=== 書接上回 [Day 20] Edge Impulse + BLE Sense實現喚醒詞辨識(上) ===
這項功能原來英文為「Impulse design」,但翻譯成「衝動設計、驅使設計、推動設計」亦或其它,好像也有點怪,所以乾脆直接以它的作用「模型設計」來翻譯。其主要工作畫面如圖Fig. 21-1所示。接下來就介紹組成它的幾大區塊。
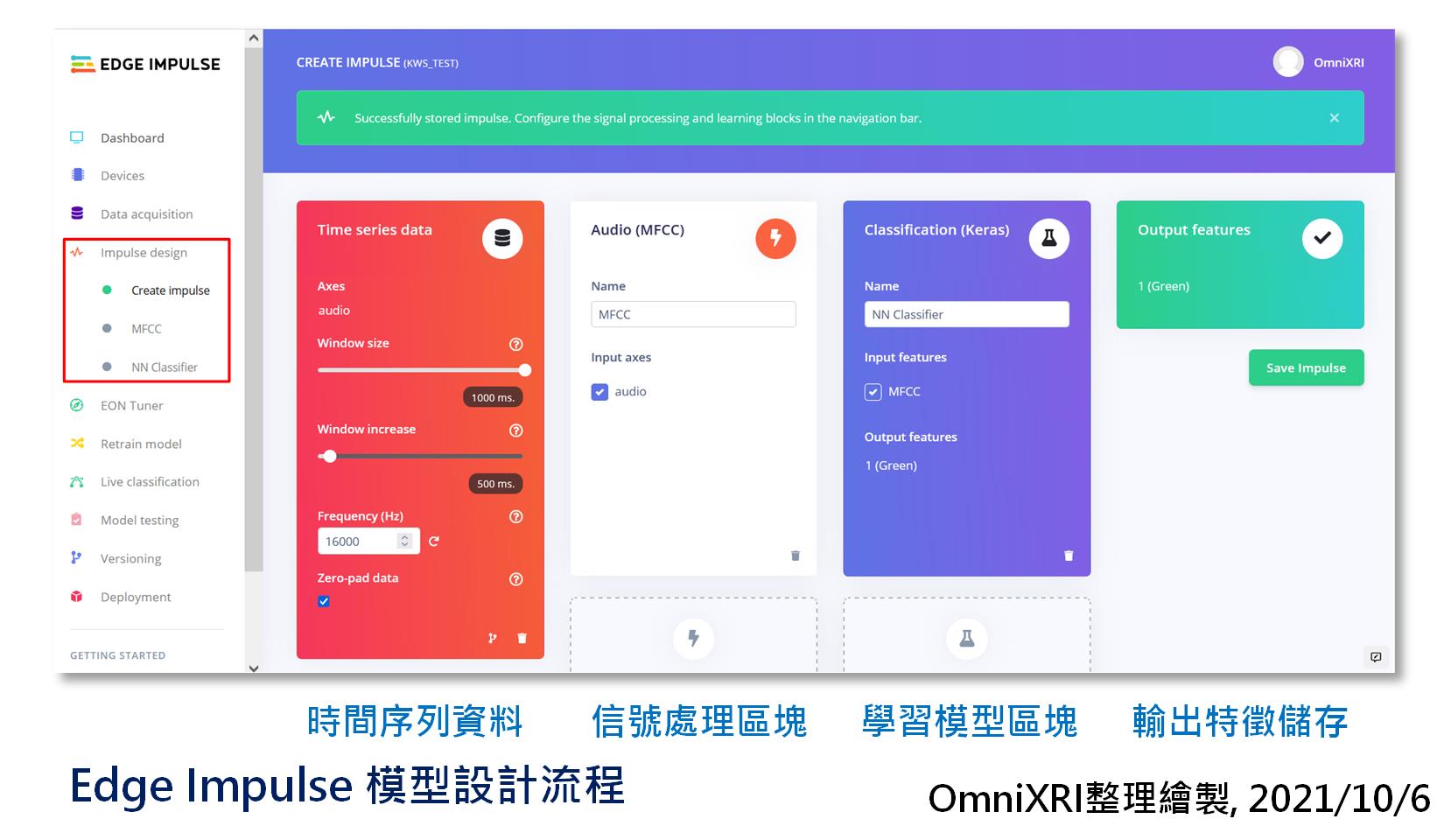
Fig. 21-1 Edge Impulse 模型設計流程。(OmniXRI整理繪製, 2021/10/6)
在這個區塊主要設定時間序列資料處理的基本參數,包括視窗大小(預設1000ms)、視窗移動遞增(預設500ms),取樣頻率(預設16KHz)及資料不足視窗大小時是否補零(Zero-pad data,預設勾選,會自動補零)。
點擊閃電符號,新增信號處理區塊(Add a processing block),即一小段信號前處理程式,可包括聲音、影像或感測器信號處理,可支援的項目如下所示。另外亦可選擇使用不處理的原始資料或自定義處理區塊。選擇時需依信號類型選擇。在這個範例中,主要是針對人類語音辨識,所以選擇「MFCC」即可。
