前五天,我們講解了BERT模型的核心概念、輸入輸出以及模型的類型,現在讓我們進入模型的結構、原理部分,來談一談作為BERT模型的原始架構的Transformer模型。這是BERT基本介紹的最後一部分,在此之後,我們將會更關注如何改善BERT模型的效能,如何更好地適應下游任務等等實戰技術面。
Seq2seq模型是對一類機器學習、自然語言處理模型的總稱。Transformer就屬於Seq2seq模型。Seq2seq的指稱是就模型的「功能」而言,而非對於模型結構的指稱。這裡的意思是說,Seq2seq模型是為了完成Seq2seq這個固定功能的任務而產生的模型的總稱,這種任務就是序列輸入、序列輸出。
這又是什麼意思呢?舉例來說,最常見的自然語言處理應用——自動翻譯,就是Seq2seq,也就是序列輸入(例如一串英文文本)、序列輸出(一串自動翻譯好的中文文本)。它與其他自然語言任務的差別主要在於序列的輸入和輸出長度不一定一致,兩個序列間沒有必然的對應關係。你可以想想中文、英文、日文、韓文的語序、語法其實大不相同,不可能透過一一對應的方式來完成任務。
那麼Seq2seq的任務該怎麼設計相應的模型架構呢?答案是Encoder-Decoder。
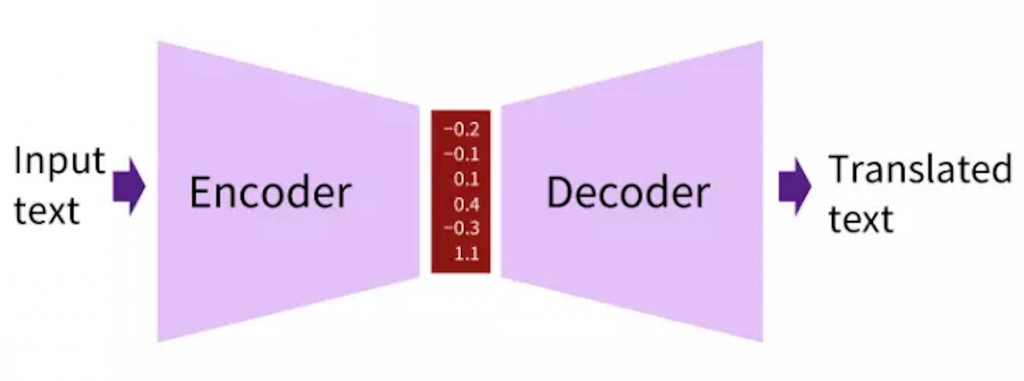
上圖就是Encoder、Decoder的想法示意圖。既然輸入序列與輸出序列長度不一致也沒有一一對應關係,那不如我們就把輸入序列用模型編碼成一些向量,然後再將這些編碼好的向量用模型解碼為輸出序列吧。這樣序列對應的問題就可以獲得解決。我們不用為了序列長度等等問題而傷腦筋。
幾乎所有類神經網路模型都可以做Encoder-Decoder這件事,所以通俗來講,只要設計成這樣的結構,能夠完成Seq2seq任務,就屬於Seq2seq模型。但通常來說,我們只會考慮那些表現比較好的模型。MLP、CNN無法處理序列的先後次序,不適合文本處理,先排除。而剩下的模型就是具備序列記憶能力的RNN家族(包括GRU、LSTM)和Transformer了。
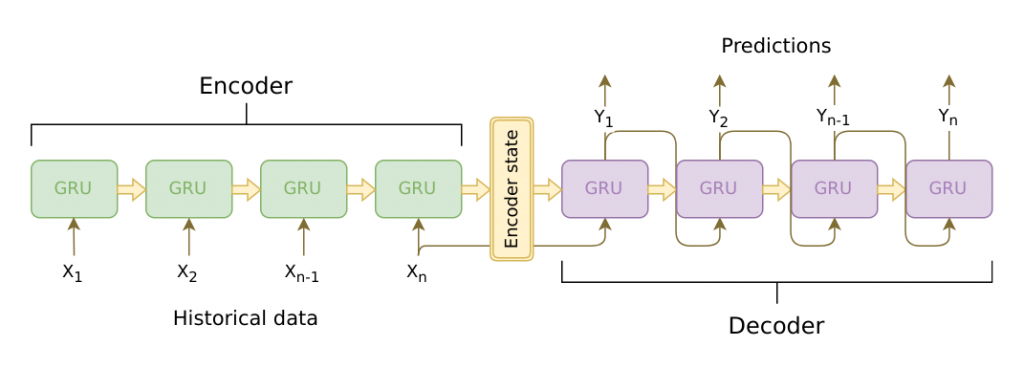
