在[Day 16]和[Day 17]「TFLM + BLE Sense + MP34DT05 就成了迷你智慧音箱」時已介紹過如何用Google TensorFlow Lite for Microcontrollers (TFLM)完成語音(命令)辨識,在[Day 19] tinyML開發好幫手─雲端一站式平台Edge Impulse簡介 時已介紹過如何建置Edge Impulse開發的環境建置。接下來就實際操練一下,看看如何把原來的英文的「Yes」、「No」單詞改成中文的「紅」、「綠」及「未知(Unknow)」和「背景音(Silence)」。
目前Edge Impulse提供了兩個和聲音有關的範例「Responding to your voice」、「Recognize sounds from audio」。前者為喚醒詞偵測(Key Word Spotting)或語音命令辨識,其語音內容為一短單詞(1秒內),有明顯間歇、變化的內容。而後者為一連續性沒明顯變化的不同背景音分類,如背景講話聲(離很遠、聽不清楚的內容)和水流聲等。但其實這兩者的本質還是相同的,就是把連續聲音切成很多小段(視窗)再進行分類(辨識)工作。接下來我們就取前者範例依序來說明如何完成這個範例。不過由於文章內容較長,所以將會拆成幾篇來說明。
Edge Impulse 操作介面選單如圖Fig. 20-1所示。包含下列項目。如果想要移除已建立的專案或資料集,在主要儀表板的最下方有一個危險區域(Danger zone),按【Delete this project】可刪除專案,按【Delete all data in this project】可刪除所有資料集。另外如果你嫌訓練時間過長,他們亦有提供商業版本,可修改儀表板上的「Performance settings」來動用GPU或更多平行計算資源來幫忙,目前免費版本是無法修改這些數值的。
