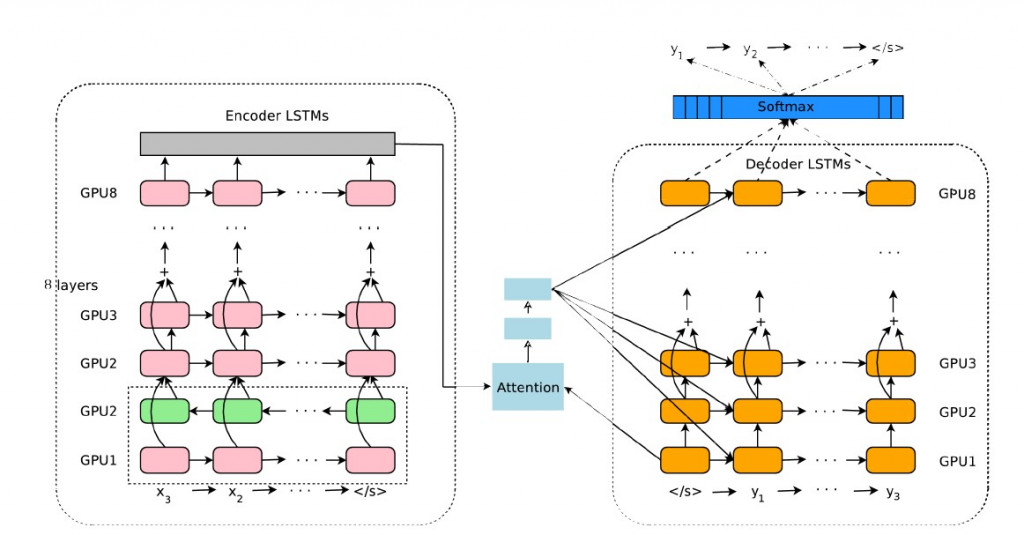
Google 翻譯團隊在2016年發表了重要文章《Google’s Neural Machine Translation System: Bridging the Gap between Human and Machine Translation》,其中提出了深層 LSTM 翻譯器網絡 GNMT 。其由多層的 LSTM 建構編碼器及解碼器所構成,並在加入了注意力機制( attention mechanism ),大幅提升了長句翻譯的效率。
2016年提出的GNMT翻譯器架構加入了注意力機制:
NMT is often accompanied by an attention mechanism which helps it cope effectively with long input sequences.
文字出處:GNMT (2016)

圖片來源:Make a Meme.org
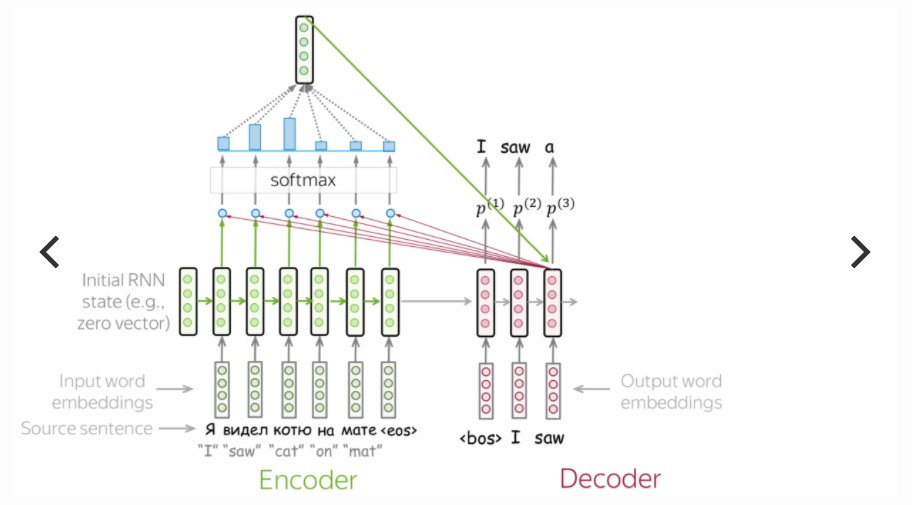
Seq2seq 模型先經由編碼器來吃進所有輸入的詞向量( word embedding ),內部狀態(例如 RNN 的 hidden state 或 LSTM 的 hidden state 和 cell state )的遞嬗,暫時存在單一個 context vector 裡,再傳入解碼器之間依照時間序吐出目標詞向量,完成目標文句的預測。
傳統encoder-decoder的翻譯過程:
圖片來源:jalammar.github.io
雖然 LSTM 增加了內部狀態 cell state 來保存長期記憶,彌補了傳統 RNN 長距離依賴的問題(白話來說 RNN 很健忘),傳統基於 LSTM 架構的 seq2seq 模型依舊難以克服序列化計算所帶來的低效率。改善方法就是在解碼器生成新的詞向量之前,由上帝視角來「注意」編碼器當中所有時間點的內部狀態,這便是注意力機制!
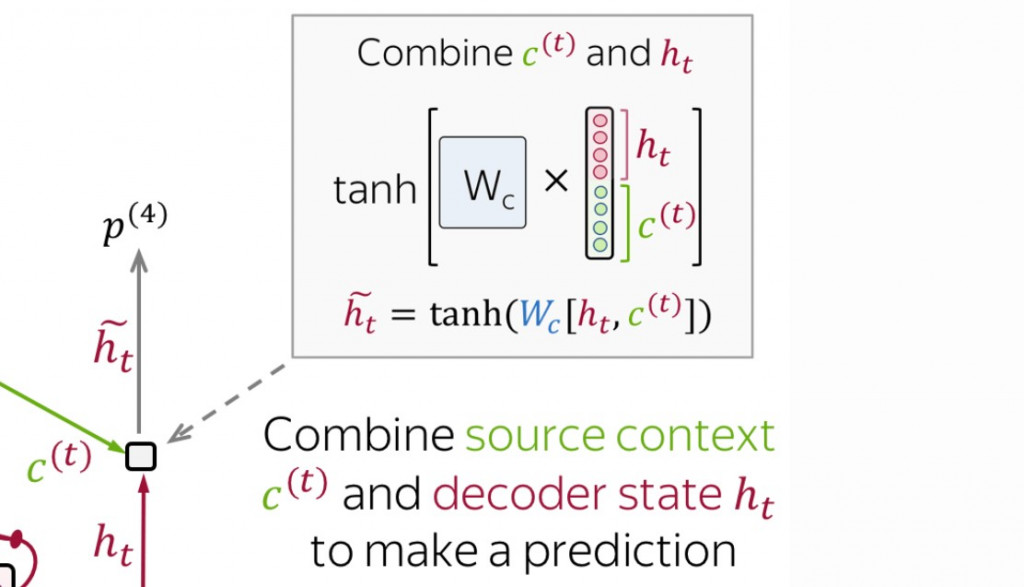
在生成當下時間點的詞向量之前,我們有以下幾個步驟要做:




