今天開始,我們要進入一個新的主題「Adaptation」。這是指在預訓練模型和Fine-tune之間對模型額外做一個「適應」(Adaptation)的動作,讓BERT能夠更好地過渡到下游任務的微調。這個領域如今正變得越來越大,如何更好地Adaptation,已經成為提升BERT系列模型效果的關鍵。
作為這個主題的第一篇,我們今天先簡單從概念上介紹一下預訓練模型的Adaptation有哪些可談的內容:
這個領域不太適合一般研究者來實作,畢竟預訓練一個BERT模型所花費的成本已經不是普通研究者或碩博士學生可以承擔的了。但是,我們可以選擇最新的、更合適的預訓練模型來進行我們的下游任務。對於這些模型資源,如果不善加利用,是非常可惜的。舉例而言,之前簡單介紹過用於生成的BART、用於摘要任務的PEGASUS就是這種思考下的產物。其它還有許多類似的模型,之後我們會專門來介紹,我最近發現的QA預訓練模型Splinter就表現不錯。
不要停止你的預訓練!拿到一個預訓練好的模型之後,你可以繼續在你的下游任務文本上繼續進行預訓練,也可以在相似的領域文本上進行。將繼續預訓練後的模型拿來進行微調,已經被許多論文證明可以提升最終表現。雖然這很費功夫,也花時間和顯卡,但預訓練仍然是王道!
沒有顯卡,沒有時間繼續預訓練,怎麼辦?那就微調好了。我們不只要在下游任務上微調,我們可以在一些相似任務、相似領域的資料上進行微調。再將微調後的模型拿去做最終任務的微調。當然,除了按順序進行微調,你也可以選擇進行多任務同時進行的微調。雖然參數比較難調,但具有提升模型效果的能力。
Promoting/Prefix-Tuning是最近興起的方法,它的初衷來自於讓下游任務更像預訓練任務。而現在,各預訓練語言模型必不可少的預訓練任務是克漏字。如何把分類、QA等等任務變得更像克漏字,就是Promoting/Prefix-Tuning所做的事情。例如說原本我們將電影評論進行序列分類,判斷其蘊含的情感取向。現在我們可以把它改成去挖空猜字。例如:
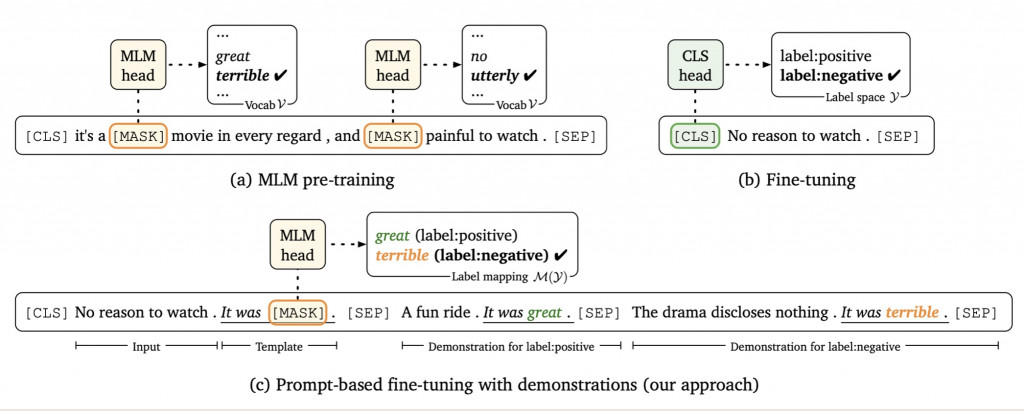
讓下游任務更接近預訓練任務,其效果可能相當於幾百個標註文本。讓模型少了一些改動,還引入了一些額外的資訊,對於最終效果都很有幫助。