根據維基百科「梅爾頻率倒譜係數」的說明如下。白話一點來說就是類似[Day 17]介紹過的頻譜轉換,把時間域轉成頻率域再轉成頻譜圖的作法,以提取更有用的聲音特徵出來。
在聲音處理領域中,梅爾頻率倒譜(Mel-Frequency Cepstrum)是基於聲音頻率的非線性梅爾刻度(mel scale)的對數能量頻譜的線性變換。
梅爾頻率倒譜系數 (Mel-Frequency Cepstral Coefficients,MFCCs)就是組成梅爾頻率倒譜的係數。它衍生自音訊片段的倒頻譜(cepstrum)。倒譜和梅爾頻率倒譜的區別在於,梅爾頻率倒譜的頻帶劃分是在梅爾刻度上等距劃分的,它比用於正常的對數倒頻譜中的線性間隔的頻帶更能近似人類的聽覺系統。 這樣的非線性表示,可以在多個領域中使聲音訊號有更好的表示。例如在音訊壓縮中。
梅爾頻率倒譜係數(MFCC)廣泛被應用於語音識別的功能。他們由Davis和Mermelstein在1980年代提出,並在其後持續是最先進的技術之一。在MFCC之前,線性預測係數(LPCS)和線性預測倒譜系數(LPCCs)是自動語音識別的的主流方法。
