當本系列文章提到BERT時,最初是指Google所開發的BERT,但後續基本就是指所有運用Transformer和預訓練模式的語言模型。今天這篇文章就是在廣義的基礎上帶大家認識BERT這個越來越龐大的家族。只有瞭解不同模型的差異,我們才可以在實際應用中更有效地使用於下游任務。
以下,我們從三個不同的層次來認識BERT家族,分別是參數量、預訓練語料、預訓練任務/模型結構:
同樣的任務、同樣的基礎模型結構,也可以堆出不一樣的模型。這可以被理解為模型的「型號」,就像桌子有大中小一樣,BERT系列模型往往都會有大中小(甚至超大、超超大)等不同的模型版本。這其中的差異就是參數量,小模型參數量少,大模型參數量大。
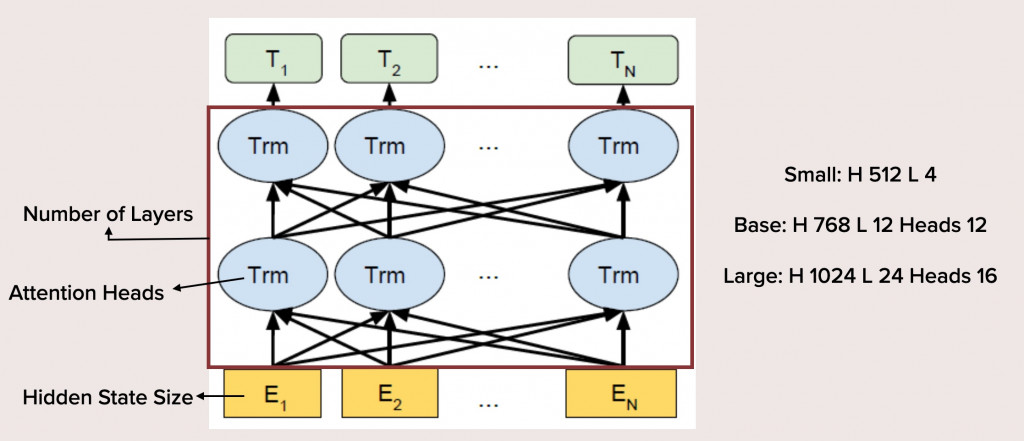
參數量如何能夠有所差異呢?
這主要是三個方面的影響:
模型的參數量多寡的影響是非常直觀的:大模型所包含的資訊更多,訓練起來更困難,但理論上的效果會更好。而小模型更容易使用、訓練,甚至可以裝在一些嵌入式硬體中。前兩年不少研究都關注於如何蒸餾預訓練模型,即在儘量不傷害模型的效果的前提下減少參數量。
BERT的預訓練文本是維基百科、一個不公開的書本資料集和網路爬蟲所獲得的文本。這些都屬於一般領域的文本。他們可以在大多數自然語言處理任務上獲得良好的結果,但並不意味著效果「最好」,在一些特殊領域可能表現也不佳。最理想的方式是根據任務所在的領域尋找對應、相關或至少近似的語料進行預訓練,這樣模型能更多習得領域知識,在下游任務上也會有更好的表現。
例如雖然Google有釋出多語言BERT,但各國的研究者仍傾向使用自己語言所預訓練出的BERT。在中文領域,這方面做得最好的是哈工大/訊飛實驗室,他們釋出了一系列中文的BERT模型,我實際使用過,效果頗佳。
除了語言之外,專業領域也常常用來進行不同語料的預訓練。例如生物醫學是一個專門的NLP應用領域,BioBERT、PubMedBERT、BlueBERT等等都是專門用於生物醫學下游任務的BERT,它們通常在生醫論文、臨床文本資料上進行預訓練。除此之外,還有法律BERT、社群媒體BERT(例如Twitter語料訓練出的BERTweet)等等有待開發。
預訓練任務與模型結構通常是分不開的,更改預訓練任務的同時也會相應修改模型結構,但核心想法仍然是預訓練任務。BERT的預訓練任務為「克漏字」和「下一句預測」。改善預訓練任務通常有兩個方向,一個是純粹工程上的改善,另一個是為了讓預訓練任務更契合下游的特殊任務。
工程上的改善最著名的是RoBERTa,這是FB的研究者在BERT基礎上改進、重新預訓練所獲得的效果更好的BERT版本。有人認為RoBERTa才是真正的BERT,Google所開發的只是一個未完成的版本。他們的改善包括對下一句預測這個任務的修正。研究者發現此任務太過於簡單,往往讓模型太早學會,反而不利於獲得比較好的嵌入。也包括對於預訓練階段的文本長度、Batch Size的調整等等,經過了大量實驗和訓練技巧的運用,終於獲得一個效果出色的模型。
另一個方向則是覺得BERT的初始預訓練任務太「難用」,它們與實際上要進行的下游任務有差別,造成了實際效果的不佳。所以思路就是將模型的預訓練任務修改為更接近下游任務的。這個方面的研究最近也取得了出色的進展,例如將GPT的文本生成任務融入BERT中的BART和PEGASUS就能在生成式摘要任務中取得不錯的效果,而最近也有人針對QA任務提出了更好的預訓練任務Splinter。
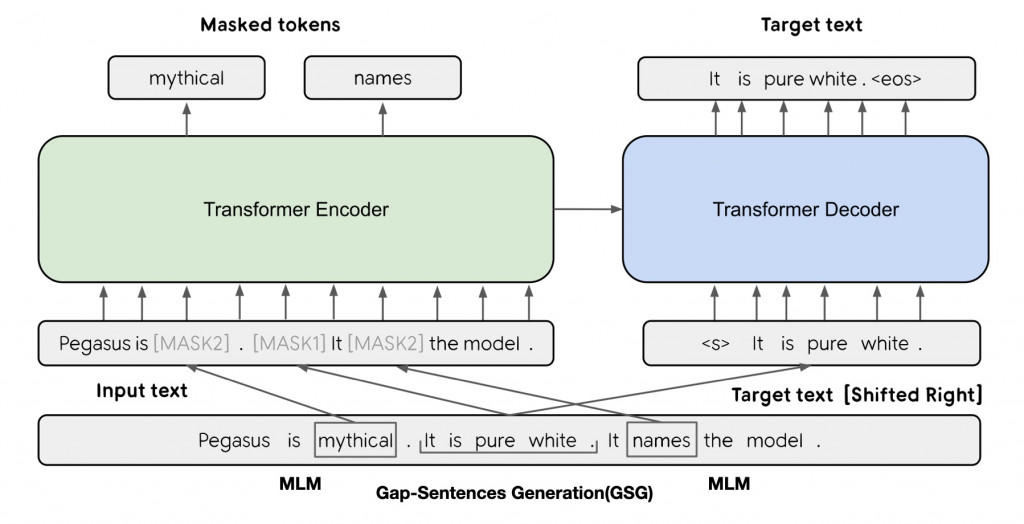
上方就是PEGASUS的預訓練任務的架構,可以看到圖中左半邊仍然是傳統BERT的克漏字任務,但右半邊則是PEGASUS獨創的文本重建任務,這是一種自回歸式的文本序列生成。自回歸指的是文本的生成是按照順序一個個進行的,後面的新生成文本會參考已經生成的部分繼續生成。這樣的預訓練任務讓PEGASUS學會了在特定情境下生成文本,從而更接近下游的摘要任務。

