書接上回[Day 16] TFLM + BLE Sense + MP34DT05 就成了迷你智慧音箱(上)。接下來要繼續談如何讓板子能清楚聽懂且學會新的不同的命令及如何把訓練好的成果佈署到板子上。
在前面的章節中曾提到「好的老師(標註)帶你上天堂,不好的老師帶你住套房」,由此得知資料集的收集、清洗和高品質的標註是有多重要。在這個micro_speech的範例中,為了方便起見,它是採用公開的語音命令資料集(共2.3GByte)(相關論文)這個資料集就是TinyML一書作者Pete Warden所貢獻的,它包括有超過10萬多個WAV格式已分割好的聲音文件,其中包括30個常用的英文單詞,(數字0-9、上下左右、前進後退停止、貓狗鳥樹房子床、Yes, No, WOW, On, Off...),每個單詞約有1500~4000個樣本不等,其中還包括不同人種、年紀、性別的發音,具有足夠的多樣性,很適合初學者作為練習用,可完整下載後再挑選自己需要的單詞和必要的數量來作為資料集。不過這個資料集有個小缺點就是聲音太乾淨了,不是在有背景音的環境下錄製,所以如果要讓訓練的成果更好些,更符合現實場景使用,可能還要利用程式加入一些白雜訊來改善。
那如果你需要的單詞不在其中(含中文單詞),那要如何產生資料集呢?首先可以利用手機、電腦上的麥克風或BLE Sense板子上的麥克風直接錄音。錄音時取樣頻率建議16KHz,同時不要以MP3這類壓縮格式存檔,一定要選WAV這類非壓縮的格式,不然會嚴重破壞資料特徵。錄的時候可以連續錄音一次取得較多的樣本,重覆說出單詞(單詞長度最好不要超過一秒)N次,每次中間休息一秒,比方說:開_開_(連續x次)_開_,至少10 ~ 20次,越多越好,由越多人來錄更好(數十到數百人),原則上就是希望獲取的資料集擁有更佳多樣性。接著用市售或開源影音編輯軟體把單一的聲音檔案(假設名為on.wav),切成很多個1秒的WAV格式的資料(建置一個on檔案夾存放on_001.wav, on_002.wav,... on_xxx.wav) ,而切割時要適當的調整起點,讓聲音的波形儘量置中,方便後續取出特徵值。如圖Fig. 17-1所示。不過這樣的工作非常累人,要有點耐心完成它。