一段聲音經過MFCC轉換會圖Fig. 21-2所示。如果想檢查某一個已分割好的聲音樣本,可點選左上角下拉式選單選擇檔案。此時網頁上方就會出現原始時域信號,亦可按三角形播放鍵來聽一下內容,而下半部份的MFCC參數有需要時可進行調整,原則上可先不動它,使用預設值即可。右側就會顯示MFCC轉換後的結果及在Arduino Nano 33 BLE Sense (Arm Cortex-M4F @ 64MHz)運作時所需的時間和佔用的記憶體大小。由圖上的數據可知,將一個聲音訊號轉換成MFCC需要234ms,若再加上模型推論時間,則每秒大概只能推論2到3次,看似有點慢,但足夠用在像智慧音箱或語音控制家電的反應時間了。
另外補充一點在[Day 17]圖Fig. 17-2的單一視窗FFT結果是以橫軸(X方向)排列,而緃軸(Y方向)為時間軸,組成最後的頻譜圖(Spectrogram)(粉紅色那塊)。而這裡的頻譜圖採相反表現方式,縱向代表頻率而橫軸代表時間。從圖Fig. 21-1左下角的圖示中,大概可以看出單純的圖譜轉換和使用MFCC在特徵(比較紅的區域)表現上有明顯的差異,較有利後續模型訓練及推論。
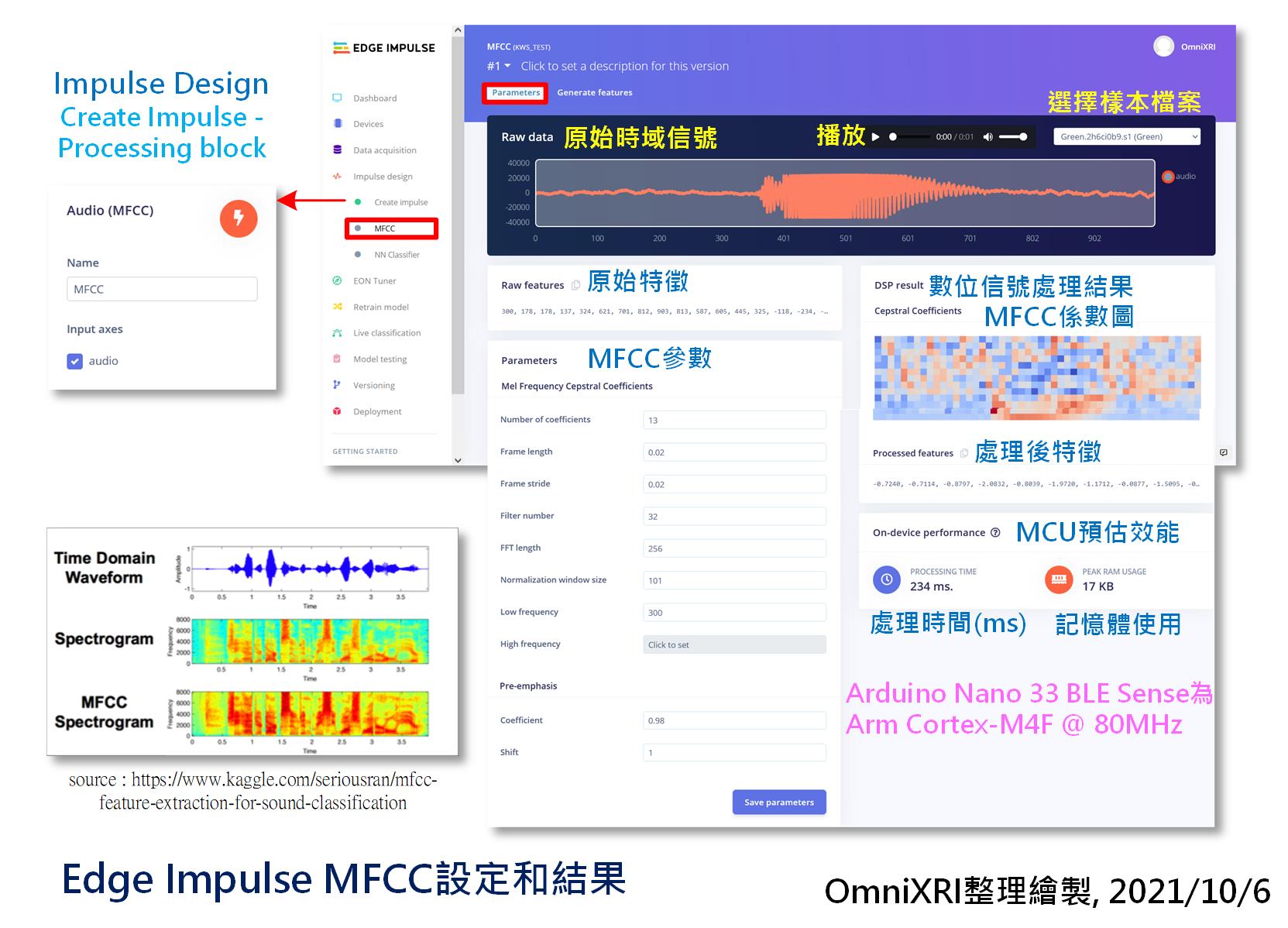
Fig. 21-2 Edge Impule MFCC設定和結果。(OmniXRI整理繪製, 2021/10/6)
