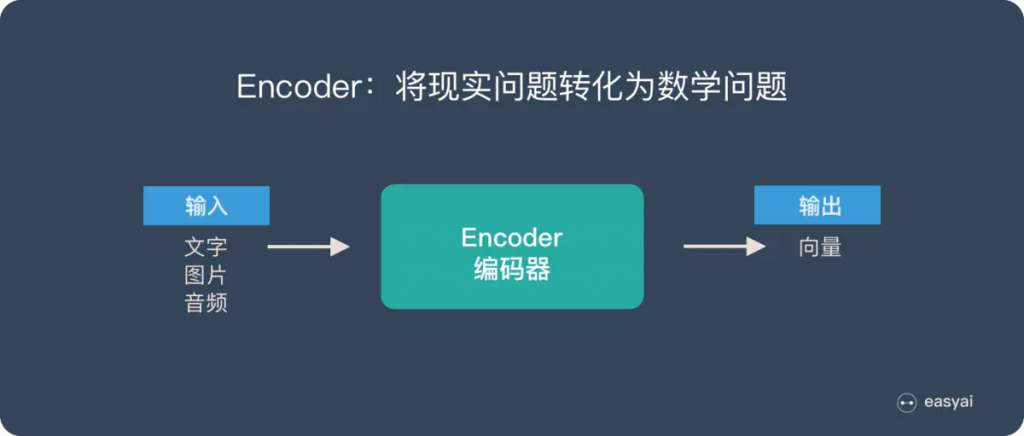
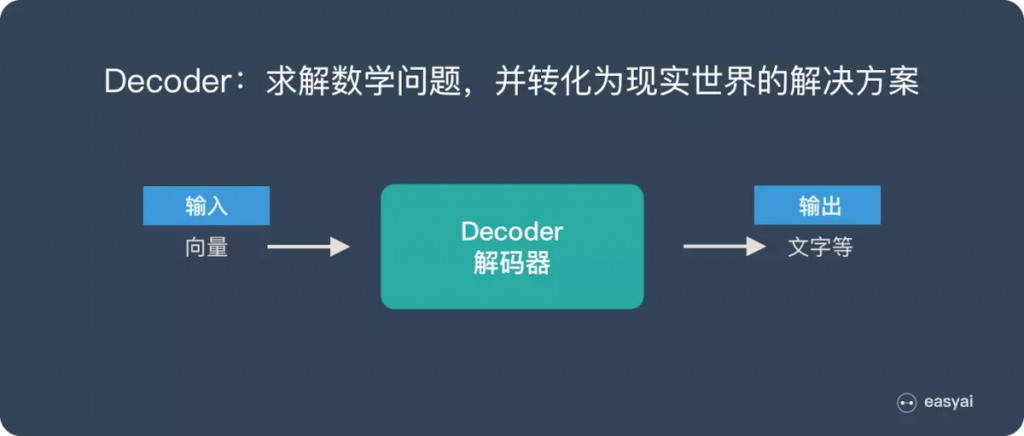
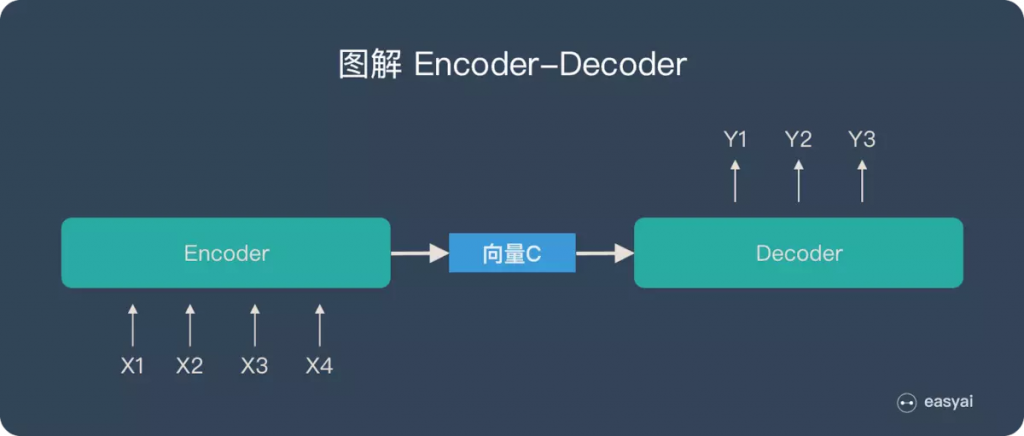
我們前面曾提過 Seq2Seq 模型裡的一個重要假設是 Encoder 能把輸入句子的語義 / 文本脈絡全都壓縮成一個固定維度的語義向量。之後 Decoder 只要利用該向量裡頭的資訊就能重新生成具有相同意義,但不同語言的句子。
但你可以想像當我們只有一個向量的時候,是不太可能把一個很長的句子的所有資訊打包起來的。
"與其只把 Encoder 處理完句子產生的最後「一個」向量交給 Decoder 並要求其從中萃取整句資訊,不如將 Encoder 在處理每個詞彙後所生成的「所有」輸出向量都交給 Decoder,讓 Decoder 自己決定在生成新序列的時候要把「注意」放在 Encoder 的哪些輸出向量上面。"
這事實上就是注意力機制(Attention Mechanism)的中心思想:提供更多資訊給 Decoder,並透過類似資料庫存取的概念,令其自行學會該怎麼提取資訊。兩篇核心論文分別在 2014 年 9 月及 2015 年 8 月釋出,概念不難但威力十分強大。
