恭喜,BERT模型的基礎部分已經講解到昨日為止了,接下來我們來談一些質疑、檢討、改進基礎BERT的內容。今天我們來講解一個頗有爭議的問題:[CLS]是否真的能代表句義或文義?
[CLS]為什麼能被用來代表句義?要理解這個問題,最重要的是先知道[CLS]所對應的Embedding被使用來代表句義的原理。為什麼選擇它而不是其他任何一個Token來代表文義?在Google的用法中,其實是因為這個Token本身不帶有任何具體意義。所以,一張白紙的[CLS]可以被用來更「公平」地表示整句話的意思。
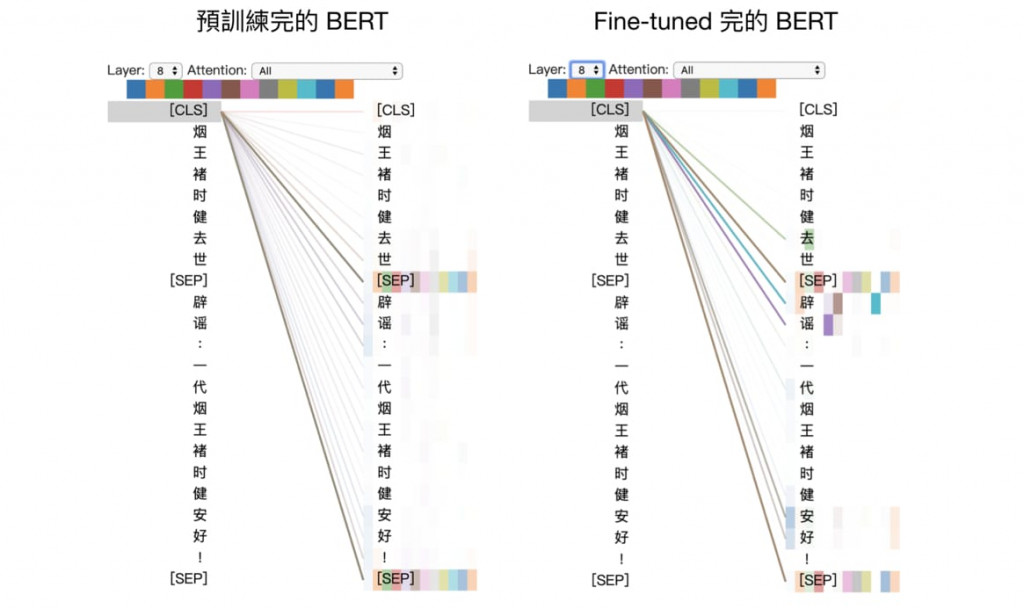
按照這樣的原理,在下游任務的Fine-tune過程中,[CLS]不斷被使用來進行文本分類,從而也慢慢學習到去Attention整句話中最適合進行分類的那些Token(如上圖所示)。等Fine-tune完成的時候,[CLS]就會成為一個句義地良好表示。
但是要注意了,上述原理有一個大前提,就是一定要進行Fine-tune,[CLS]才能被充分訓練到可以表示句義。而另一個問題則是,上述假設中「[CLS]本身不帶有任何具體意義」是有問題的。因為在預訓練階段的NSP(下一句預測)任務中,[CLS]也是被拿來進行句子是否相接續的預測,所以即使未進行Fine-tune,[CLS]本身就已經包含了原有的語料中的基於下一句預測的句義表達。
上述部分,在大多數應用情境中不會出現問題。[CLS]可以進行良好的句義表示,但這不代表[CLS]的效果是最佳的。而且,如果Fine-tune階段資料量太少,或甚至無法進行Fine-tune的應用情境,用[CLS]來當作句義就有很大問題了。
[CLS],我們還有其他方式表達句義嗎?當然有。每一個Token的Embedding其實都是用來進行句義表示的好資源。但問題是我們如何將每個Token的Embedding來轉化成整個序列的Embedding,這個過程稱為聚合(Aggregation)。
簡單的方法包括取每個維度(在同一個模型的情況下,各Embedding的維度數量是一致的)的平均值或最大值。複雜一點的方法,你可以加一個CNN或LSTM在這些Embedding之後專門用於聚合。這些方法的效果如何呢?已經有人做過相應的實驗了。
