今天的任務只有一個:採用物件導向設計法將附帶注意力機制的 seq2seq 神經網絡封裝起來
物件導向程式設計( object-oriented programming, OOP )讓程式具有描述抽象概念的能力,相當於人類具有抽象思考的行為。
類別( class )與物件( object ):
Python 也具有物件導向的概念,其類別成員( attributes 與 methods )的訪問( access )權限由寬鬆到嚴格又分為 public 、 protected 和 private 三種,可藉由 name mangling 的方式修改成員名稱來制定不同等級的訪問權限。然而關於物件導向的細節就不在這裡詳細描述了,有興趣的小夥伴可以參考本篇最下方文章[3]。
物件導向三大特性:封裝( encapsulation )、繼承( heritance )、多型( polymorphism )
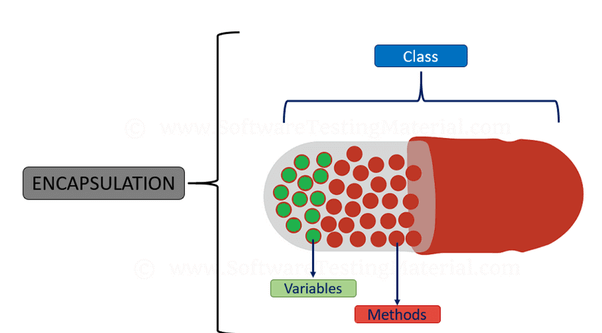
維基百科上對於封裝的定義:
In object-oriented programming (OOP), encapsulation refers to the bundling of data with the methods that operate on that data, or the restricting of direct access to some of an object's components. Encapsulation is used to hide the values or state of a structured data object inside a class, preventing direct access to them by clients in a way that could expose hidden implementation details or violate state invariance maintained by the methods.
文字來源:Wikipedia
白話來說,封裝就是將一堆執行特定功能的程式碼打包起來寫入類別,要使用時才被外界呼叫的過程。封裝除了使得具有特定功能的程式碼被有結構性地呈現而不會散落在各處,能夠被妥善管理、便於維護之外,透過指定成員的訪問權限,還能使得程式不會任意被更改,達到保護資訊的效果。
圖片來源:shouts.dev
不免俗套,首先我們引入必要的模組、類別與函式:
from tensorflow.keras import Input
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Layer, Dense, LSTM, Embedding, Dot, Activation, concatenate
import pydot as pyd
from tensorflow.keras.utils import plot_model
我們先定義 LuongAttention 類別,其繼承了 tf.keras.layers.Layer :
class LuongAttention(Layer):
"""
Luong attention layer.
"""
def __init__(self, latent_dim, tgt_wordEmbed_dim):
super().__init__()
self.AttentionFunction = Dot(axes = [2, 2], name = "attention_function")
self.SoftMax = Activation("softmax", name = "softmax_attention")
self.WeightedSum = Dot(axes = [2, 1], name = "weighted_sum")
self.dense_tanh = Dense(latent_dim, use_bias = False, activation = "tanh", name = "dense_tanh")
self.dense_softmax = Dense(tgt_wordEmbed_dim, use_bias = False, activation = "softmax", name = "dense_softmax")
def call(self, enc_outputs_top, dec_outputs_top):
attention_scores = self.AttentionFunction([enc_outputs_top, dec_outputs_top])
attenton_weights = self.SoftMax(attention_scores)
context_vec = self.WeightedSum([attenton_weights, enc_outputs_top])
ht_context_vec = concatenate([context_vec, dec_outputs_top], name = "concatentated_vector")
attention_vec = self.dense_tanh(ht_context_vec)
return attention_vec
接下來定義 Encoder 類別,和 LuongAttention 一樣亦為 tf.keras.layers.Layer 的子類別( subclass ):
class Encoder(Layer):
"""
2-layer Encoder LSTM with/ without attention mechanism.
"""
def __init__(self, latent_dim, src_wordEmbed_dim, src_max_seq_length):
super().__init__()
# self.inputs = Input(shape = (src_max_seq_length, src_wordEmbed_dim), name = "encoder_inputs")
self.latent_dim = latent_dim
self.embedding_dim = src_wordEmbed_dim
self.max_seq_length = src_max_seq_length
self.lstm_input = LSTM(units = latent_dim, return_sequences = True, return_state = True, name = "1st_layer_enc_LSTM")
self.lstm = LSTM(units = latent_dim, return_sequences = False, return_state = True, name = "2nd_layer_enc_LSTM")
self.lstm_return_seqs = LSTM(units = latent_dim, return_sequences = True, return_state = True, name = "2nd_layer_enc_LSTM")
def call(self, inputs, withAttention = False):
outputs_1, h1, c1 = self.lstm_input(inputs)
if withAttention:
outputs_2, h2, c2 = self.lstm_return_seqs(outputs_1)
else:
outputs_2, h2, c2 = self.lstm(outputs_1)
states = [h1, c1, h2, h2]
return outputs_2, states
然後是 Decoder 類別:
class Decoder(Layer):
"""
2-layer Decoder LSTM with/ without attention mechanism.
