注意力機制讓預測目標單詞之前比較其與所有來源單詞(在翻譯任務中精確地來說是詞向量)之間的語意關聯性來提高翻譯的準確度。今天就讓我們來快速回顧注意力機制的原理,以及用 Keras API 建立帶有 attention layer 的 LSTM seq2seq 模型。
以下是注意力機制的基本原理:
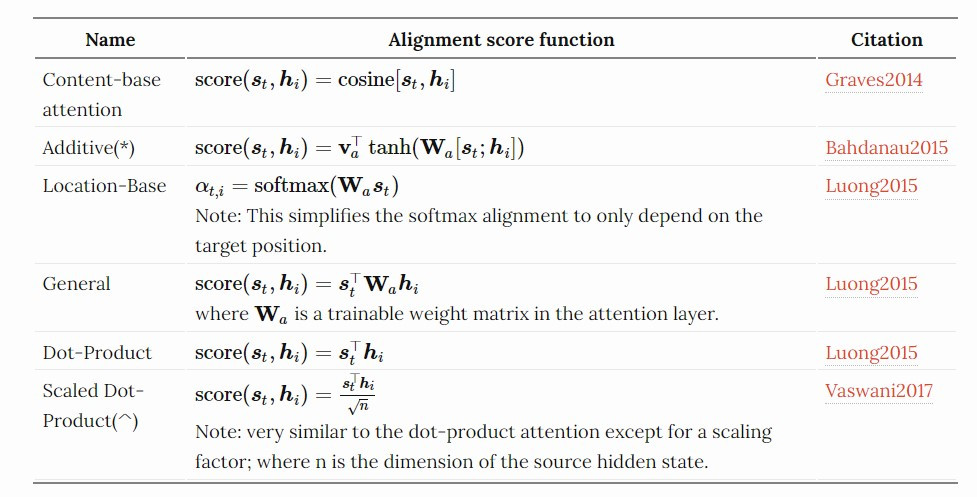
輸入值 query 會根據「記憶」計算出其與各個來源 value 之間根據其對應的 key 進行比對,得到 query 與各個 key 的相關性之後,彙整進而輸入 attention layer 得到輸出值。講得有些饒口,以翻譯器的神經網絡來說明, query 就是當下時間點解碼器的 hidden state (在 LSTM 架構中不含 cell state ),而 values 即是所有時間點的內部狀態
(依序代表各個來源單詞
) ,透過比較計算各別的出關聯性分數
,透過 attention function 將每個
與相對應的權重
相加起來(加權平均),得到輸出值 context vector
。
圖片來源:Programming VIP
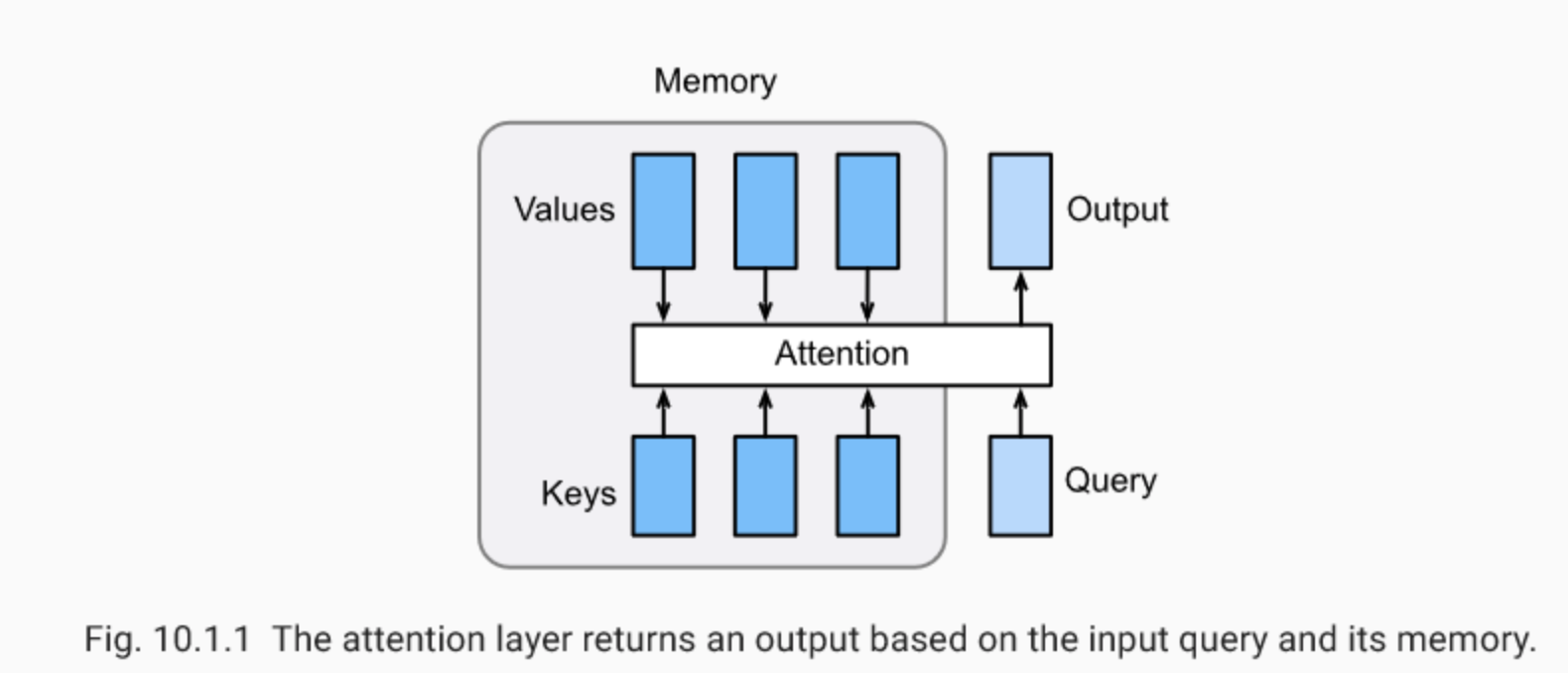
常見的關聯性分數(又稱 attention function )計算方式:
圖片來源:lilianweng.github.io
在導入注意力機制串接 encoder 與 decoder 之前,我們先建立雙層的 LSTM seq2seq :
import tensorflow as tf
from tensorflow.keras import Sequential, Input
from tensorflow.keras.layers import Dense, LSTM, Embedding
from tensorflow.keras.models import Model
### preparing hyperparameters
## source language- Eng
src_wordEmbed_dim = 18 # one-hot encoding dim is used here, while generally is dimensionality of word embedding
src_max_seq_length = 4 # max length of a sentence
## target language- 100 (for example)
tgt_wordEmbed_dim = 27 # one-hot encoding dim is used here, while generally is dimensionality of word embedding
tgt_max_seq_length = 12 # max length of a sentence
# dimensionality of context vector
latent_dim = 256
# Building a 2-layer LSTM encoder
enc_layer_1 = LSTM(latent_dim, return_sequences = True, return_state = True, name = "1st_layer_enc_LSTM")
