接著昨天討論到的 Cross Entropy ,今天把重點放到了 BinaryCrossEntropy 上,顧名思義,之所以叫 Binary 就代表此工具主要是用於探討二元分類的問題,我們會將資料集換成 cats_vs_dogs 。
NUM_OF_CLASS = 2
train_split, ds_info = tfds.load(
'cats_vs_dogs',
split='train[:75%]',
shuffle_files=True,
as_supervised=True,
with_info=True)
test_split, ds_info = tfds.load(
'cats_vs_dogs',
split='train[75%:]',
shuffle_files=True,
as_supervised=True,
with_info=True)
fig = tfds.show_examples(train_split, ds_info)
print(f'number of train: {len(train_split)}')
print(f'number of test: {len(test_split)}')

實驗一: CategoricalCrossentropy
因相對 oxford_flowers102,cats_vs_dogs 問題簡單很多,所以我們把 epoch 從100降低到30個,模型很快就能夠收斂。
base = tf.keras.applications.MobileNetV2(input_shape=(224, 224, 3), include_top=False, weights='imagenet')
net = tf.keras.layers.GlobalAveragePooling2D()(base.output)
net = tf.keras.layers.Dense(NUM_OF_CLASS)(net)
model = tf.keras.Model(inputs=[base.input], outputs=[net])
model.compile(
optimizer=tf.keras.optimizers.SGD(LR),
loss=tf.keras.losses.CategoricalCrossentropy(from_logits=True),
metrics=[tf.keras.metrics.CategoricalAccuracy()],
)
start = timeit.default_timer()
history = model.fit(
ds_train,
epochs=EPOCHS,
validation_data=ds_test,
verbose=True)
產出:
loss: 2.8140e-04 - categorical_accuracy: 1.0000 - val_loss: 0.0401 - val_categorical_accuracy: 0.9916
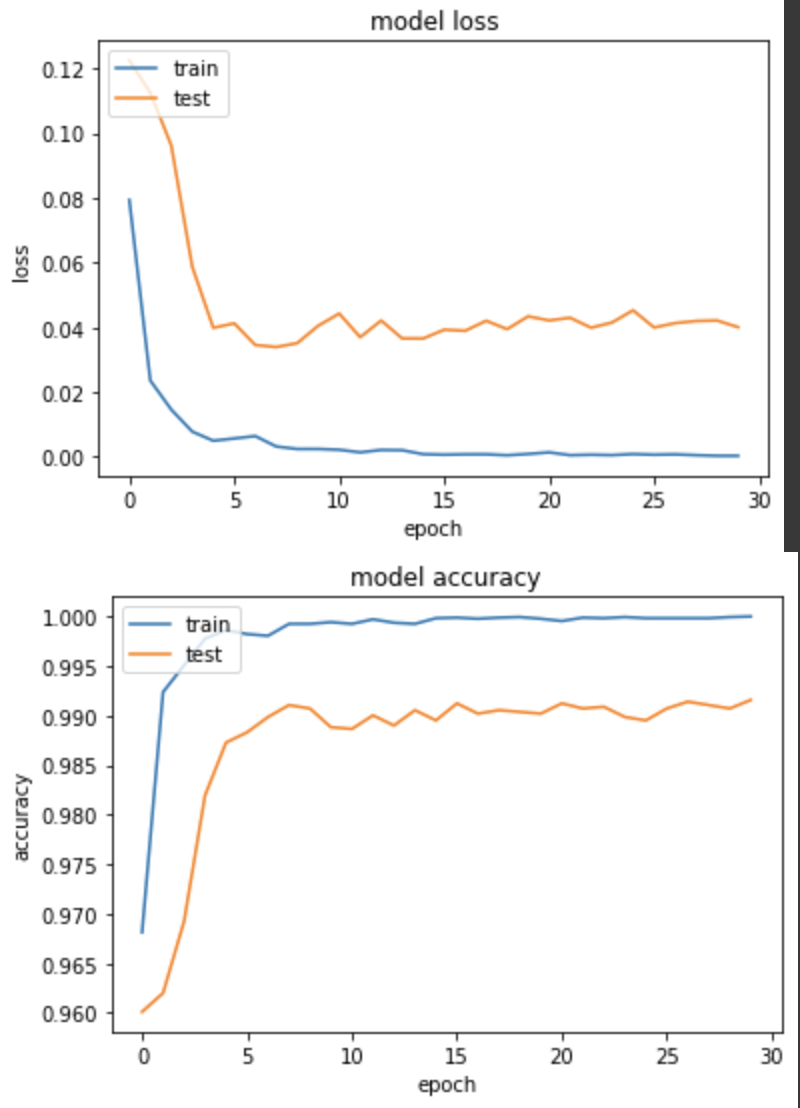
可以看到訓練非常快就收斂,第4個 epoch 就有98%的準確度。
實驗二:BinaryCrossEntropy
訓練前有一個需要注意的地方,就是在輸出的dense layer中,節點要設為1,因為兩個分類可以簡化成一個0~100%的分數,靠0%代表分類一,靠100%代表分類二。
base = tf.keras.applications.MobileNetV2(input_shape=(224, 224, 3), include_top=False, weights='imagenet')