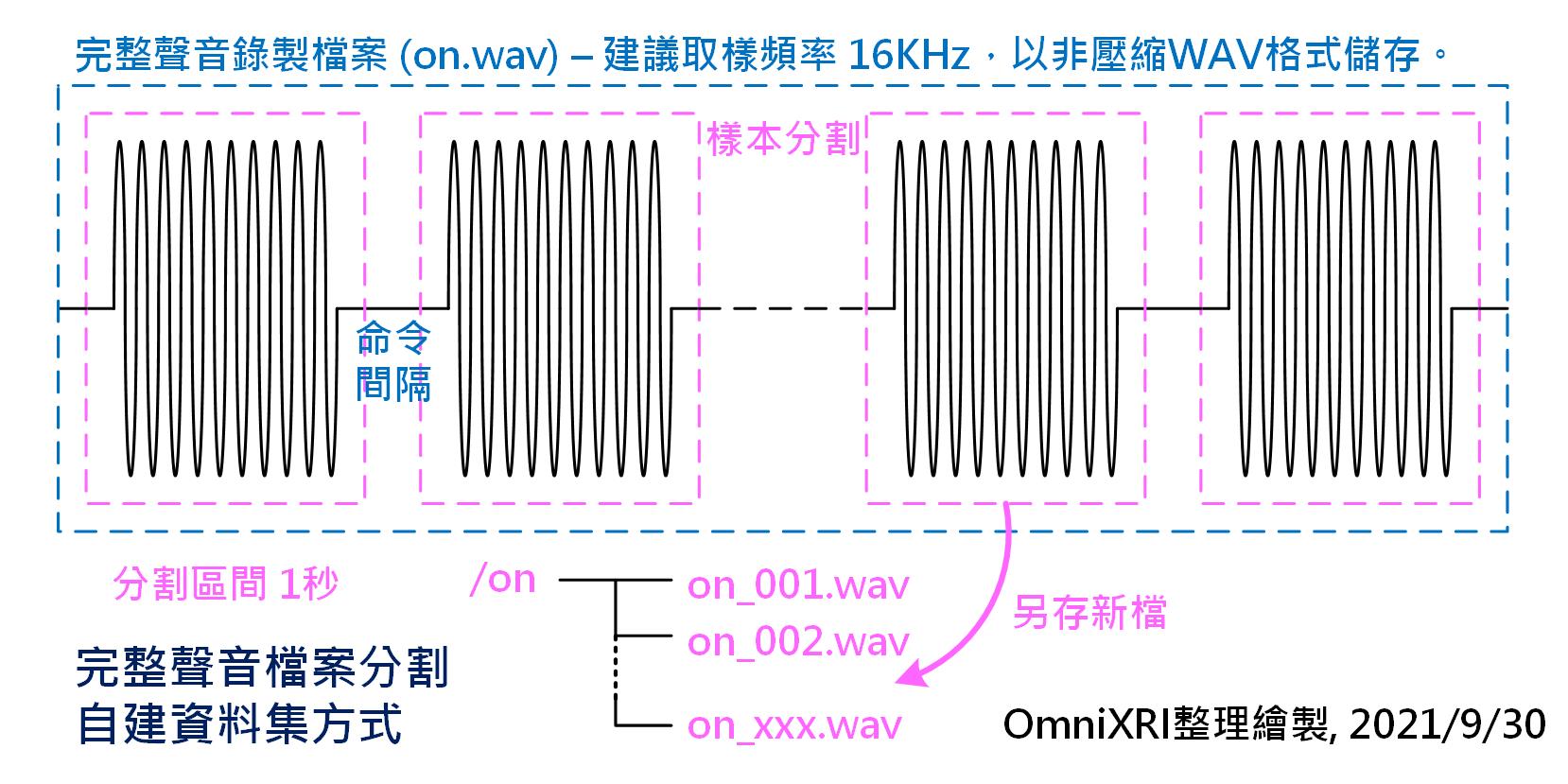
Fig. 17-1 完整聲音檔案分割自建資料集方式。(OmniXRI整理製作, 2021/9/30)
由於錄製的聲音是時間域(Time Domain)的資料,所以不容易分析其主要成份(特徵),所以經常需要利用快速傅立葉轉換(Fast Fourier Transform, FFT)來將時間域資料轉換到頻率域(Frequency domain)格式資料。可是只取頻率域的資料又會失去時間順序的特徵,所以就有頻譜圖(Spectrogram)的概念產生。使用一個小的移動視窗移動一小段距離,逐一取得頻域結果(一維資料,X軸向變化),再將時間軸的變化組在一起(第二維資料,Y軸變化),如此作法就等於把聲音變成影像來辨識,而每個聲音檔案都會轉換成一張頻譜圖。如圖Fig. 17-2所示。
以圖Fig. 17-2為例,每個視窗範圍(30ms)先以FFT轉成256個頻率特徵,再每6個平均成一組數值,餘數自成一組,故可得43個數值,組成X軸向資料。接著移動20ms,再重複上述動作,並將得到內容從Y軸方向組合。這部份的數量就要看一個聲音檔案時長多少而定,同樣地,餘數也自成一組,所以1秒的聲音會組出49個數值。因此最後會得到49x43(H x W, Rows x Columns)像素的一張頻譜圖。
而訓練時可選擇預先將頻譜圖轉好再進行,這樣可節省一些檔案存取及訓練的時間。而推論時,是直接從板子上的麥克風讀入原始聲音信號,所以MCU端程式就必須要有對應的頻譜圖轉換(特徵提取)程式。

Fig. 17-2 TensorFlow Lite Micro Micro Speech聲音頻譜圖轉換範例。(OmniXRI整理製作, 2021/9/30)
