完成了第一階段的除噪模型之後,接下來要進入辨識階段,利用乾淨狀態資料和降噪後的含有噪音的訓練資料來訓練兩個語音辨識模型,分別是傳統的HMM-GMM 模型以及CTC 模型,完成訓練後將同樣經過降噪後的測試資料集送入模型辨識得到最終的結果。
HMM-GMM 模型的部分我們會使用在Day07時提過的 HTK 工具。在聲學模型(AM)會以全詞模型(whole word model)為單位,除了數字0有兩個全詞模型,其他數字都會有各自的全詞模型。每個全詞模型有16個狀態(state),每一個狀態有3個高斯混合模型(GMM)。整個模型是一個由左到右的模型,不會跳過任何的狀態。除了全詞模型之外, 還有兩個暫停模型,第一種是靜音模型(silence model),包含3個可轉移狀態(圖 1), 每一個狀態是由6個高斯混合模型構成;第二種模型是短暫停頓模型(short-pause model),只包含一個狀態且此狀態和靜音模型中間的狀態共用。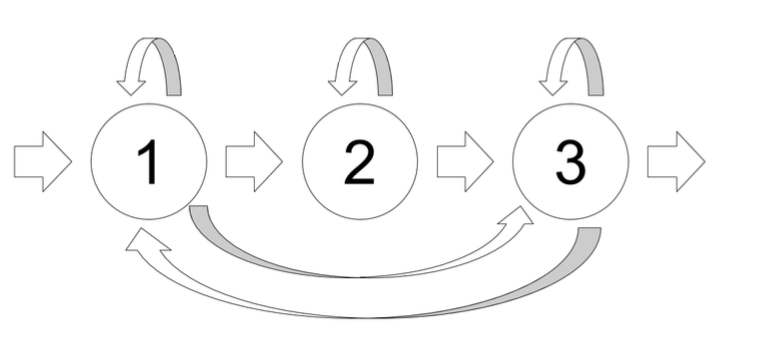
圖 1: 靜音模型中的3個可轉移狀態
在第二個模型中我們會使用遞迴神經網路(recurrent neural network, RNN)的架構並透過 CTC 進行訓練。和除噪模型使用的全連接網路不同,RNN 會將前一個時間點的輸出傳遞給下一個時間點,讓「過去」的訊息能夠被保留,使得神經網路具有記憶性。除了基本的 RNN 之外,為了讓網路能夠有長期的記憶性,研究學者後來提出了長短期記憶模型(Long Short-Term Memory, LSTM),和一般的RNN不同在於增加了3個閘門(gate):輸入門(input gate)、遺忘門(forget gate)和輸出門(output gate),輸入門控制目前的輸入是否進入,遺忘門控制過去的資訊是否保留,輸出門控制目前的狀態是否輸出,透過這3個門對資料的控制,得以讓 LSTM 有長期記憶的特性。
CTC 模型架構如圖 2。輸入是39維特徵,接著是3層的隱藏層,每一層都是雙向的LSTM,每個方向的LSTM都有133個unit,3層的大小皆相同;在隱藏層內的連接方面,每一層中兩個方向的輸出以相加的結果作為下一層的輸入。最後是輸出層,一層含有14個神經元的全連接層,原因是實驗使用的是全詞當作輸出結果,包含one, two, ..., nine, zero, oh, sp, sil 以及 CTC 會使用的 blank,一共14個。輸出經過 CTC 計算後得到一個序列(sequence),這個序列就是 end-to-end 系統的預測結果。在訓練 CTC 模型的超參數設定如下:
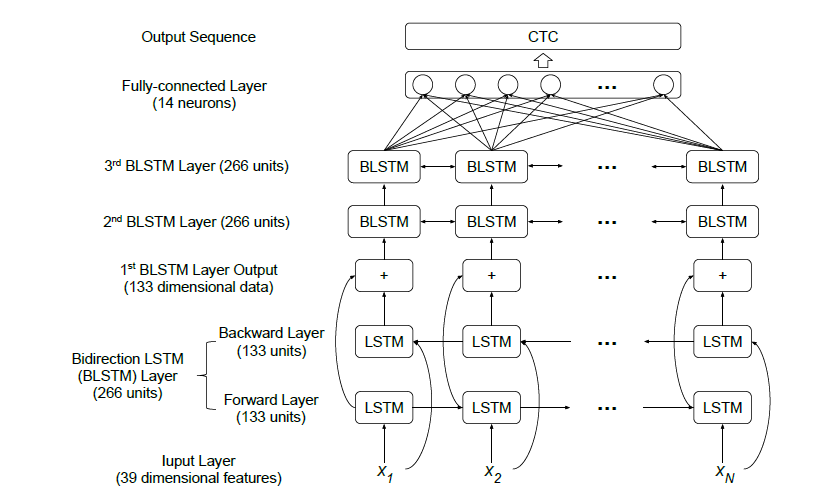
圖 2: CTC 模型架構圖,輸入是39維的語音特徵,有3層雙向 LSTM 及1層全連接層
明天將繼續介紹程式實作的部分。