接著還要從頁面上方點擊「產生特徵(Generate features)」切換頁面,如圖Fig. 21-3所示。進入後會顯示目前訓練集的基本參數,這裡準備了四個分類,背景音(BG)、紅(Red)、綠(Green)及未知(Unknow),每個分類訓練集有16個聲音檔案,而測試集則有4個,合計80個樣本。不知道如何產生資料集的朋友可以參考[Day 20] Edge Impulse + BLE Sense實現喚醒詞辨識(上)「資料擷取」小節說明。
接著再按下【Generate features】,泡杯咖啡稍等一下(資料集大的話就泡個麵或泡個澡再回來)。完成特徵提取後就會產生一個資料集三維分佈圖,可在圖上按住滑鼠左鍵上下左右移動來旋轉觀看視角,當按住滑鼠右鍵移動則為平移視窗內容,而滾動中鍵滾輪則可用來改變視圖縮放比例。從這個資料分佈圖大概可看出是否容易辨識(分割),若資料集交錯重疊的很嚴重,則後面訓練出來的準確率可能就不會太高,需要重新檢討資料集建立的方式,透過增加數量及多樣性來改善。
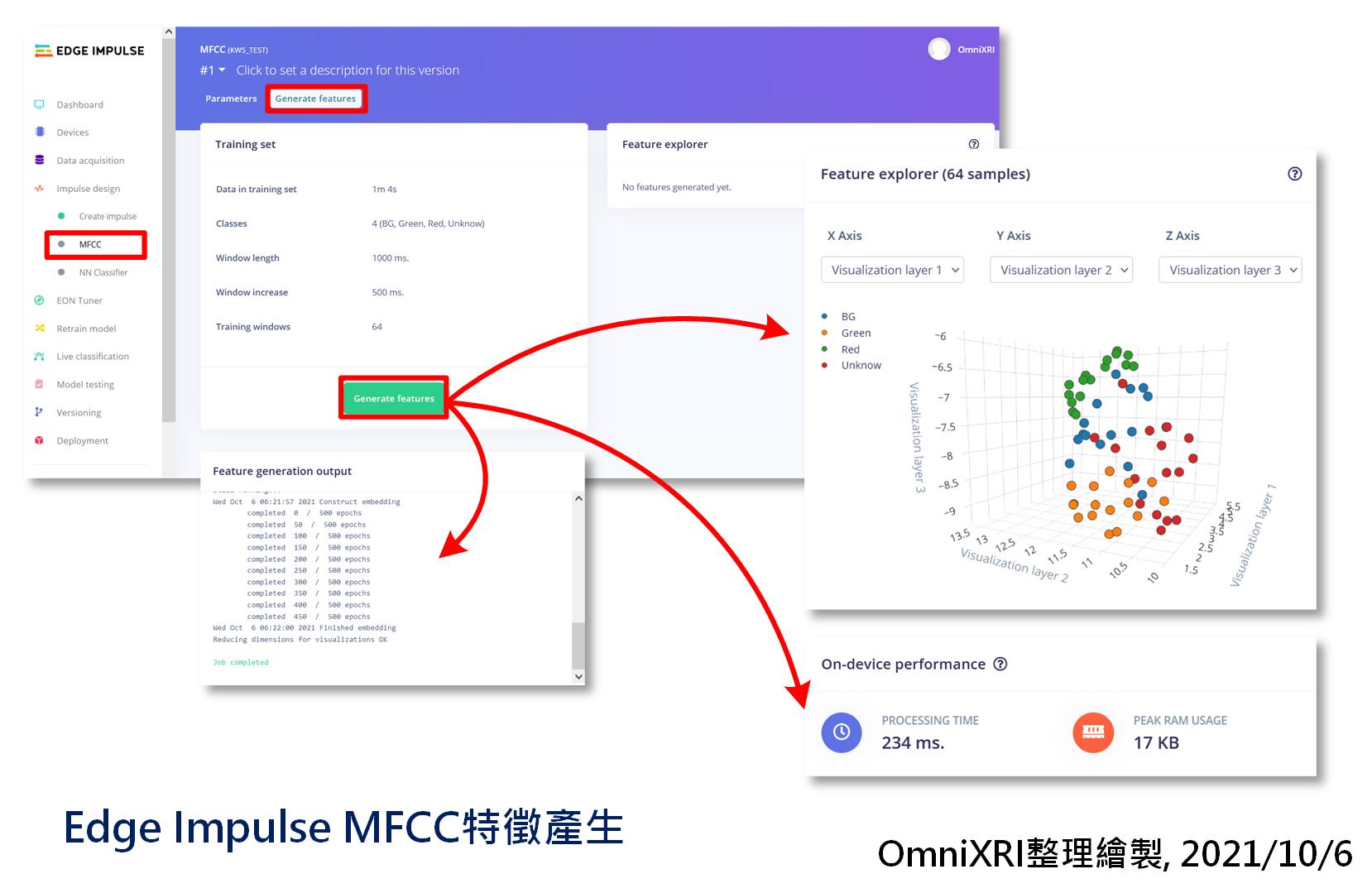
Fig. 21-3 Edge Impulse MFCC特徵產生。(OmniXRI整理繪製, 2021/10/6)