經過了所有時間點之後,我們在編碼器與解碼器之間架起了多個 context vectors ,實現平行化計算( parallelism ),較傳統的 seq2seq 翻譯速度更快。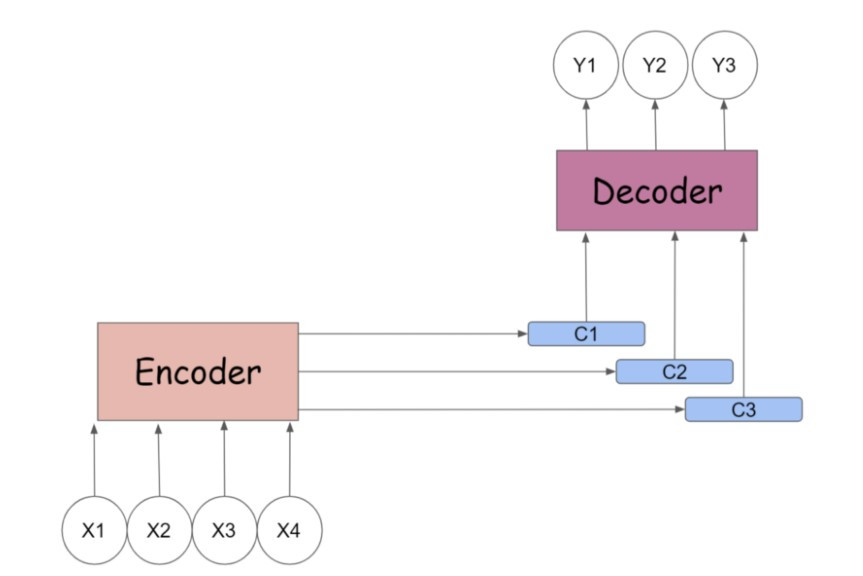
圖片來源:medium.com
在上述的四個步驟中,我們如何求出關聯性分數呢?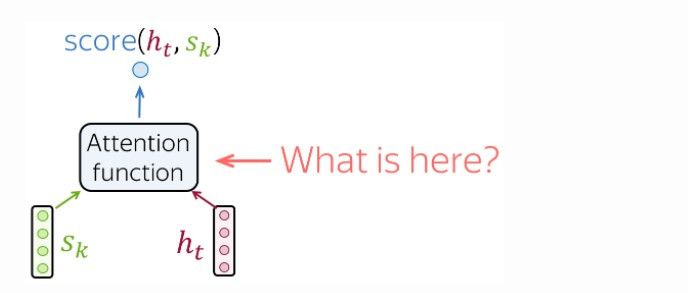
最常採用的三個計算方式有:
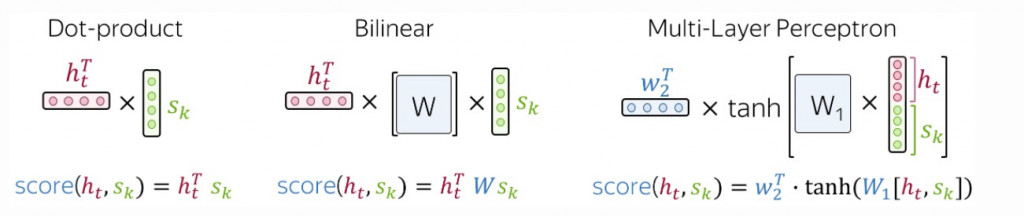
我們可以將每個輸入單詞序列與目標單詞序列之間的關聯性分數以矩陣來呈現(輸入與輸出文句的長度通常並不一,因此並非方陣),其表示了各個輸入單詞與目標單詞之間的關聯性:

圖片來源:Neural Machine Translation by Jointly Learning to Align and Translate (2016)
附帶注意力機制的 seq2seq 模型能夠實現 encoder 與 decoder 之間的平行計算,以提升神經機器翻譯的文字生成效率。最重要的是,注意力機制允許編碼器中尚未傳遞完成的內部狀態也輸入解碼器,藉由比較當下輸出與各輸入單詞之間的相關性,能避免逐字翻譯的窘境,增加了翻譯的準確度。在2017年 Google 又在各層 LSTM 神經元之間加入了審視各層內部狀態與下一層其他內部狀態之間的注意力機制,被稱之為自注意力機制( self-attention mechanism ),與今天所介紹的 encoder-decoder attention 相對。這種機制藉由找出文中與某單詞最高度相關的其他單詞,更加提升了語意的判讀。今天的理論就介紹到這邊,明天將進行在翻譯器神經網絡之間加入注意力的實作。期待與各位明天再會,晚安!