前一天在說明使用的語音特徵時有提到,模型有靜態模型跟動態模型兩種。在訓練靜態模型時,因為資料集中的語音檔是由不同人(語者,21名男性;30名女性)所錄製的,因此我們會使用 cross-speaker histogram equalization(CSHE) 的方式來消除不同語者間的差異性並且只保留情緒的變異。CSHE 會將多個實際語者轉換為一個虛擬語者,如此一來我們就能夠得到一個虛擬語者的資料分佈 ,接下來將每 個實際語者的分佈
都轉換成虛擬語者的分佈
,流程如 圖 1。
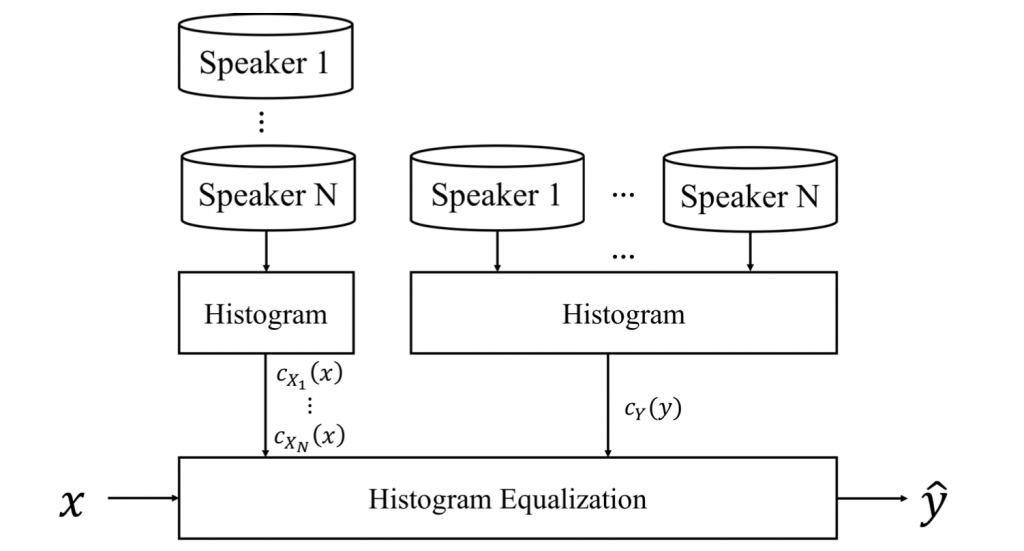
圖 1: CSHE流程圖。 為 N 個實際語者的分佈,
為一個虛擬語者的分佈
正規化的方法為直方圖均衡法(Histogram Equalization, HE),直方圖均衡法是將連續的特徵資料視為各自獨立,並將這些資料轉換到目標分佈上。在此我們用 Y(y) 表示目標分佈而 X(x) 表示原始特徵分佈,p 表示原始特徵值,q 表示轉換後的 特徵值,轉換的公式如下:
我們分別計算 X(x) 與 Y(y) 的累積分佈函數(Cumulative Distribution Function, CDF),再
將原始特徵值轉換至目標分佈。
動態模型的部分,採用的特徵正規化方式與語音辨識相同,是使用 CMVN (Day09)。不過在Day09時我們是對每一維特徵做 CMVN,而現在則是對每一個語者中的每一維特徵做 CMVN,因此 CMVN的數學式會變成:
其中,S為語者總數(訓練集: 26,測試集: 25), 表示語者 s 中共有 T 個音框,
表示語者 s 中第 t 個音框的第 i 維特徵,
表示語者 s 中第 i 維特徵所有音框的平均值,
表示表示語者 s 中第 i 維特徵所有音框的標準差。
明天我們將繼續介紹前處理的部分:資料平衡與標籤(label)調整。

