再將資料丟入模型前要先做好資料前處理,並將訓練資料的答案另外獨立出來,然後把訓練資料與你獨立出來的答案丟入模型做訓練,最後再把你的測試及資料丟入訓練好的模型,就可以得到一個預測檔案。然後將預測檔案用成主辦方給你的範例樣式,最後丟到網路上去看你的分數,如下圖。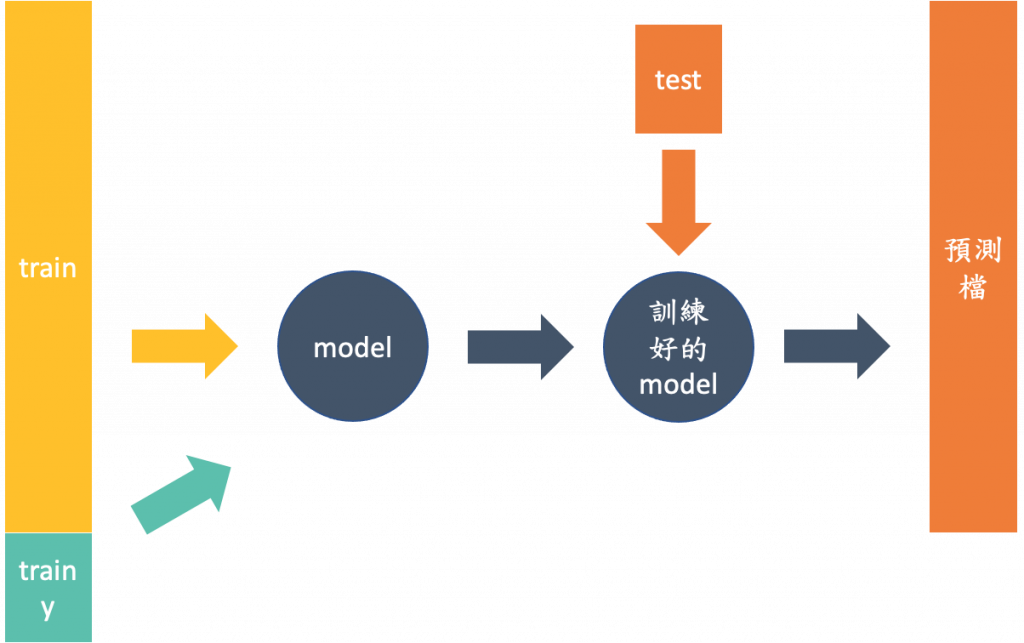
X=df_train.drop(["最高學歷","畢業學校類別","PerStatus"],axis=1)
y=df_train["PerStatus"]
X=X.fillna(-1)
df_test=df_test.fillna(-1)
#%%
df_feature_scores.reset_index(inplace=True, drop=True)
#%%
df_X=X["PerNo"]
for i in range(1,21):
df_X=pd.concat([df_X,X[df_feature_scores["Feature"][i]]], axis=1)
#%%
data_test=df_test["PerNo"]
for i in range(1,21):
data_test=pd.concat([data_test,df_test[df_feature_scores["Feature"][i]]],axis=1)
#%%丟入模型做預測
from sklearn.ensemble import RandomForestClassifier
rfc=RandomForestClassifier(n_estimators=100)
rfc_model=rfc.fit(df_X,y)
pred_test = rfc_model.predict(data_test)
#%%將預測出來的值照著主辦單位的形式做成提交檔
pred_test=pd.DataFrame(pred_test)
submit2=df_test["PerNo"]
submit2=pd.DataFrame(submit2)
submit2=pd.concat([submit2,pred_test],axis=1)
submit2.columns=["PerNo","PerStatus"]
#%%將提交檔案做儲存
submit2.to_csv("你要儲存的路徑",index=False)
X=df_train.drop(["最高學歷","畢業學校類別","PerStatus"],axis=1)
y=df_train["PerStatus"]
X=X.fillna(-1)
df_test=df_test.fillna(-1)
#%%
df_feature_scores.reset_index(inplace=True, drop=True)
#%%
df_X=X["PerNo"]
for i in range(1,21):
df_X=pd.concat([df_X,X[df_feature_scores["Feature"][i]]], axis=1)
#%%
data_test=df_test["PerNo"]
for i in range(1,21):
data_test=pd.concat([data_test,df_test[df_feature_scores["Feature"][i]]],axis=1)
#%%丟入模型做預測
from xgboost import XGBClassifier
xgbc=XGBClassifier()
xgbc_model=xgbc.fit(df_X,y)
pred_test = xgbc_model.predict(data_test)
#%%將預測出來的值照著主辦單位的形式做成提交檔
pred_test=pd.DataFrame(pred_test)
submit2=df_test["PerNo"]
submit2=pd.DataFrame(submit2)
submit2=pd.concat([submit2,pred_test],axis=1)
submit2.columns=["PerNo","PerStatus"]
#%%將提交檔案做儲存
submit2.to_csv("你要儲存的路徑",index=False)
這次的模型握最後選用XGboost,因為我將XGboost與隨機森林丟入還沒篩選特徵的資料,發現前者更為準確,因此後面做評估我都以XGboost這個模型為基準。
將資料上傳到網站上給主辦方評估成績吧
這次主辦方給我們的評估標準是F1 score,範圍介於0~1,當然越趨近於1越準確。
我做了很多嘗試,將資料分成使用onehot encoding跟未使用onehot encoding來整理給各位看
使用onehot encoding
未篩選特徵:0.2387755
使用卡方篩選特徵:0.1120689
用隨機森林篩選特徵:0.1969696
未使用onehot encoding
未篩選特徵:0.1611570
使用卡方篩選特徵:0.1262953
用隨機森林篩選特徵:0.1489971
有沒有發現做了很多但分數也一直沒進步呢?其實當初這個資料在比賽的時候,第一名的準確率也僅僅只有0.3多而已,所以不用太氣餒啦。小編0.238775的成績可是也有短暫的位居第一呢,後來隨著強者越來越多,排名也慢慢被往後面擠了,所以也要讓自己不斷進步才行。
重點是我們終於從無到有完成一個專案啦~給自己一個掌聲。花了18天終於搞懂機器學習在幹嘛了,但你們要知道小編在這18天的內容裡可是走了好多冤枉路,最後一步步拼湊才有今天的文章。所以堅持下去,你也可以在資料科學發光發熱。
明天開始我們將會來談深度學習領域,又是一個全新的世界對吧?跟著小編一起繼續探索吧!