"多數以 RNN 做過的研究,都可以用自注意力機制來取代;多數用 Seq2Seq 架構實現過的應用,也都可以用 Transformer 來替換。模型訓練速度更快,結果可能更好。"
事實上只要是能用 RNN 或 Seq2Seq 模型進行的研究領域,你都會看到已經有大量跟(自)注意力機制或是 Transformer 有關的論文了:
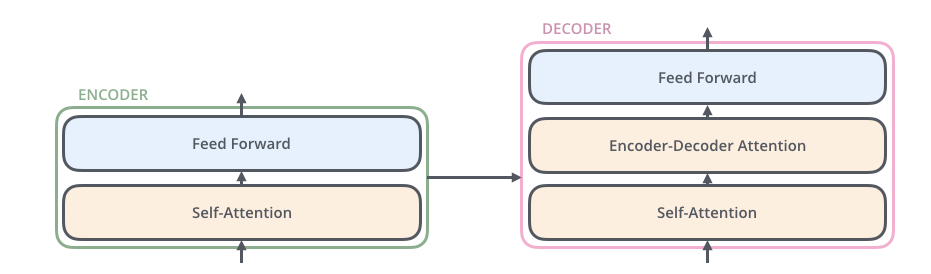
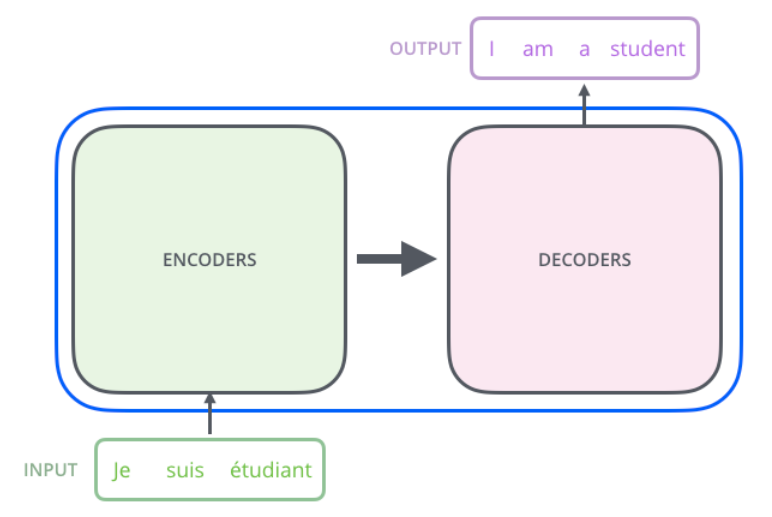
編碼組件是一堆編碼器(紙上將六個編碼器彼此疊放–六個沒有什麼神奇之處,可以嘗試其他組合)。 解碼組件是相同數量的解碼器的堆棧。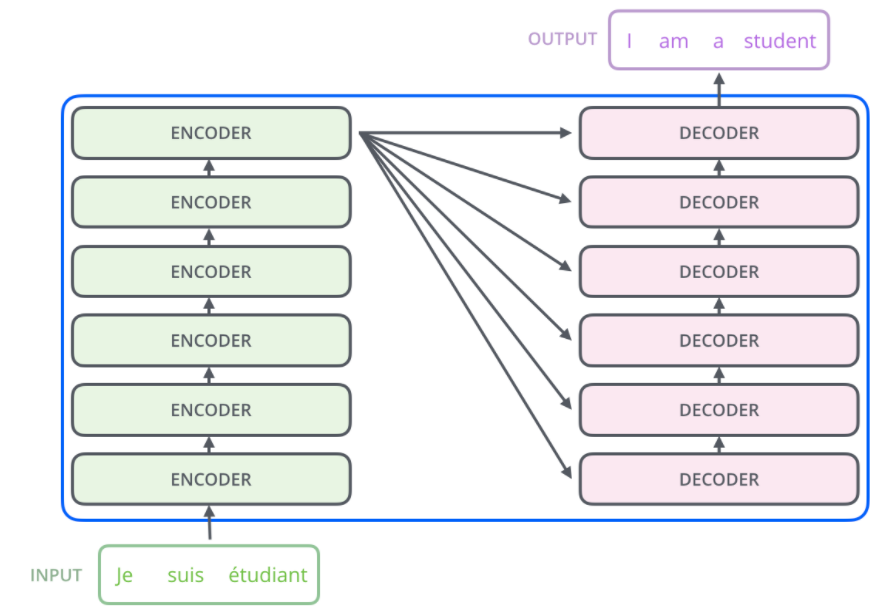
註1: 「Seq2Seq」和「Encoder-Decoder」的關係
Seq2Seq(強調目的)不特指具體方法,滿足「輸入序列、輸出序列」的目的,都可以統稱為 Seq2Seq 模型。
而 Seq2Seq 使用的具體方法基本都屬於Encoder-Decoder 模型(強調方法)的範疇。
總結一下的話:Seq2Seq 屬於 Encoder-Decoder 的大範疇
註2: Encoder-Decoder、Seq2Seq、 以及Transformer之间的关系