Hyunjin Choi等韓國三星的研究者在文本相似的任務上進行過一系列實驗,他們嘗試了未Fine-tune和Fine-tune情況下使用[CLS]、平均Token Embedding的表現以及後接CNN進行聚合的表現。在此之外,他們額外還使用了一個名為Siamese network structure的方式來進行模型訓練,此方式與我們一般將兩個句子中間加[SEP]進行連接一起送入句子進行訓練的方式不同,是同時讓兩個句子分別進入模型得出Embedding後再採用平均Token Embedding或接CNN的方式計算空間距離。下面是該結構的示意圖。
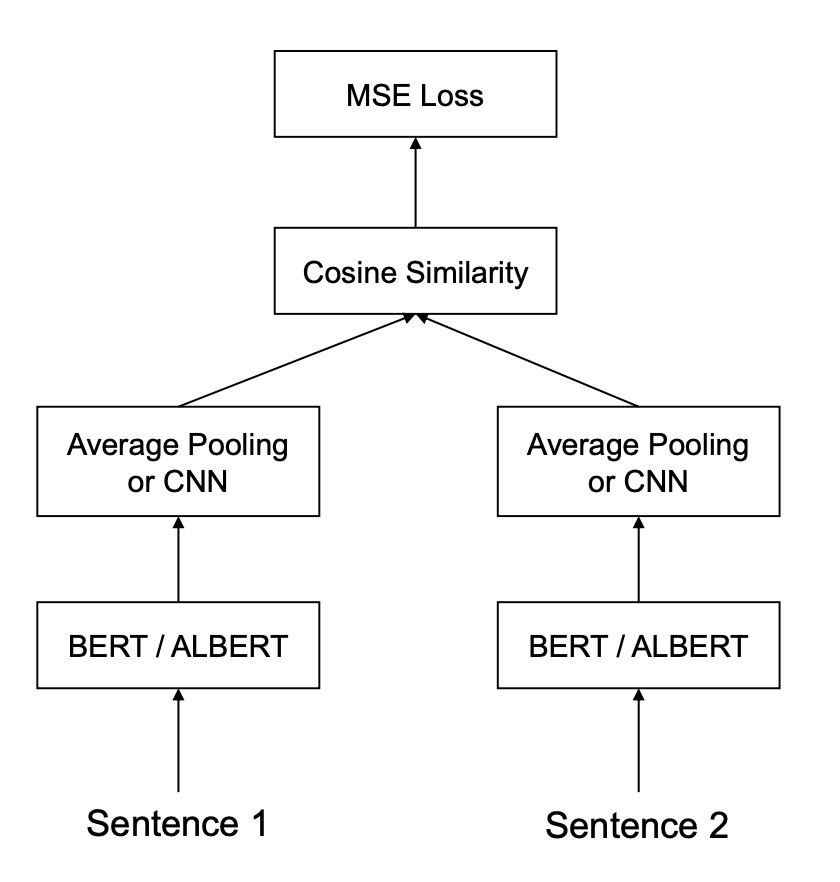
而結果如何呢?簡單地說,[CLS]是效果最差的那位,平均Token Embedding效果還不錯,Siamese BERT情況下的平均Token Embedding效果第二名,第一是Siamese BERT + CNN的組合。
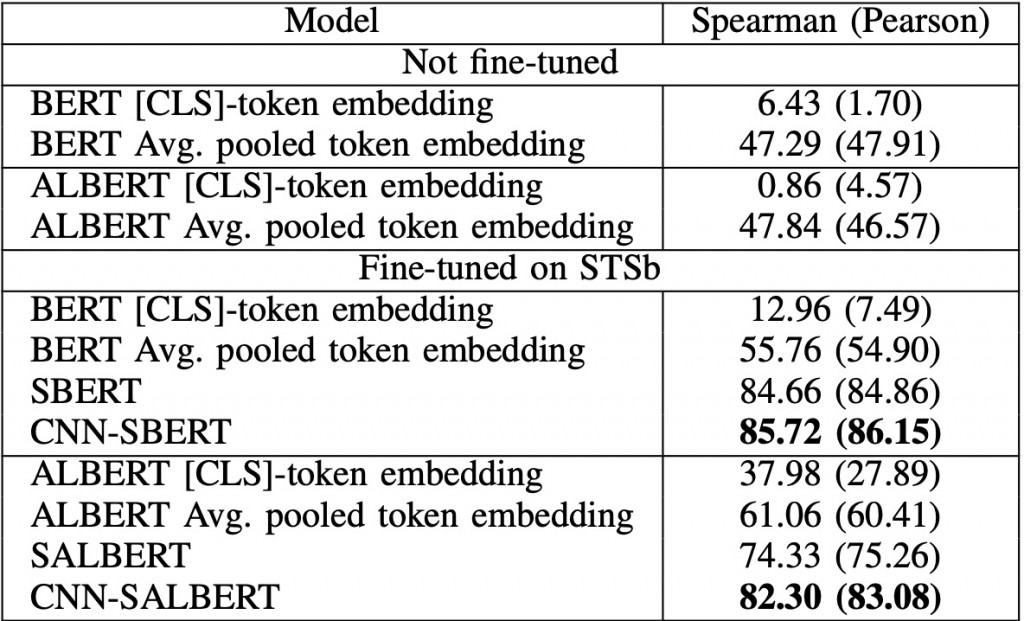
雖然我有點懷疑,[CLS]的效果是否真的有這麼差(尤其是Fine-tune之後),會不會是實驗者並沒有給使用[CLS]的方式一個適當的超參數呢?但無論如何,關於[CLS]的使用的確已經引起了許多討論,以後你在進行有關句義表達的任務時,不妨嘗試看看上面說的其他方法。
Choi, H., Kim, J., Joe, S., & Gwon, Y. (2021, January). Evaluation of BERT and ALBERT Sentence Embedding Performance on Downstream NLP Tasks. In 2020 25th International Conference on Pattern Recognition (ICPR) (pp. 5482-5487). IEEE.


 iThome鐵人賽
iThome鐵人賽