全連接神經網路的層和層之間,神經元都是互相連接,而層內的神經元彼此沒有連接。我們會使用兩種 FCDAE 架構,其輸入資料是含有噪音的多訓練資料,將 11 個連續音框串接起來,大小是 429 維的向量作為輸入,輸出則是輸入向量正中間音框對應的乾淨訓練資料,大小是 39 維。我們以隱藏層(hidden layer)數量作為區分這兩種架構。兩種架構都會在訓練過程應用批量正規化(Batch Normalization, BN),觀察是否對實驗結果有所幫助。
Batch Normalization 參考論文: https://arxiv.org/pdf/1502.03167.pdf
第一種架構如圖 1,以FCDAE(3h)表示,網路有3層隱藏層,每一層都是500個神經元,參數量約735K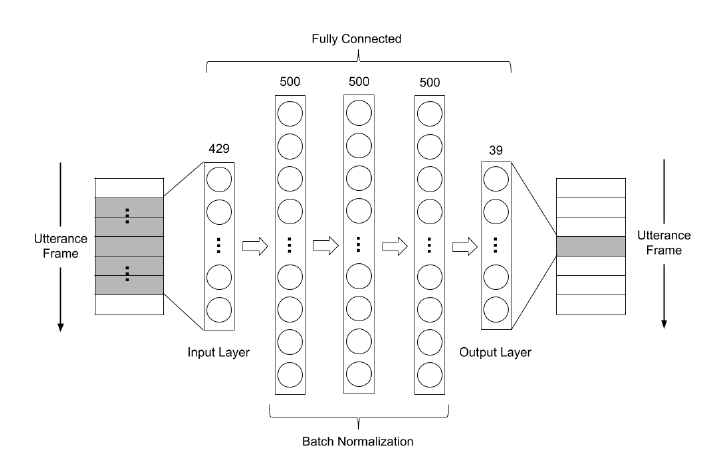
圖 1: FCDAE(3h)的架構圖,有3層隱藏層,每一層都是500個神經元
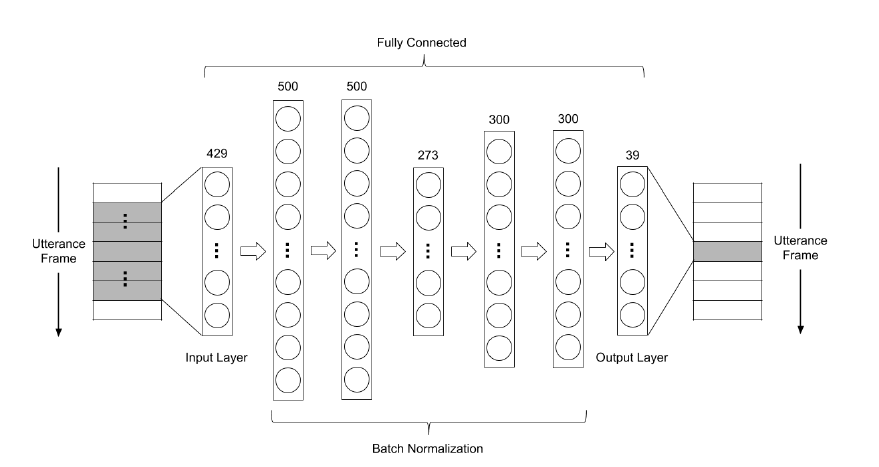
第二種架構如圖 2,本論文以FCDAE(5h)表示,是以FCDAE(3h)的架構為基礎
做修改。此網路有5層隱藏層,第一層和第二層有500個神經元,第三層有273個神經
元,第四層和第五層有300個神經元,參數量約 786K。和第一種架構相比,在參數量
略增加約51000個的情況下,我們加深網路的層數,目的是觀察在參數量相差不多的
條件下,網路的深度是否會影響除噪表現。除此之外,此網路的架構是不平衡的,即
編碼器和解碼器的大小不相同。在訓練兩個全連接除噪自動編碼器的超參數設定如下:
在模型建立與訓練的部分,使用的是 python+tensorflow+keras ,程式碼以 FCDAE(5h) 為範例如下:
# FCDAE(5h) model
from keras.layers import *
from keras.models import *
import keras.optimizers
leakyrelu = keras.layers.LeakyReLU(alpha=0.3)
# optimizer
adam = keras.optimizers.Adam(lr=0.001, beta_1=0.9, beta_2=0.999, epsilon=1e-08, decay=1e-5)
# instantiate model
model = Sequential()
model.add(Dense(500, input_dim=429))
model.add(leakyrelu)
model.add(Dense(500))
model.add(leakyrelu)
model.add(Dense(273))
model.add(leakyrelu)
model.add(Dense(300))
model.add(leakyrelu)
model.add(Dense(300))
model.add(leakyrelu)
model.add(Dense(39))
model.compile(loss='mse', optimizer=adam)

