各位早安,書接上回我們學會換頁爬取文章標題了,今天我們要對程式碼進行一些改良,使其更符合我們的需求,也更方便使用
今天我們要做的就是優化昨天的程式增加一些功能
昨天的程式碼
import requests
import bs4
def getData(url):
headers = {"cookie" : "over18=1"}
#建立headers用來放要附加的cookie
request = requests.get(url,headers = headers)
#將網頁資料利用requests套件GET下來並附上cookie
data = bs4.BeautifulSoup(request.text, "html.parser")
titles = data.find_all("div", class_ = "title")
#解析網頁原始碼
for title in titles:
if title.a != None:
print(title.a.text)
#利用for迴圈印出全部並篩選掉已被刪除的文章
prePage = data.find("a", class_ = "btn wide", text = "‹ 上頁")
newUrl = "https://www.ptt.cc"+prePage["href"]
#抓取上頁按鈕內URL
return newUrl
#回傳newUrl出去
url = "https://www.ptt.cc/bbs/Pet_Get/index.html"
#抓PTT領養版的網頁原始碼
for i in range(1,4,1):
url = getData(url)
#利用for迴圈執行getData()函式3次
先從簡單的開始
首先就是昨天擷取下來的資料不好閱讀 密密麻麻的很長
所以我們再執行函式的 for 迴圈加個分隔線更方便看
for i in range(1,4,1):
url = getData(url)
print("---------------第"+str(i)+"頁---------------")
#利用for迴圈執行getData()函式3次
執行效果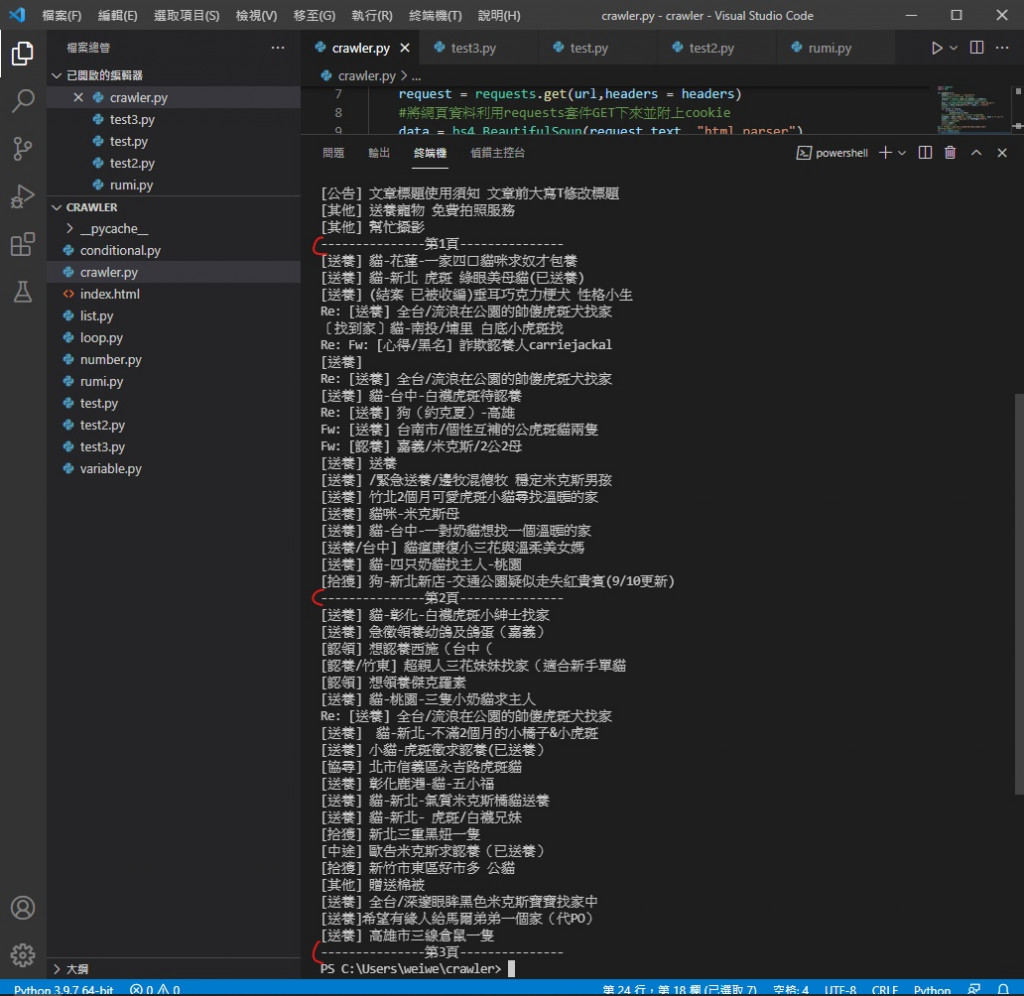
可以看到變得方便閱讀許多
再來我們要領養動物總要在標題看到喜歡的動物後 能去網站看它可不可愛
所以我們要找到每篇文章的 url 在哪
一樣打開網頁 F12 記得點左上角用來找位置的小工具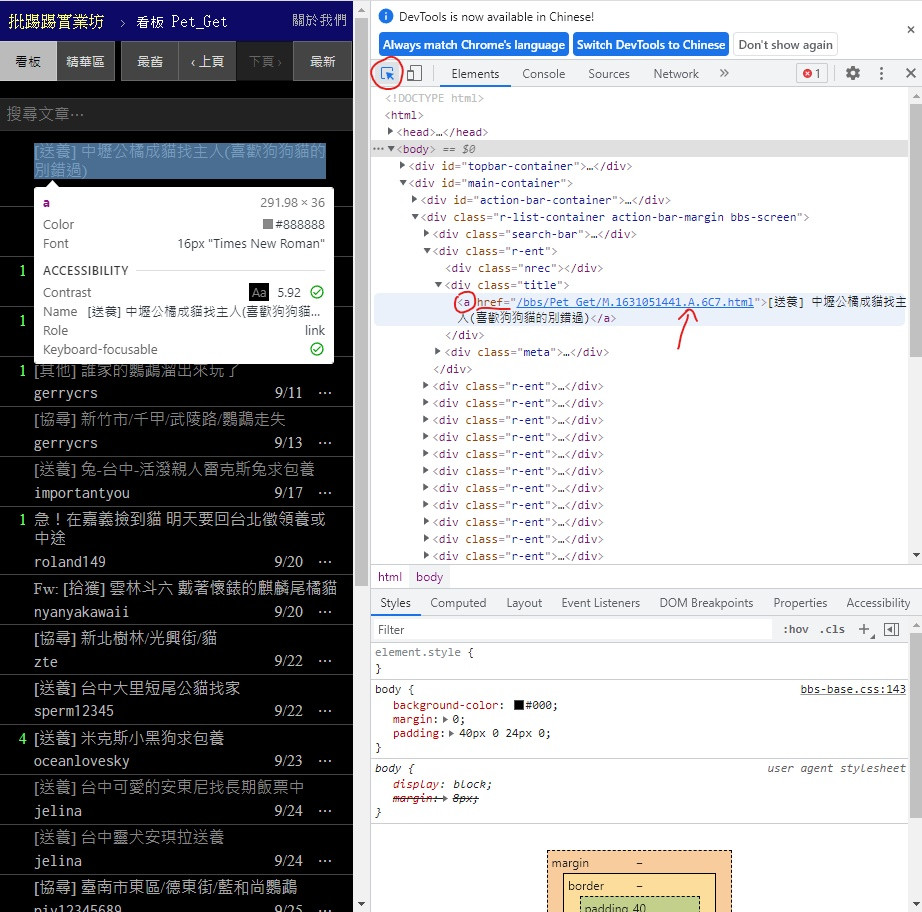
可以看到 在 < div > class = "title" 中的 < a > 標籤內的 href 部分
這不就跟文章標題一樣在 < a > 裡面嗎
所以不用再重新寫一個部份給它 只需要把它加進去就好
所以把 getData( ) 內用來印出文章標題的 for 回圈內的 print 裡改掉
從 print(title.a.text)
改成 print("https://www.ptt.cc"+title.a["href"],title.a.text)