再來就是tinyML最重要的一部份,神經網路(或稱模型)的建置和訓練。進到Impulse design的頁面新增一個「學習區塊(Learning block)」,選擇「Classification(Keras)」,按下【Add】,即可產生一個新的區塊,上面顯示勾選MFCC,輸出有四個分類,如圖Fig. 21-4所示。
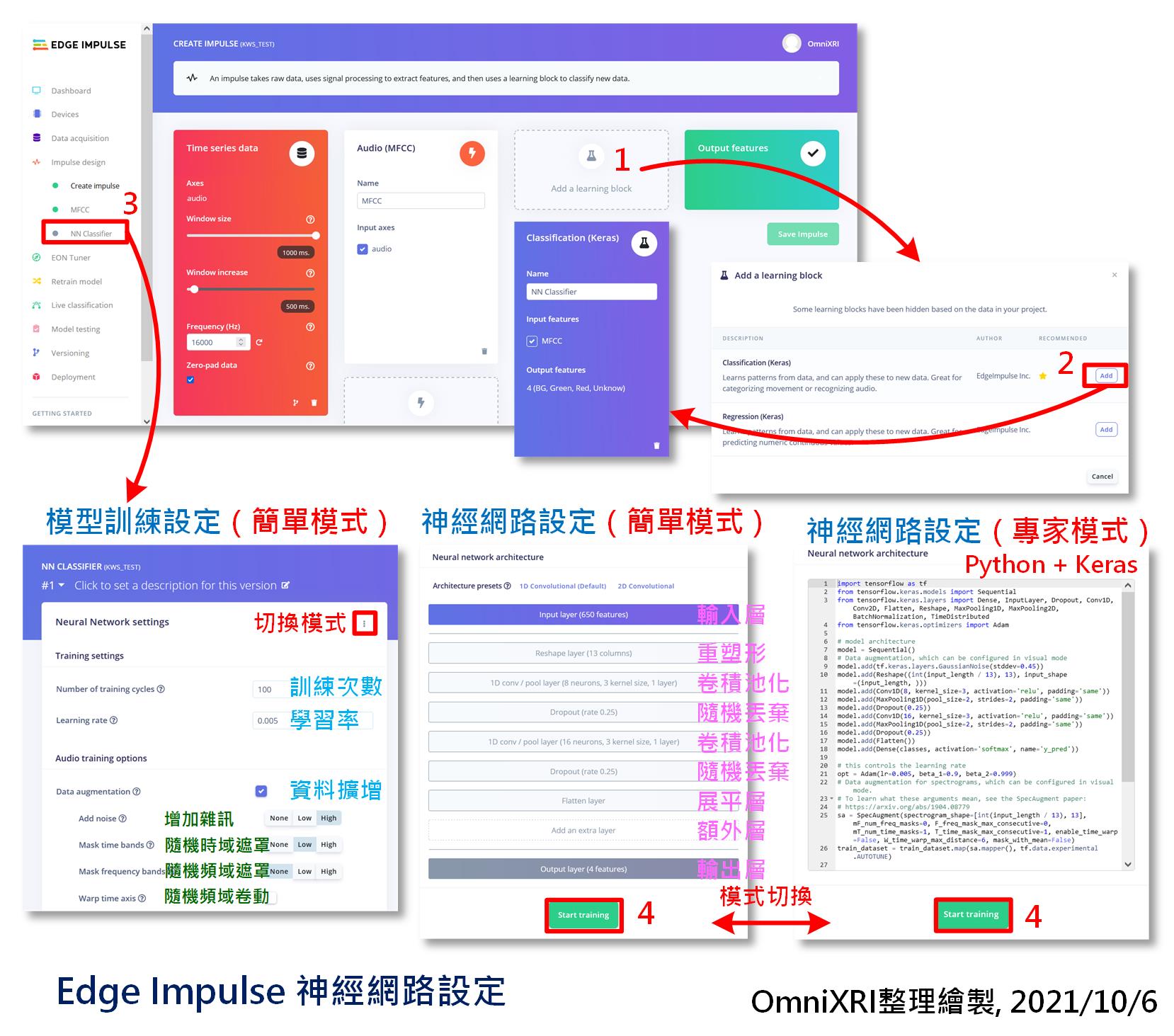
Fig. 21-4 Edge Impulse 神經網路設定。(OmniXRI整理繪製, 2021/10/6)
接著切到「NN Classifier」頁面,設定訓練次數、學習率及是否啟動聲音資料的擴增(Data Augmentation),包括增加雜訊、隨機時域/頻域的遮罩和隨機頻域卷動。如果一開始不知如何設定那就先用預設值即可。再來是設定模型的網路結構,這裡已先幫我們建好了一個,直接使用即可。若你已是熟悉Python和Keras且了解AI模型設計方式的人,也可切換到「專家模式(Expert)」直接改動程式(網路設計)即可。如圖Fig. 21-4所示。
通常使用預設的「簡單(Simple)」模式即可。它還提供一個新增額外層的項目,可選擇項目如下所示。如果對神經網路基本元素不清楚的朋友,可以到[Day 05] tinyML與卷積神經網路(CNN)復習一下。