Edge Impulse工作選單
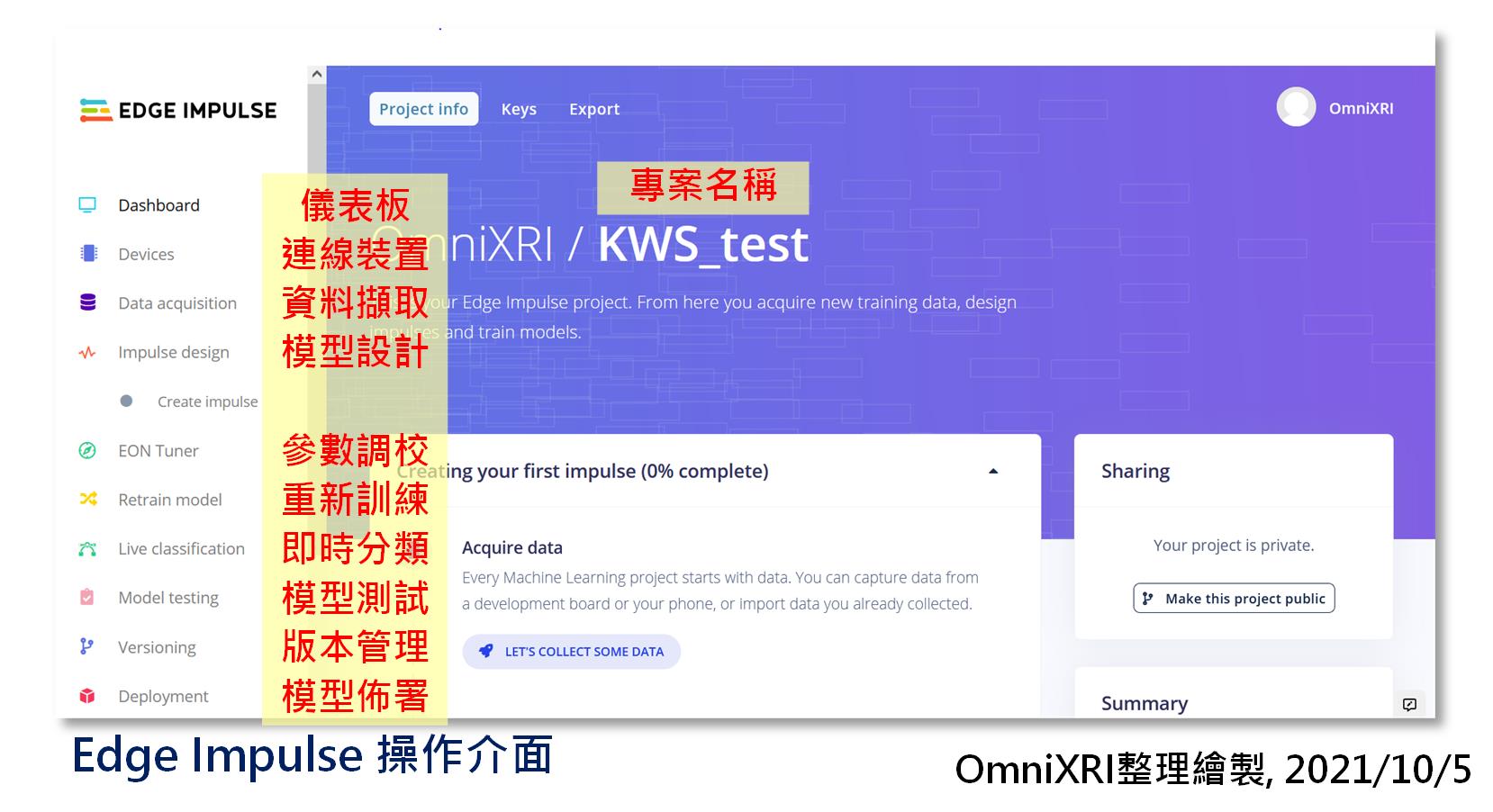
Fig. 20-1 Edge Impulse 操作介面。(OmniXRI整理繪製, 2021/10/5)
在[Day 19] tinyML開發好幫手─雲端一站式平台Edge Impulse簡介時已說明過如何將開發板連上網頁瀏覽器,這裡就不多作說明。不過如果有發生上網正常,Edge Impulse工作網頁開著但是開發板卻連不上時,建議可先拔除USB,稍待數秒後再插回,接著再進到Windows命令列模式執行下列指令,強迫重新連線,此時就會出現提示輸入使用者姓名(或電子郵件)、登入Edge Impulse密碼及開發板名稱,如此便可重新連線。
edge-impulse-daemon --clean
目前Edge Impulse提供離線把樣本及標註資料準備好再上傳,或者線上直接從開發板上的硬體(麥克風、運動感測器)擷取原始資料再從線上進行資料分割及標註,如圖Fig. 20-2所示,這裡會以後者進行介紹,即由使用者自行錄音產生資料集。
取樣前,要指定裝置(Device),通常只有連接一組開發板時不用選。感測器(Sensor)部份則要選擇內建麥克風(Build-in microphone)。接著設定取樣時間(單位mS),可以設定長一點(比方10秒),方便一次錄長一點,後面再來分割。再來設定取樣頻率,這裡預設為16KHz,無法變更。然後指定標籤(Label),比方說Green, Red等,不要用中文命名,但錄音內容則沒有限制,甚至台語也OK。