上圖是以GRU為基礎單位的Seq2seq模型。可以看到編碼的過程就是一步步輸入序列中的token進行運算,最後一個Hidden State(通常對應輸入序列的結束符號)就是編碼結果。而解碼則是從最後一個Hidden State開始一步步進行序列生成,直到生成了一個序列結束的符號。
GRU、LSTM固然可以處理Seq2seq的任務,但是實際的表現往往難以滿足應用需求。主要是因為如下幾個問題:
而能夠同時解決這兩個問題的模型就是Transformer。它的核心概念是注意力機制Attention。其實Attention並不是Transformer模型獨有的發明,在LSTM作為Seq2seq任務模型的時代,Attention就已經被引入來提升效果了(也就是解決上面說的遺忘問題)。但Transformer的另一個優點則在發佈之初是序列模型中少見的:能夠進行平行運算。這大大提升了運算速度,也讓BERT等包含巨量參數的預訓練模型成為可能。(值得一提的是,ELMO是基於LSTM的預訓練模型)
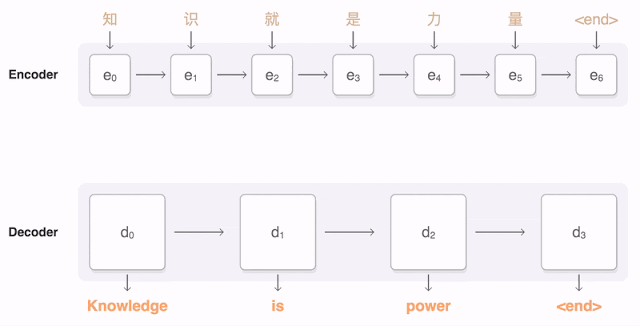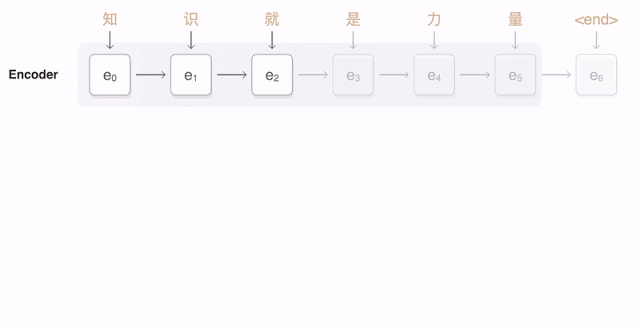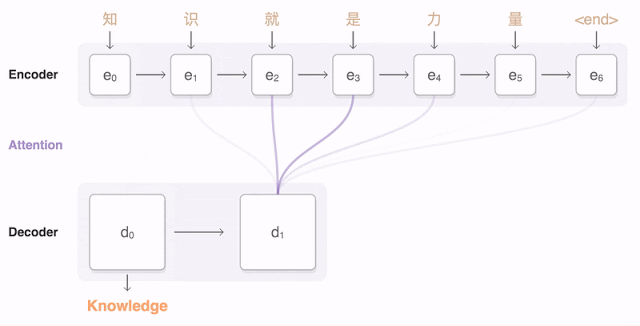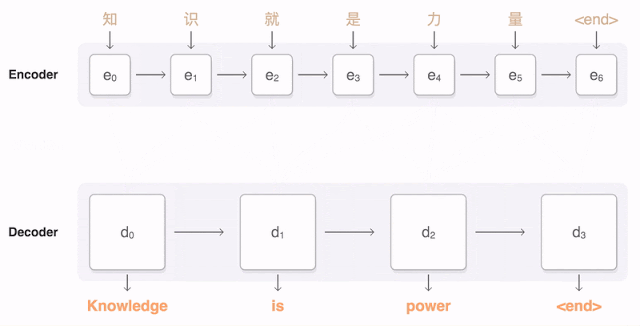
那麼,什麼是Attention(原始版本,非Transformer的)?上方是一個簡單的示意圖。簡單地說就是讓輸出序列的每一個Hidden State都與每一個Encoder部分的Hidden State做點乘,計算出注意力得分,再按得分權重反饋回Decoder部分。如果得分高,Decoder的時候就會更多考慮這個Encoder部分的資訊。這避免了編碼集中於輸入序列最後一步的問題。
而Tranformer採用了這個Decoder部分與Encoder部分相互Attention的機制,它還額外增加了一個Self Attention自注意力機制(也就是Attention的改版),徹底取代了序列回歸模型。讓LSTM等等幾乎要退出歷史舞台... 