最後按下【Start Training】就會開始訓練,這個步驟所需耗費的時間和資料集大小和模型複雜度、參數多少有直接關連。若不想等太久,可先把訓練次數調小一點,看看輸出結果是否有變好趨勢。如果有,只是推論精準度不足,那就把訓練次數加大,以提高精準度。待訓練完成後,會產生準確率(Accuracy)、損失值(Loss)、混淆矩陣(Confusion Matrix)、特徵提取(Features Expolorer)分佈及預計佈署在MCU上後推論時間(Inference Time)、記憶體使用峰值(Peak RAM Usage)及程式碼(模型結構及參數)使用量(Flash Usage)。如圖Fig. 21-5所示。至於訓練結果好壞及調整方式就留待後面章節再行說明。
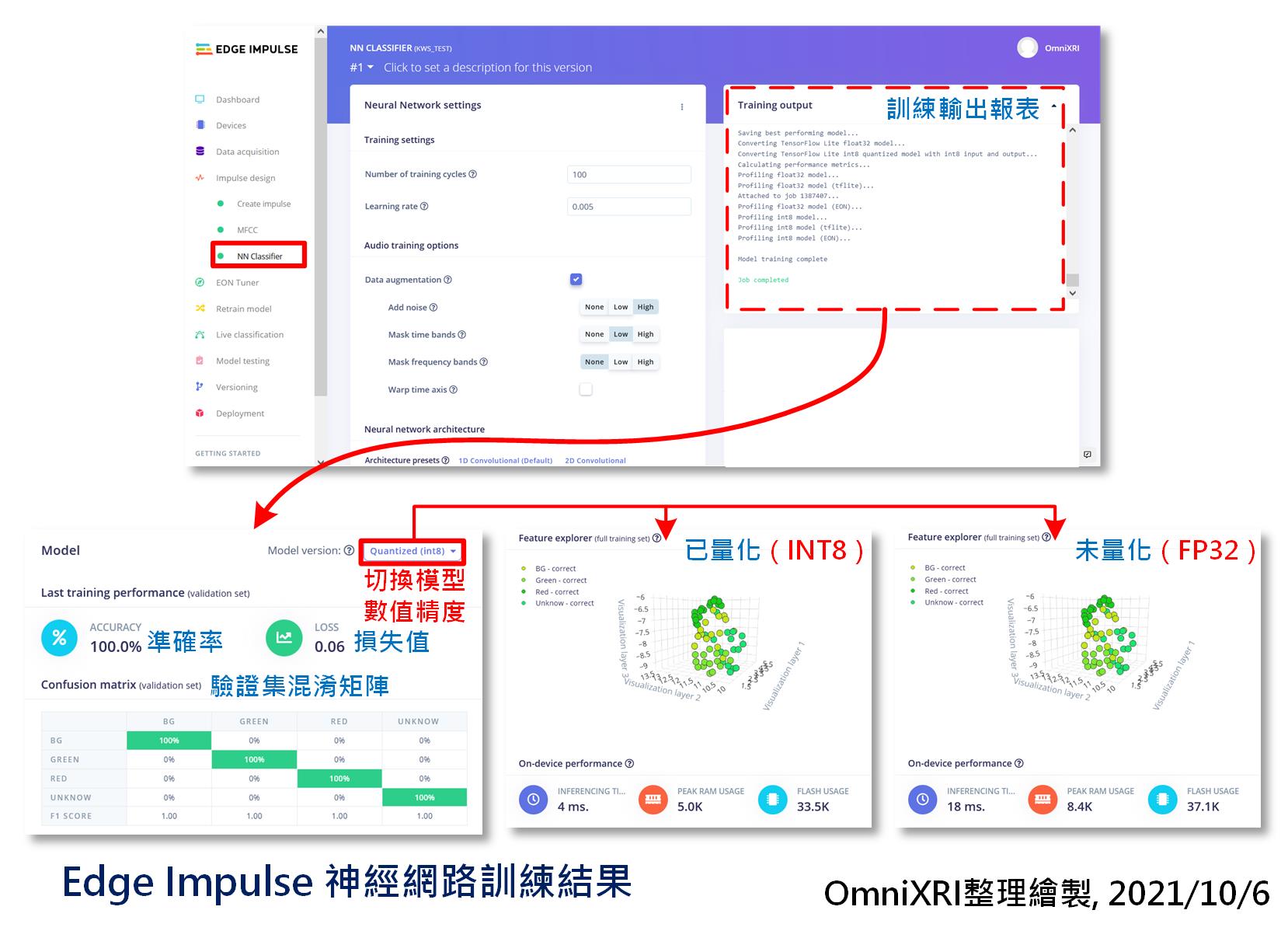
Fig. 21-5 Edge Impulse神經網路訓練結果。(OmniXRI整理繪製, 2021/10/6)
另外系統預設會使用INT8(8bit整數)方式進行量化(優化),若想切回FP32(32bit單精度浮點數)原始訓練結果來提升一點準確度,則可自行切換,如圖Fig. 