enc_layer_2 = LSTM(latent_dim, return_sequences = False, return_state = True, name = "2nd_layer_enc_LSTM")
enc_inputs = Input(shape = (src_max_seq_length, src_wordEmbed_dim))
enc_outputs_1, enc_h1, enc_c1 = enc_layer_1(enc_inputs)
enc_outputs_2, enc_h2, enc_c2 = enc_layer_2(enc_outputs_1)
enc_states = [enc_h1, enc_c1, enc_h2, enc_h2]
# Building a 2-layer LSTM decoder
dec_layer_1 = LSTM(latent_dim, return_sequences = True, return_state = True, name = "1st_layer_dec_LSTM")
dec_layer_2 = LSTM(latent_dim, return_sequences = True, return_state = True, name = "2nd_layer_dec_LSTM")
dec_dense = Dense(tgt_wordEmbed_dim, activation = "softmax")
dec_inputs = Input(shape = (tgt_max_seq_length, tgt_wordEmbed_dim))
dec_outputs_1, dec_h1, dec_c1 = dec_layer_1(dec_inputs, initial_state = [enc_h1, enc_c1])
dec_outputs_2, dec_h2, dec_c2 = dec_layer_2(dec_outputs_1, initial_state = [enc_h2, enc_c2])
dec_outputs_final = dec_dense(dec_outputs_2)
# Integrate seq2seq model
seq2seq_2_layers = Model([enc_inputs, dec_inputs], dec_outputs_2, name = "seq2seq_2_layers")
seq2seq_2_layers.summary()
plot_model(seq2seq_2_layers, to_file = "output/2-layer_seq2seq.png", dpi = 100, show_shapes = True, show_layer_names = True)
我們將剛建好的模型畫出來:
from tensorflow.keras.utils import plot_model
plot_model(seq2seq_2_layers, to_file = "output/2-layer_seq2seq.png", dpi = 100, show_shapes = True, show_layer_names = True)
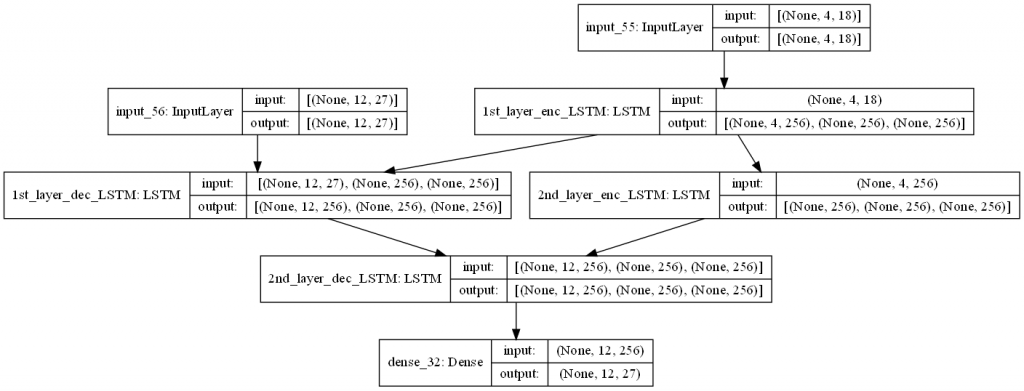
明天將會將 attention mechanism 加入以上的雙層 LSTM seq2seq 模型當中。
本來設定今天將要完成附帶注意力機制的 Seq2Seq 模型建構,並比較單詞之間的關聯性,然而由於時間關係,必須先停在這裡。明天接著完成!晚安!