最後按下【Start Sampling】,等待【Waiting to start】結束,出現【Sampling】就能開始錄製,錄製時會出現倒計時,方便使用者了解剩餘時間。
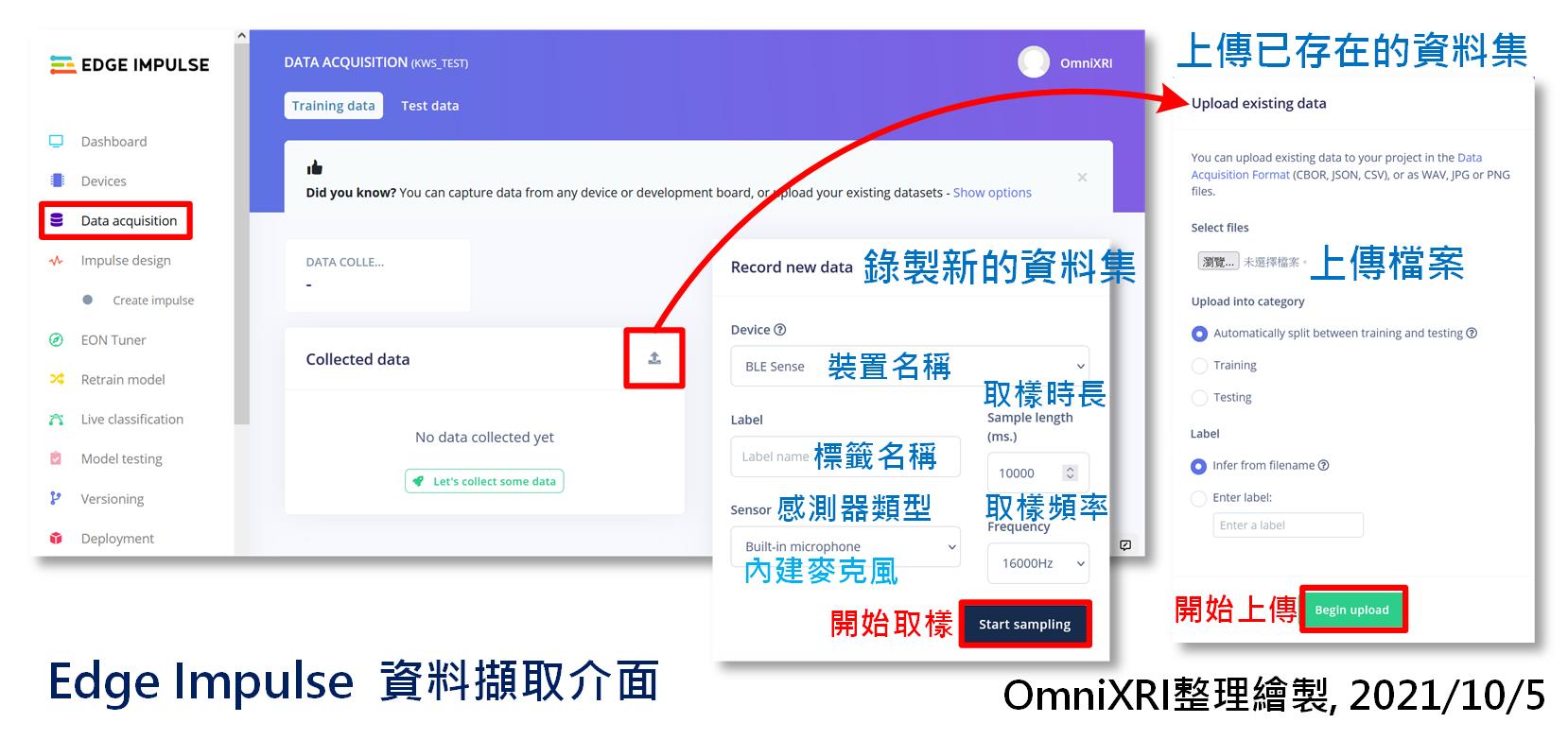
Fig. 20-2 Edge Impulse 資料擷取介面。(OmniXRI整理繪製, 2021/10/5)
錄的時候請不要直接對著嘴巴而是要偏一邊,以免錄到太多氣音。另外請在背景音較安靜的環境下錄製,屆時辨識效果會更好些。以想要錄「綠」這個中文單詞為例,就連續發出「綠—綠— … 綠—綠—」(—號代表停頓),直到取樣時間到,系統會自動命名存檔。錄完後已蒐集資料(Collected data)清單上會多出一筆資料,當點擊這筆資料時畫面左下角會出現錄製到的聲音檔波形,按下三角形播放鍵就能聽到剛才錄製的結果。如果樣本數不夠,則再多錄幾次即可。
接著點擊清單上最右邊的三個點符號,選擇「Split sample」,做聲音資料自動分割。進入後會看到系統已自動幫忙切割好1000ms為單位的格子,如果長度不符可自行調整右上角的「Set segment length(ms):」的數值,按下【Apply】即可重新分割。如果分割的位置不理想,可將游標移到格子上方(會出現手掌游標)再按下滑鼠左鍵拖拉左右移動。若有漏框到的,亦可點左上角「+Add Segment」再利動游標到想分割的地方點擊下去,就會產生新格子。當點擊指定格子時,可按下方三角形播放鍵,試聽一下內容是否正確,若不滿意可按格子上方的紅色按鍵【Remove segment】刪除格子。最後按下左下角【Split】就能分割資料。回到資料清單後,就會發現原來的檔案已被分割成數個單獨「綠」單詞的聲音樣本。完整步驟如圖Fig. 20-3所示。
