在 Day20 介紹資料集時有提到過五類情緒有資料不平衡的問題,為了處理資料不平衡的問題,我們會在 loss function(crossentropy)上加入一與類別資料量呈反比的類別權重。對於每一筆資料樣本 i ,假設 為實際的標註向量而
模型預測所輸出的向量,則 loss function 會以下列的公式呈現:
其中C為類別數, 為每筆資料樣本 i 的類別權重,N 為訓練資料總量,
為樣本 i 所屬類別的訓練資料量。round 運算表示將數字取四捨五入至小數點後第一位。主要的
想法為資料平衡,強調資料量少的類別其資料樣本的錯誤和不強調資料量多的類別其資料樣本的錯誤,經過計算後各類的類別權重如值表 1。
/ | Angry | Emphatic | Neutral | Positive | Rest
------------- | -------------
weight | 1.1 | 0.5 | 0.2 | 1.5 | 1.4
表1: 各類別權重
Label 調整的部份我們會先使用訓練集訓練一分類器(A)對訓練集進行分類,透過 A 分類器每一筆訓練樣本都會得到一輸出向量,將此向量作為新的 train label。因此原本以 one-hot vector 表示的 train label 會轉變為包含五類機率的向量。接著我們使用新的 train label 訓練另一分類器(稱B)。訓練流程如圖 1。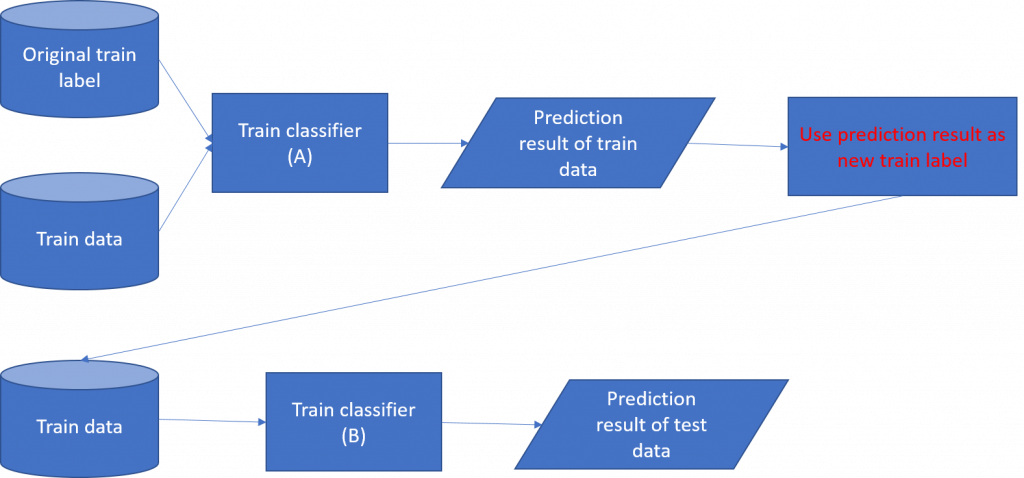
圖 1: 處理 noisy label 訓練流程圖
使用此方式訓練的目的在於處理語音情緒中 noisy label 的問題。我們所使用的語料庫是由多名語言學家進行標記的,不同學家對於語音情緒的感知可能會不同。實際上,每一筆樣本所被標記的類別可能不會被所有的語言學家同意,因此它可以被視為 noisy label。一般來說,機器學習的分類系統不希望出現 noisy label。藉由改變標記的方式,我們能夠使模型對於本質上有 noisy label 具有更好的學習能力。