上圖就是自注意力機制的運算過程,有興趣的話再詳細研究即可,不必完全搞懂每一步的運算細節。但要知道的是,自注意力機制的改進是將原本用在Encoder和Decoder之間的運算拿到了輸入序列自身,讓序列中的每一個Embedding都可以相互注意、採納權重,自然也就取代了LSTM的那種記憶機制。而且上方的矩陣運算是可以完全平行化處理的,這樣就解決了傳統的Seq2seq的第二個問題。
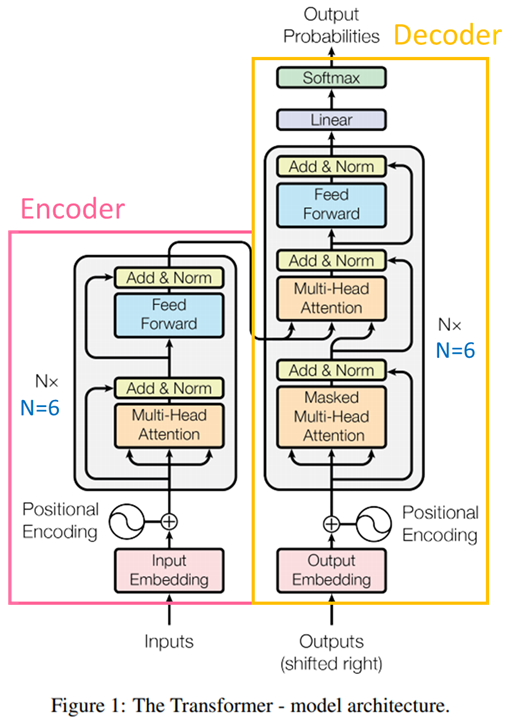
上方是Transformer的模型完整架構,已經標示出了Encoder和Decoder的範圍。其中的Multi-Head Attention就是注意力所應用的地方,而其他諸如Add & Norm、Positional Encoding等屬於工程上的處理,後續也有不同的修改(例如,BERT的Positonal Embedding與原始Transformer的就不一樣),不屬於今天重點,就不展開介紹了。
需要注意的主要是模型下方的那兩個輸入(雖然其中一個寫了Output),這可能是讓初學者困擾的地方。左邊的輸入就是輸入序列,比較好理解。右邊的輸入看上去是要輸入「輸出」,這不是矛盾了嗎?其實,右邊的輸出部分,Transformer仍然遵循Seq2seq的基本模式,也就是,將已經輸出的部分序列再重新輸入進模型,預測下一個輸出,循環往復,完成整個輸出序列。例如要輸出一句「我要去上學」,不是一句話直接完整Output,而是從一個類似<Start>的token開始依序輸出<Start>我、<Start>我要、<Start>我要去、<Start>我要去上、<Start>我要去上學、<Start>我要去上學<End>。右上角的Output Probability其實是指下一個輸出token的概率分佈。這整個過程被稱為自回歸模型。
一個基本事實:Transformer是Seq2seq模型,而Transformer是BERT模型的基本組成結構,但是BERT卻並不是Seq2seq模型。
嗯嗯?怎麼回事,聽起來怎麼像邏輯錯誤,Seq2seq的Transformer怎麼被疊了十幾層之後就不是Seq2seq了。原因是,我們通常稱BERT的基礎結構為Transformer是一種簡略的說法, 其實完整的說法是:Google-BERT由Transformer的Encoder部分組成,沒有使用Decoder部分。所以BERT自然無法單獨處理Seq2seq任務(需要額外加Decoder層)了。我們之前所介紹的下游任務中,也沒有Seq2seq的任務舉例。
但是原始版本BERT不能做,不代表BERT家族的其他成員不行。遠親的另一個預訓練語言模型GPT,就是完全用Transformer的Decoder部分進行預訓練的。所以GPT系列難以進行自然語言理解,卻在生成任務上打遍天下無敵手。那有沒有辦法結合BERT與GPT?乾脆用類似完整Transformer的架構進行預訓練呢?當然也有,這個模型叫做BART。既能充分理解輸入序列,同時也可以生成目標序列。在一些需要情境的生成任務中尤其好用(例如生成式摘要、翻譯)。


 iThome鐵人賽
iThome鐵人賽