"""
def __init__(self, latent_dim, tgt_wordEmbed_dim, tgt_max_seq_length):
super().__init__()
self.latent_dim = latent_dim
self.embedding_dim = tgt_wordEmbed_dim
self.max_seq_length = tgt_max_seq_length
self.lstm_input = LSTM(units = latent_dim, return_sequences = True, return_state = True, name = "1st_layer_dec_LSTM")
self.lstm_return_no_states = LSTM(units = latent_dim, return_sequences = True, return_state = False, name = "2nd_layer_dec_LSTM")
self.lstm = LSTM(units = latent_dim, return_sequences = True, return_state = True, name = "2nd_layer_dec_LSTM")
self.dense = Dense(tgt_wordEmbed_dim, activation = "softmax", name = "softmax_dec_LSTM")
def call(self, inputs, enc_states, enc_outputs_top = None, withAttention = False):
# unpack encoder states [h1, c1, h2, c2]
enc_h1, enc_c1, enc_h2, enc_c2 = enc_states
outputs_1, h1, c1 = self.lstm_input(inputs, initial_state = [enc_h1, enc_c1])
if withAttention:
# instantiate Luong attention layer
attention_layer = LuongAttention(latent_dim = self.latent_dim, tgt_wordEmbed_dim = self.max_seq_length)
dec_outputs_top = self.lstm_return_no_states(outputs_1, initial_state = [enc_h2, enc_c2])
attention_vec = attention_layer(dec_outputs_top, enc_outputs_top)
outputs_final = self.dense_softmax(attention_vec)
else:
outputs_2, h2, c2 = self.lstm(outputs_1, initial_state = [enc_h2, enc_c2])
outputs_final = self.dense(outputs_2)
return outputs_final
以上定義完了神往網絡層,接著定義模型本身 My_Seq2Seq ,其繼承了 tf.keras.models.Model 類別:
class My_Seq2Seq(Model):
"""
2-Layer LSTM Encoder-Decoder with/ without Luong attention mechanism.
"""
def __init__(self, latent_dim, src_wordEmbed_dim, src_max_seq_length, tgt_wordEmbed_dim, tgt_max_seq_length, model_name = None, withAttention = False,
input_text_processor = None, output_text_processor = None):
super().__init__(name = model_name)
self.encoder = Encoder(latent_dim, src_wordEmbed_dim, src_max_seq_length)
self.decoder = Decoder(latent_dim, tgt_wordEmbed_dim, tgt_max_seq_length)
self.input_text_processor = input_text_processor
self.output_text_processor = output_text_processor
self.withAttention = withAttention
def call(self, enc_inputs, dec_inputs):
enc_outputs, enc_states = self.encoder(enc_inputs)
dec_outputs = self.decoder(inputs = dec_inputs, enc_states = enc_states, enc_outputs_top = enc_outputs, withAttention = self.withAttention)
return dec_outputs
def plot_model_arch(self, enc_inputs, dec_inputs, outfile_path = None):
tmp_model = Model(inputs = [enc_inputs, dec_inputs], outputs = self.call(enc_inputs, dec_inputs))
plot_model(tmp_model, to_file = outfile_path, dpi = 100, show_shapes = True, show_layer_names = True)
試著執行一下封裝的結果:
if __name__ == "__main__":
# hyperparameters
src_wordEmbed_dim = 18
src_max_seq_length = 4
tgt_wordEmbed_dim = 27
tgt_max_seq_length = 12
latent_dim = 256
# specifying data shapes
enc_inputs = Input(shape = (src_max_seq_length, src_wordEmbed_dim))
dec_inputs = Input(shape = (tgt_max_seq_length, tgt_wordEmbed_dim))
# instantiate My_Seq2Seq class
seq2seq = My_Seq2Seq(latent_dim, src_wordEmbed_dim, src_max_seq_length, tgt_wordEmbed_dim, tgt_max_seq_length, withAttention = True, model_name = "seq2seq_no_attention")
# build model
dec_outputs = seq2seq(
enc_inputs = Input(shape = (src_max_seq_length, src_wordEmbed_dim)),
dec_inputs = Input(shape = (tgt_max_seq_length, tgt_wordEmbed_dim))
)
print("model name: {}".format(seq2seq.name))
seq2seq.summary()
seq2seq.plot_model_arch(enc_inputs, dec_inputs, outfile_path = "output/seq2seq_LSTM_with_attention.png")
類別雖然定義好了,但執行起來還有一些 bug 
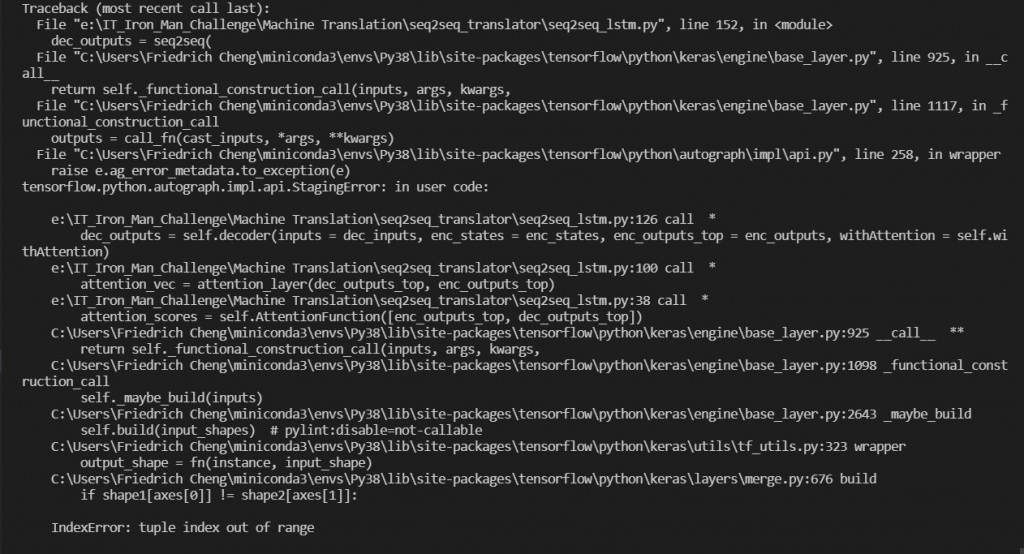
我們有以下殘留課題:
我們將上述問題留著明天繼續解決,各位晚安!