注意 href 的呼叫格式比較特別
執行效果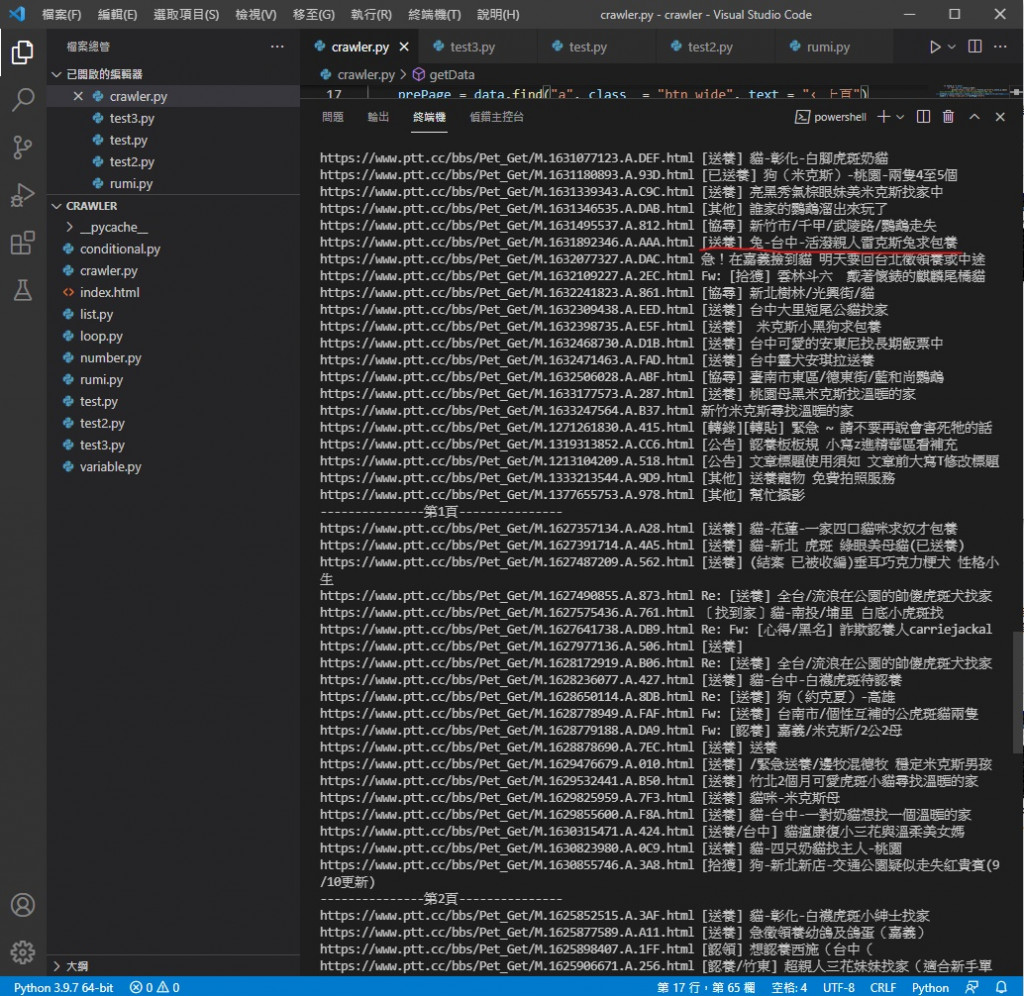
讓印出的標題前面加上 該文章的網址
這樣我們看到喜歡的就可以去網站看看牠的可愛模樣跟領養資訊
最後 是增加篩選方法
假設你不喜歡兔兔 就在印出文章標題跟 url 的 for 迴圈裡多加一層 if
for title in titles:
if title.a != None:
if "兔" not in title.a.text:
print("https://www.ptt.cc"+title.a["href"],title.a.text)
意思是如果 title.a.text 內沒找到 "兔" 這個字元才執行裡面的 print
執行效果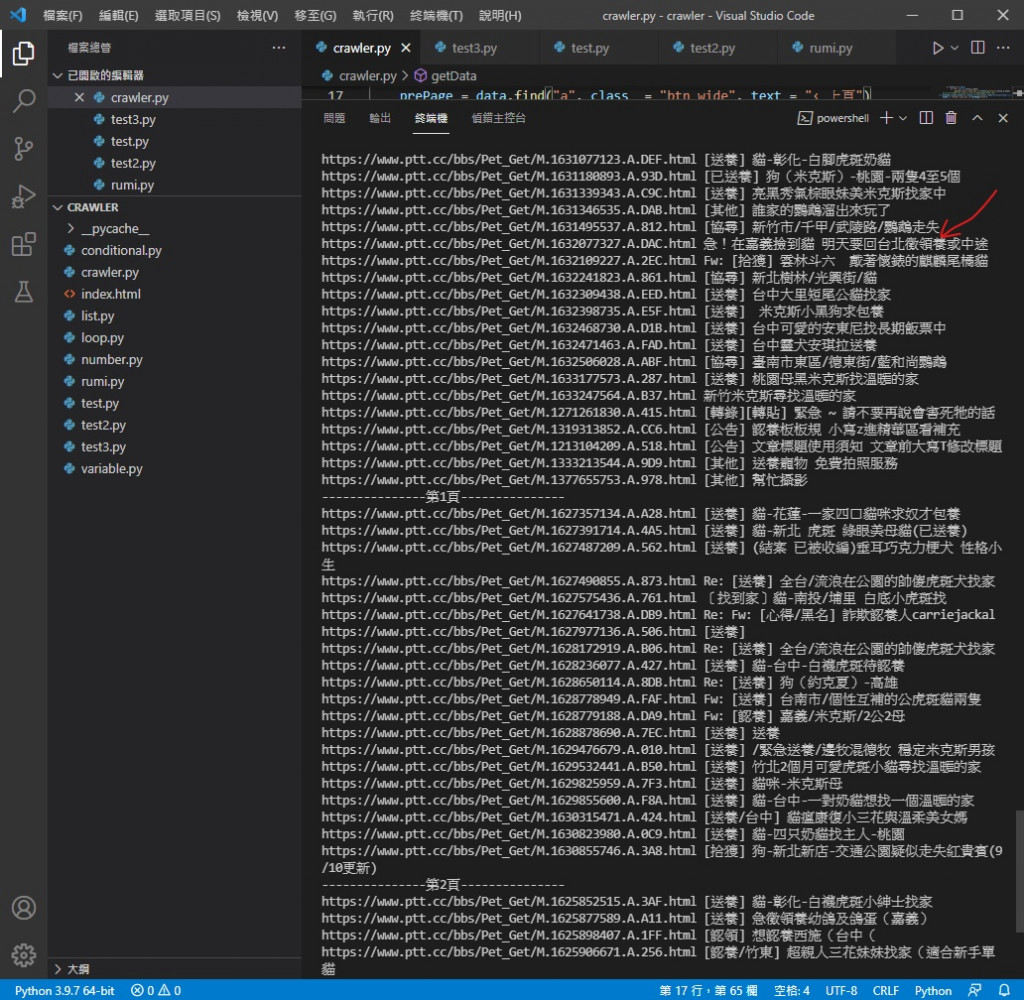
還記得上張圖的畫線位置嗎
本來有兔兔相關的被篩選掉了
你可以用這個方法篩選掉不想養或不能養的
只要更改 if 的條件就好
今天的程式碼
import requests
import bs4
def getData(url):
headers = {"cookie" : "over18=1"}
#建立headers用來放要附加的cookie
request = requests.get(url,headers = headers)
#將網頁資料利用requests套件GET下來並附上cookie
data = bs4.BeautifulSoup(request.text, "html.parser")
titles = data.find_all("div", class_ = "title")
#解析網頁原始碼
for title in titles:
if title.a != None:
if "兔" not in title.a.text:
print("https://www.ptt.cc"+title.a["href"],title.a.text)
#利用for迴圈印出全部並篩選掉已被刪除的文章以及印出URL
prePage = data.find("a", class_ = "btn wide", text = "‹ 上頁")
newUrl = "https://www.ptt.cc"+prePage["href"]
#抓取上頁按鈕內URL
return newUrl
#回傳newUrl出去
url = "https://www.ptt.cc/bbs/Pet_Get/index.html"
#抓PTT領養版的網頁原始碼
for i in range(1,4,1):
url = getData(url)
print("---------------第"+str(i)+"頁---------------")
#利用for迴圈執行getData()函式3次
今天我們對程式進行了優化 明天我們要來介紹檔案讀寫
有鳥活了67歲喔
你比較喜歡遠距還是實體上班上課呢