這個範例中使用了一個名為tiny_conv的模型架構(原始出處官網連結已失效),它的結構很簡單,只有一層輸入層,一層卷積層,一層全連結層和一層輸出層,如圖Fig. 17-3所示。輸入層是一張二維影像,即49 x 40(H x W, Rows x Columns)像素的頻譜圖。卷積層使用8個10 x 8的卷積核(Kernel),卷積核XY方向的平移距離(Stride)為2,填空方式(Padding)為SAME,即卷積核移到最右邊或最下方時,超出沒有對應到的像素一樣進行卷積。因此卷積完會得到8張25 x 20像素大小的特徵圖,此時再將其展平得到4000(25x20x8)個神經元,再和輸出層進行全連結。而輸出層則是有4個輸出神經元,每個神經元再以Softmax來進行輸出機率正規化,分別代表靜音、Yes、No和Unknow的辨識結果。
而這樣的模型結構是否夠用,則需要更多實驗,經過不斷地調整平移距離、網路層數、卷積核大小、全連結神經元數量等各項超參數。必要時還要透過混淆矩陣及其它可視化工具來判定調整方向,甚至重新增加資料集數量及多樣性,以滿足推論準確性的接受度。
官方目前有提供一個Colab版本的訓練程式,可依其步驟說明,將自定義的資料集替換上去,再進行重新訓練、轉換(TF轉TFLite)及優化(INT8量化),即可得到MCU端所需的modle.cc。而這幾個步驟大致上和[Day 12]的說明類似,這裡就不再贅述。
貼心提醒
依據Colab訓練程式上的說明,指出以GPU進行訓練大約1~2小時可以完成,不過理想很豐滿,現實很骨感,理論上Colab可連續使用12小時,但實際上可能隨時會斷線,有可能是因為線上人數過多資源不足或者自己的電腦不小心睡覺,還要三不五時用滑鼠點一下網頁,以免網頁瀏覽器自己停止更新。更慘的是如果多次長時間進行訓練時,可能還會被誤會在作商業行為而被短暫停權一到數日。因此如果準備的資料集很大、模型參數很多、網路結構很複雜,建議可能還是在自己的電腦上用GPU來跑或者花錢買Colab進階版使用權,以免所有訓練結果沒了,得不償失。
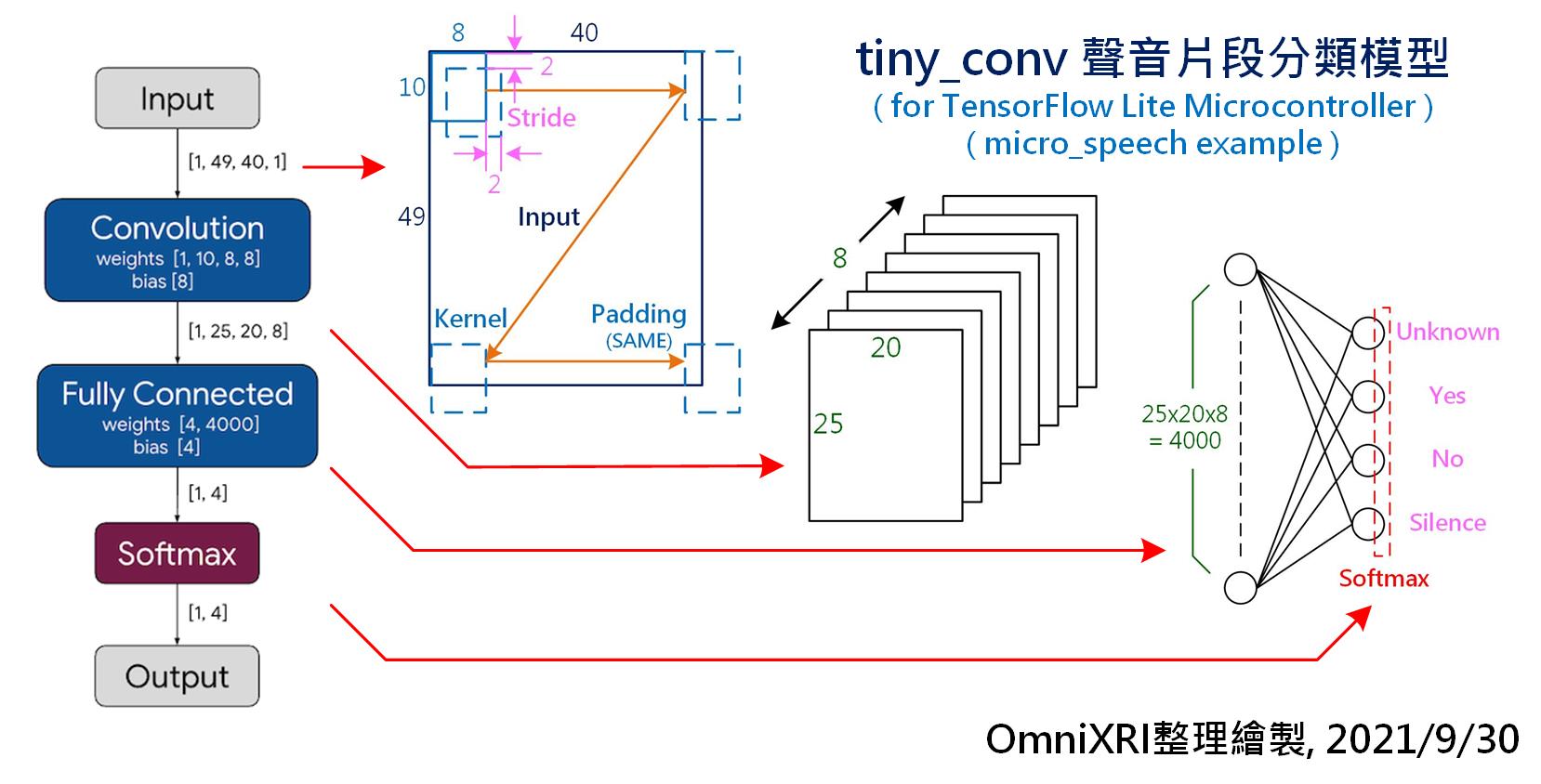
