複習一下我們之前提到的觀念,想要有一個好的預測模型,擁有一個好的資料集是一件很重要的事,因此我們在做資料分析時會把大部分的時間花在資料處理上面,做影像辨識時也不例外,擁有良好特徵的圖片,或是足夠的訓練數據,對模型學習的狀況也會有所幫助,今天就要來介紹兩種常見實用的圖片處理方法。
不知道大家對這個詞是否熟悉,是的,我們在前面介紹機器學習的特徵工程時有提到過,資料正規化是指將原始資料的數據按比例縮放於 [0, 1] 區間中,且不會改變其原本的分佈,我們在進行影像辨識時,我們在進行圖像預處理時,也會習慣將像素值縮放到[0,1]之間(即除以255),作法也是相當簡單。
import cv2
img = cv2.imread("husky.jpg")
img
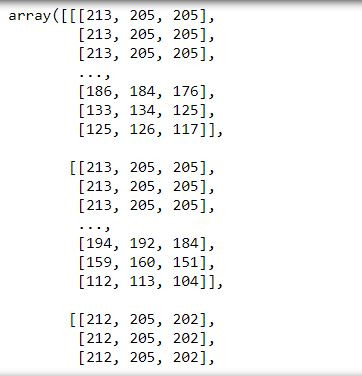
img=img/255.0
img

非常簡單的步驟我們就可以將影像實施正規化,當然實務上我們要處理的影像不會只有一張,也有很多套件支援資料正規化的功能,我們等到後面在做介紹。
資料增強(Data Augmentation)較常用在影像處理上,我們在做機器學習的時候有提到資料不平衡的問題,影像辨識當然也會遇到,有時候我們手上的某個種類的圖片很少,或是整份資料其實都不太夠時,我們的神經網路會很難去學習,這時候我們就會使用資料增強的方法來"增加"我們手邊的資料。
我們利用一些物理手法,像是將圖片翻轉、平移、調整明暗度、調整比例尺吋後會得到一張新的圖形,對我們人類來說這是一張一樣的圖,但對機器來說就是一張新的圖像,資料增強就是透過對現有資料的變形,創造出更多的資料讓我們做訓練。
圖片來源:https://towardsdatascience.com/machinex-image-data-augmentation-using-keras-b459ef87cd22
我們要利用Keras這個套件來幫助我們完成資料增強,在使用前記得要先安裝Keras套件,2.5版本的Tensorflow已經有支援Keras,就不必另外安裝Keras。
conda install tensorflow==2.5.0
我們要使用的是Keras中的ImageDataGenerator這個功能,程式碼範例如下:
from tensorflow.keras.preprocessing.image import ImageDataGenerator
datagen=
ImageDataGenerator(featurewise_center=False,
samplewise_center=False,
featurewise_std_normalization=False,
samplewise_std_normalization=False,
zca_whitening=False,
zca_epsilon=1e-6,
