AFE 特徵是由歐洲電信標準協會所提出的。
AFE 論文參考連結: https://www.etsi.org/deliver/etsi_es/201100_201199/201108/01.01.03_60/es_201108v010103p.pdf
整體架構如圖 1,分為前端(Terminal)與後端(Server)兩 部份,我們使用的特徵為前端特徵擷取的部份。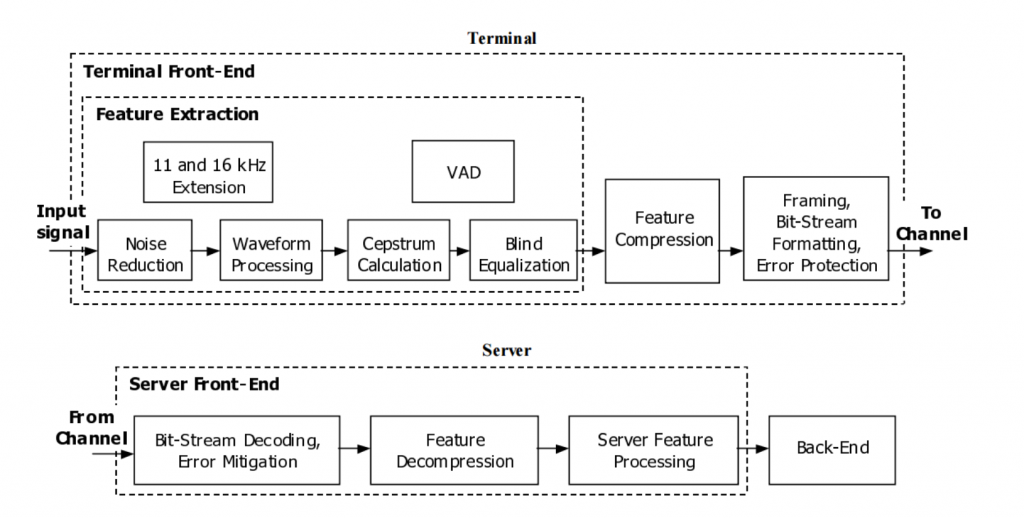
圖1: 分散式語音辨識系統之進階前端特徵擷取架構圖,分為前端(Terminal)與後 端(Server)兩部份
在取特徵時會進行降低雜訊(Noise Reduction)等步驟,如圖 2,輸入的語音訊號會經過以下步驟: 減少噪音、波形處理、倒頻譜計算以及盲目均等法,減少噪音是使用維納濾波器(Wiener filter)將語音訊號經過兩個階段的降噪處理,波形處理全名是SNR-dependent Waveform Processing(SWP),透過處理語音訊號,目的是強調高 SNR 波形部分並去除低SNR波形部分; 盲目均等法是對訊號中發生的濾波效應進行補償。
圖2: AFE擷取語音特徵的步驟,依序是減少噪音、波形處理、倒頻譜計算以及盲目 均等法
最後產生的特徵與 MFCC 相同是 39 維(dimension),包含12個倒頻譜係數加上對數能量(log energy),以及這13個向量的一階和二階(delta and delta-delta)導數
產生出了語音特徵之後,我們需要對這些特徵做一些前處理,讓模型在使用這些特徵訓練時能夠有更好的效果。其中一項很重要的前處理過程就是特徵正規化,讓我們留到明天再來介紹~