net = tf.keras.layers.GlobalAveragePooling2D()(base.output)
net = tf.keras.layers.Dense(1)(net). # dense node = 1
model = tf.keras.Model(inputs=[base.input], outputs=[net])
model.compile(
optimizer=tf.keras.optimizers.SGD(LR),
loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),
metrics=[tf.keras.metrics.BinaryAccuracy()],
)
start = timeit.default_timer()
history = model.fit(
ds_train,
epochs=EPOCHS,
validation_data=ds_test,
verbose=True)
產出:
loss: 7.6595e-04 - binary_accuracy: 0.9997 - val_loss: 0.0360 - val_binary_accuracy: 0.9921
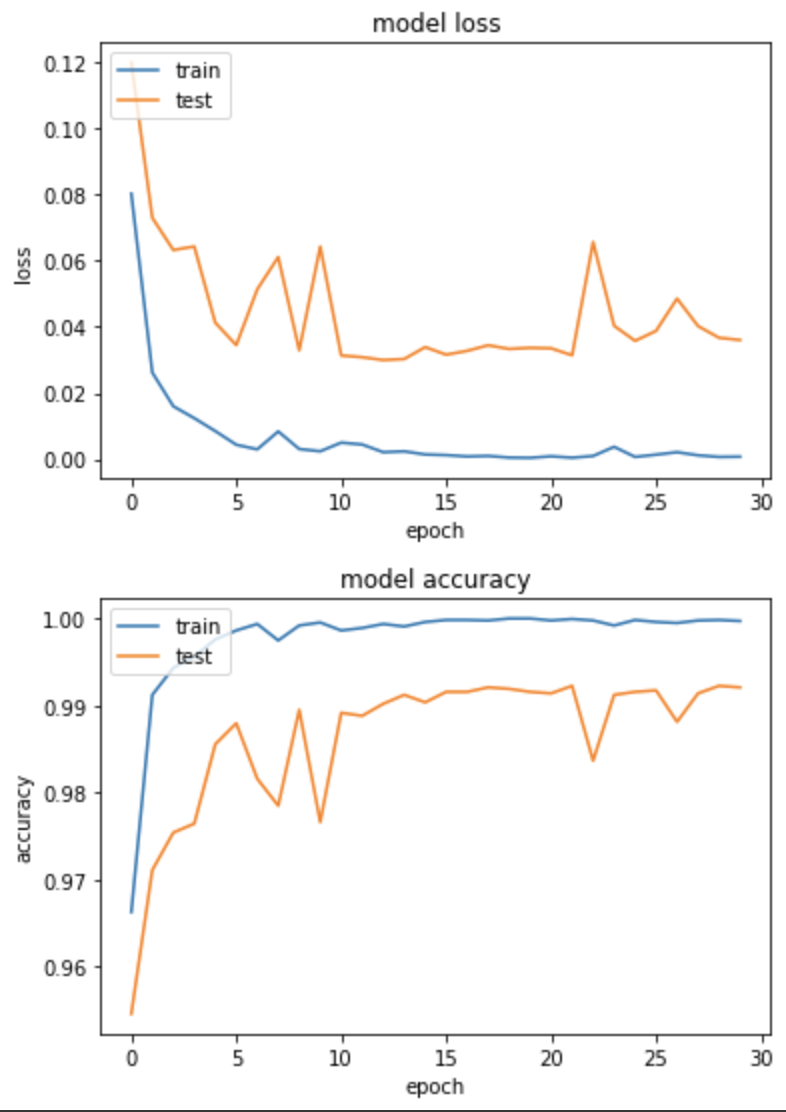
收斂速度也是非常快,得到的結果和CategoricalCrossentropy差不多。
實驗三:另類的用法,用 BinaryCrossEntropy 訓練多分類!?
我自己在嘗試 BinaryCrossEntropy 訓練貓狗分類時,一開始意外的把最後的 dense layer 節點設成2,結果也是可以訓練,所以我就好奇了,那如果我用 BinaryCrossEntropy 訓練 oxford_flowers102 的102個分類呢?
base = tf.keras.applications.MobileNetV2(input_shape=(224, 224, 3), include_top=False, weights='imagenet')
net = tf.keras.layers.GlobalAveragePooling2D()(base.output)
net = tf.keras.layers.Dense(NUM_OF_CLASS)(net)
model = tf.keras.Model(inputs=[base.input], outputs=[net])
model.compile(
optimizer=tf.keras.optimizers.SGD(LR),
loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),
metrics=[tf.keras.metrics.CategoricalAccuracy()],
)
start = timeit.default_timer()
history = model.fit(
ds_train,
epochs=EPOCHS,
validation_data=ds_test,
verbose=True)
產出:
loss: 0.0418 - categorical_accuracy: 0.6373 - val_loss: 0.0516 - val_categorical_accuracy: 0.2980
結果是可以的(不過要把label 做 one-hot encoding),只是訓練的成果並不太好,經過了100個 epochs 準確度不到三成就是了...。
以上就是 BinaryCrossentropy 使用上的幾個小心得,希望大家使用上時可以注意這幾點。