rotation_range=0.,
width_shift_range=0.,
height_shift_range=0.,
shear_range=0.,
zoom_range=0.,
channel_shift_range=0.,
fill_mode='nearest',
cval=0.,
horizontal_flip=False,
vertical_flip=False,
rescale=None,
preprocessing_function=None,
data_format=K.image_data_format())
featurewise_center:去中心值,使數據集均值為0
featurewise_std_normalization:使每個輸入樣本除以自身標準差
samplewise_center:去中心值,使輸入樣本均值為0
samplewise_std_normalization:使每個輸入樣本除以自身標準差(只考慮自身圖片)
zca_whtening:一種PCA降維處理,減少圖片的冗餘信息,保留最重要的特徵
zca_epsilon:zca白話的值
rotation_range:使圖片隨機旋轉的角度,輸入一個值,演算法會使圖片在這個值區間隨機旋轉
width_shift_range:圖片水平平移的尺寸
height_shift_range:圖片垂直平移的尺寸
shear_range:隨機裁減的角度
zoom_range:隨機縮放大小
channel_shift_range:隨機改變圖片的顏色
fill_mode:圖片經處理後邊界以外的點的處理方式
horizontal_flip:隨機進行水平翻轉
vertical_flip:隨機進行垂直翻轉
rescale:對圖片的每個像素值乘上這個縮放值,可理解為圖片正規化
preprocessing_function:其他的前處理功能,可自行寫def定義或是使用套件提供的
在我們創造一個datagen後,我們要想辦法將資料集結合進來,才會達到資料增強的效果,將資料讀進來的方式一共有兩種,都是利用到Image.data.preprocessing裡頭的功能。
使用from_directory的話我們需要將不同標籤的圖片進行分類,安插在同一個資料夾下,如下圖: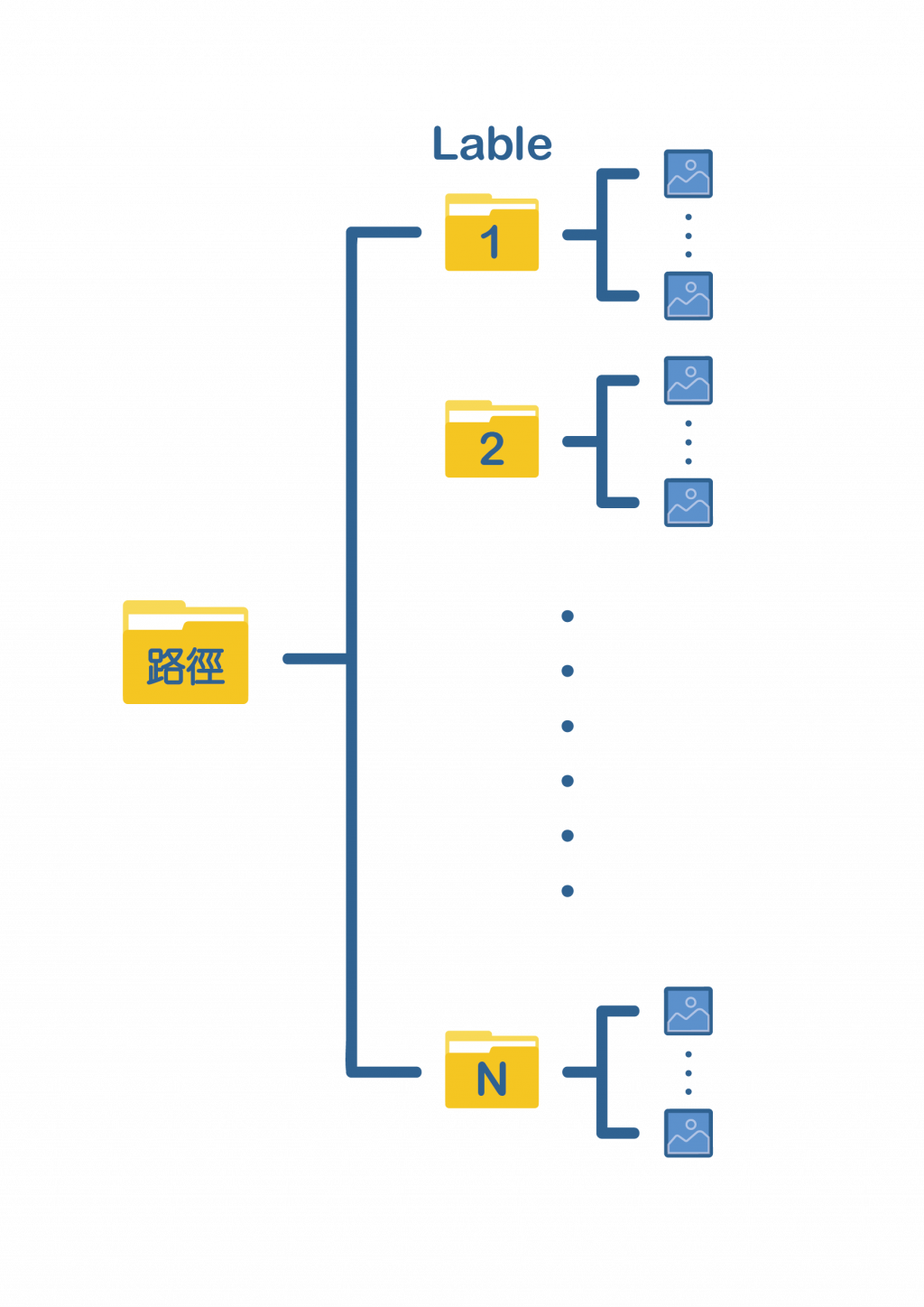
train_generator=
datagen.flow_from_dataframe(
directory,
labels="inferred",
label_mode="int",
class_names=None,
color_mode="rgb",
batch_size=32,
image_size=(256, 256),
shuffle=True,
seed=None,
validation_split=None,