Fig. 17-3 TensorFlow Lite Micro Micro Speech tiny_conv聲音片段分類模型
最後要把Colab產出的model.cc中的參數複製到MCU的檔案中,如[Day 16]圖Fig. 16-2所示,故名思義,micro_features_model.cpp,這個檔案就是MCU辨識「YES」、「NO」的模型參數檔,是由TFLM訓練、轉換和優化出來的,而其內容類似[Day 13]圖Fig. 13-1,只需把產出的C Code陣列內容複蓋掉這個檔案中相同的位置,之後再以Arduino IDE重新編譯即可。
/*
micro_features_model.cpp
已完成訓練、轉換及優化的模型參數
*/
const unsigned char g_model[] DATA_ALIGN_ATTRIBUTE = {
0x20, 0x00, 0x00, 0x00, 0x54, 0x46, 0x4c, 0x33, 0x00, 0x00, 0x00, 0x00,
... (略)
0x03, 0x00, 0x00, 0x00}; // 模型參數,用TFLM產出的結果來替代
const int g_model_len = 18712; // 模型參數數量
花了這麼長的篇幅說明,大家大概已經可以感受到tinyML的開發流程頗為麻煩,所以[Day 10] tinyML整合開發平台介紹才會幫大家介紹幾個常見的雲端一站式tinyML整合開發平台,再來tinyML的應用就會改用這類平台來完成,如此就可以更輕鬆上手了。
參考連結
TensorFlow Lite Microcontroller - Micro Speech 微語音辨識
TensorFlow - TensorFlow - Examples - speech_commands 語音命令相關開源碼
Simple audio recognition: Recognizing keywords 說明文件
Train a Simple Audio Recognition Model Colab範例程式