21-5所示,系統會自動重新算出MCU所需資源,方便評估是否滿足推論速度及超出MCU硬體規格需求。但要注意的是,如果是不支援浮點數計算或者單指令週期浮點數指令的MCU,那推論時間可能就會大幅增加。以這個案例舉例,MFCC轉換花了234ms,INT8推論用了4ms,加上其它一些IO或通訊所需,合計應該不會超過250ms,換算後大約1秒可取樣辨識4次結果,算是很OK的速度了。
在「Impulse design」這個頁面最右邊的選項,基本上並沒任何動作,按下【Save Impulse】就完成初步工作。
看到這裡有沒有覺得[Day 17] TFLM + BLE Sense + MP34DT05 就成了迷你智慧音箱(下)所提及的聲音資料採集、分割、分群(訓練/驗證/測試集)、信號處理、頻譜轉換、模型選用、訓練等工作都變簡單了,這裡不用寫半行程式,也不用使用額外工具,一口氣就全部完成了。如果前面有被勸退跳過課程的朋友可自行回補一下,應該會更容易看懂。
=== 話多了點,還得再一篇才說得完,敬請期待 ===
參考連結
Edge Impulse Tutorials - Responding to your voice 說明文件
Edge Impulse Tutorials - Processing blocks 說明文件