subset=None,
interpolation="bilinear",
follow_links=False,
crop_to_aspect_ratio=False,
**kwargs
)
directory放置最上層資料夾的路徑,labels選擇"inferred",其餘參數像是image_size、batch_size等皆可自行調整,詳細的參數說明可至Image data preprocessing查看。
使用flow_from_dataframe可以不必將圖片分類,全部放置在一個資料夾即可,但須額為製作一份DataFrame,裡頭要包含圖片的名稱以及標籤,如下圖: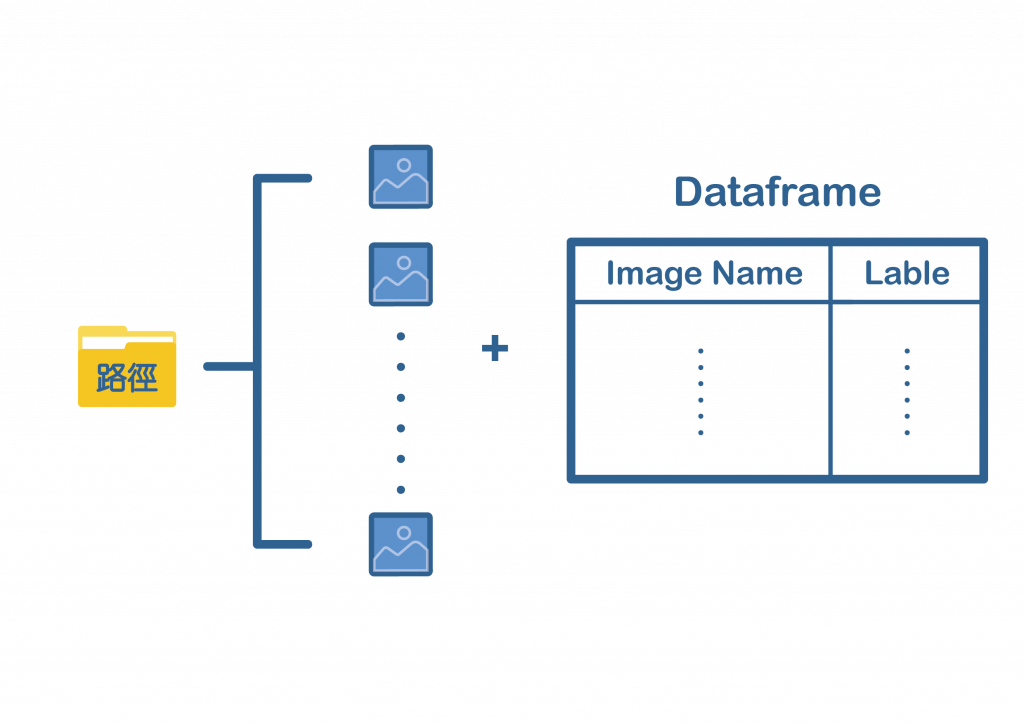
train_generator=
datagen.flow_from_dataframe(
dataframe,
directory=None,
x_col='filename',
y_col='class',
weight_col=None,
target_size=(256, 256),
color_mode='rgb',
classes=None,
class_mode='categorical',
batch_size=32,
shuffle=True,
seed=None,
save_to_dir=None,
save_prefix='',
save_format='png',
subset=None,
interpolation='nearest',
validate_filenames=True, **kwargs
)
Dataframe要放含有圖片名稱跟標籤的Dataframe,例如:
根據上面的例子,x_col要放"Image",y_col要放"Label",directory則是放所有圖片所在的資料夾路徑。
在生成train_generator後,我們就可以丟進模型訓練,這邊要注意的是不能跟平常一樣使用model.fit,而是要改用model.fit_generator。
fit_generator(
generator,
steps_per_epoch=None,
epochs=1, verbose=1,
callbacks=None,
validation_data=None,
validation_steps=None,
class_weight=None,
max_queue_size=10,
workers=1,
use_multiprocessing=False,
shuffle=True,
initial_epoch=0)
今天介紹了資料正規化以及資料增強,這些在影像辨識都是常用到的手法,非常重要也非常使用,模型的優劣很大程度的取決於我們的資料,這個觀念請大家一定要記住,希望大家都有學習到東西,再會啦~

