BERT系列的預訓練模型一個個出,RoBERTa、XLNet、DeBERTa等等一個比一個更能打,刷新著自然語言理解的GLUE榜單。這些都是通用型的預訓練語言模型,在所有任務上都有較好的表現(或至少相較之前的SOTA)。但是在具體完成任務時,我們的目標通常相對單純,往往不需要一個全能的模型,只要能完成我的特定類型任務就好,例如很常見的QA任務。
那麼有沒有什麼專門為了特定任務而預訓練的模型呢?今天就介紹一個剛發佈不久的Splinter模型,專為QA而生,效果優於RoBERTa、SpanBERT等之前的SOTA,在小樣本的訓練上更是特別優秀。
Splinter的貢獻主要有兩點:
其中第一點是重點,也是它成功的原因。主要思想是去模擬人們在進行問題回答時的思考方式。
通常面對一個閱讀理解的問答問題是,我們最先會閱讀題目,然後在頭腦中記住問題中出現的一些重要短語。例如一個問題是「伊麗莎白女王進入過哪所大學就讀?」這個題目中的「伊麗莎白女王」、「大學」、「就讀」、「進入」都有可能成為我們記住的重要短語。然後,我們會帶著這樣的問題去看文章,迅速找到包含這些重要短語的片段。然後再在這些短語「附近」尋找問題的答案。
也就是說,我們其實經過了一個「問題」->「拆解」->「短語」->「檢索」->「片段」->「答案」的過程。Splinter提出的預訓練任務正是在模擬這個過程中的短語檢索過程:

左邊的圖是原始文檔,右邊則是送入Splinter進行預訓練時的文檔,經過了段落MASK。哪些段落被MASK起來成為[QUESTION],讓模型去猜呢?是那些在文本中重複出現的片段被隨機MASK了,但會留下一個片段讓模型能夠去選擇。模型的學習目標就是透過上下文去重新定位到被MASK起來的文本是什麼。這部分Splinter的作法與傳統BERT的克漏字,完全重建被遮蓋的字詞的方式不同。Splinter是使用一個特殊的question-aware span selection (QASS) 層,只使用[QUESTION]的表示來「選擇」答案片段。這就非常相似於SQuAD等擷取式問答的工作方式。
而這個訓練好的[QUESTION] token也可以被用來進行微調。方法也很簡單,只要在問題的後面接一個[QUESTION],模型就可以做微調的工作了,例如下圖這樣。

SPlinter方法其實不難,但是巧妙,而效果則是實打實的。也不用多說,我們直接來看論文中的結果就好(根據本人親測,效果屬實)。
首先是Few shot learning,極小樣本情況下,Splinter力壓效果拔群:
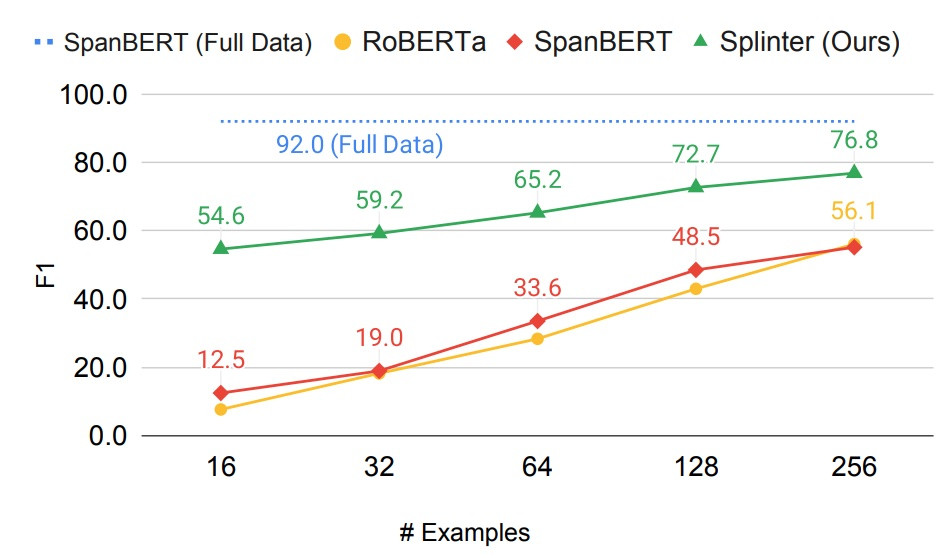
而在完整的資料集上進行Fine-tune,效果也不差:
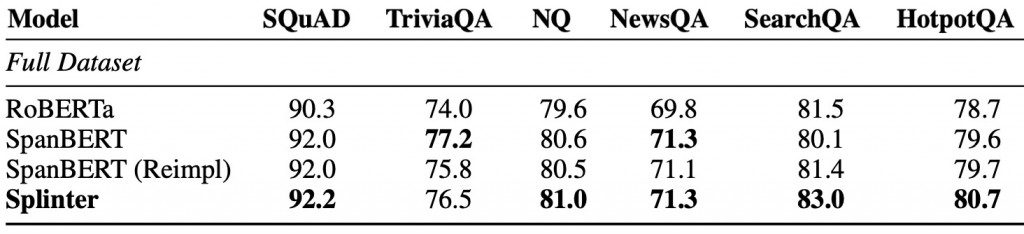
完整實驗結果可看下圖:
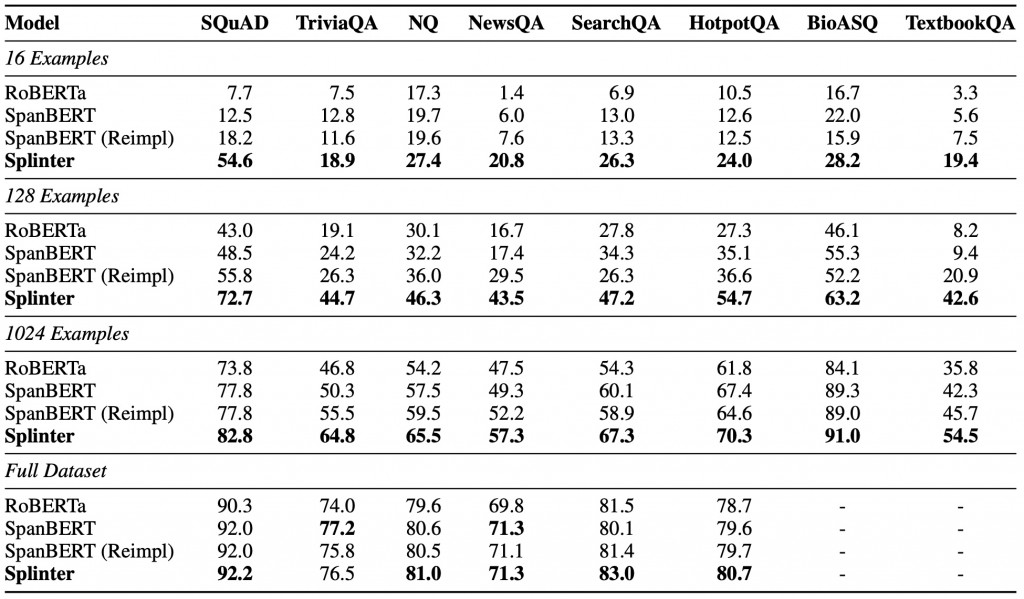
Ram, O., Kirstain, Y., Berant, J., Globerson, A., & Levy, O. (2021). Few-shot question answering by pretraining span selection. arXiv preprint arXiv:2101.00438.