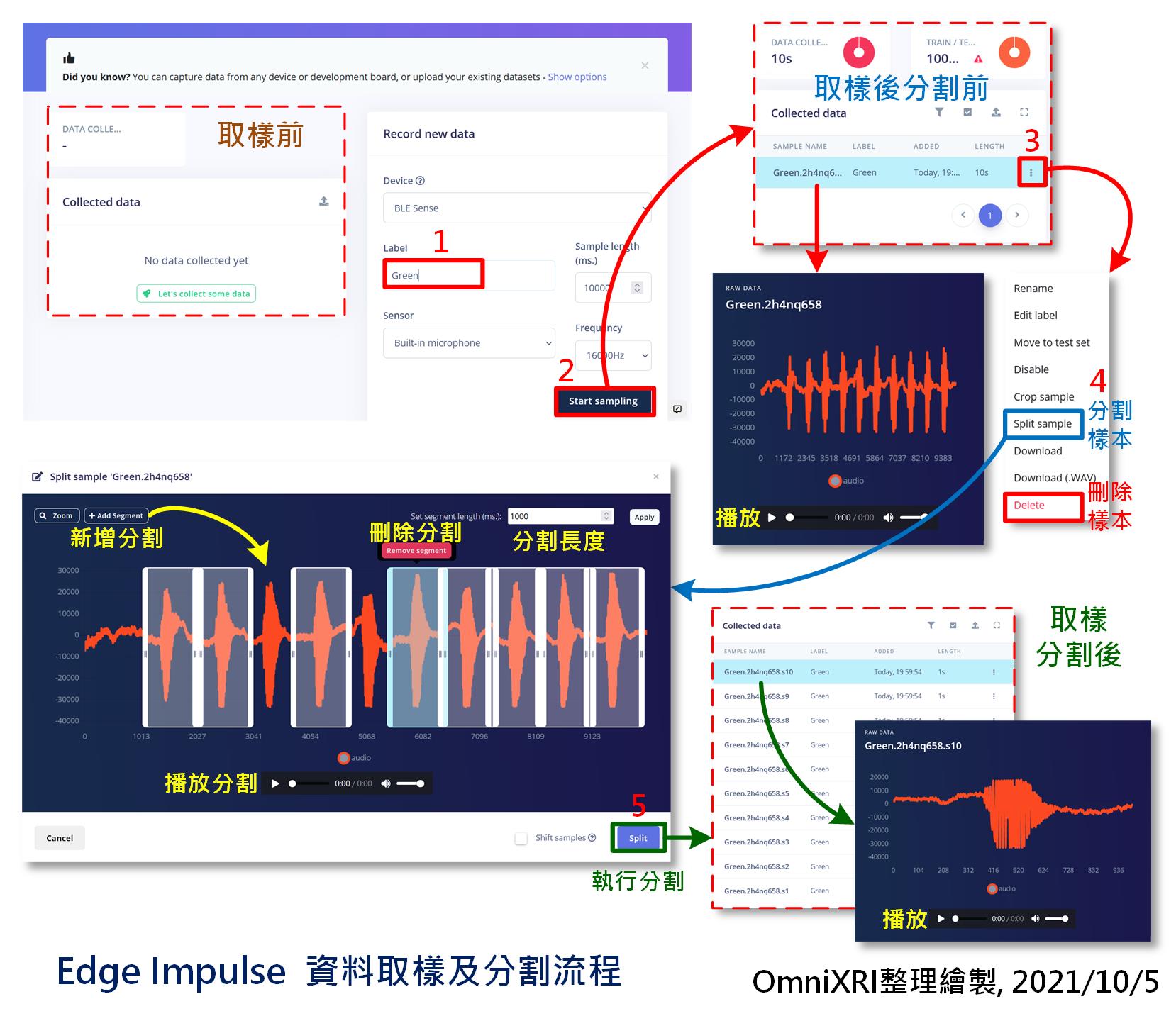
Fig. 20-3 Edge Impulse資料取樣及分割流程。(OmniXRI整理繪製, 2021/10/5)
依據Edge Impulse官方文件建議,一個標籤(Label)最好能錄個10分鐘,假設每樣本為1秒鐘,那10分鐘就有600個樣本。當然如果可能的話,可以找10個人一個人錄1分鐘,或者加入不同的背景雜音,以增加資料集的多樣性,更有利模型訓練。當然好的樣本是不嫌少,越多越好,但如果只是想練習一下,不考慮準確性,那至少每個標籤要準備個10到20筆。
最後收集完足夠的資料後,還要將資料再分成訓練集(Training data)和測試集(Test data),才算完成。通常建議訓練集80%,測試集20%,可自由調整,且每個標籤的數量要儘可能平均,不要差太多,以免後續訓練時造成有特殊傾向。分割資料集只需點擊「Collected data」右側的「打勾」符號,樣本檔案名稱左邊就會出現方框等待勾選,待勾選完後再點擊【Move to test set】就可將勾選內容搬到測試集中。若想重新調整,則可點擊頁面最上方的【Test data】就可進到測試集,進行反向操作,勾選檔案並點擊【Move to training set】即可將資料重新搬回訓練集中。
更完整的說明可參考文末連結[說明文件]。
=== 未完待續 ===
參考連結
Edge Impulse Tutorials - Responding to your voice 說明文件

