前言:講解完了基礎的排序法後,接著要來講解比較高等的排序法,今天和明天要介紹的都是始於分割資料的排序法,就先從快速排序開始講起。
分割資料的排序法:這類型的排序法,主要是用**「各個擊破」(Divide-and-Conquer)的分治演算法**,這種演算法是將排序問題分割成多個小問題,在使用遞迴的方式逐一解決各個子問題後所完成的排序法。
是目前公認最佳的排序法,雖然和基礎的氣泡排序一樣,都是採用交換的方式進行排序,但是透過分割的技巧,使得快速排序的執行效率遠大於氣泡排序。
分割資料的方式是選擇一個鍵值作為分割標準,將鍵值分成兩半的兩個集合,一半是比標準值還要大的鍵值集合,另一半是較小或相等的集合。
接著每一半的鍵值使用相同的分割法,直到無法繼續分割,此時所有的鍵值以排序完成。
如何挑選基準值?常用的分式可以取亂數或是取數列的最左或最右邊,也可以用比較進階的方式,取數列的第一、中間和最後一個數,取第二大的當基準值也可以。

因為快速排序需要使用遞迴函式,所以要有額外的記憶體空間來處理遞迴方法。屬於不穩定的排序法,因為排序元素會進行分割和交換,所以有可能會交換到相同鍵值的元素。
快速排序實作: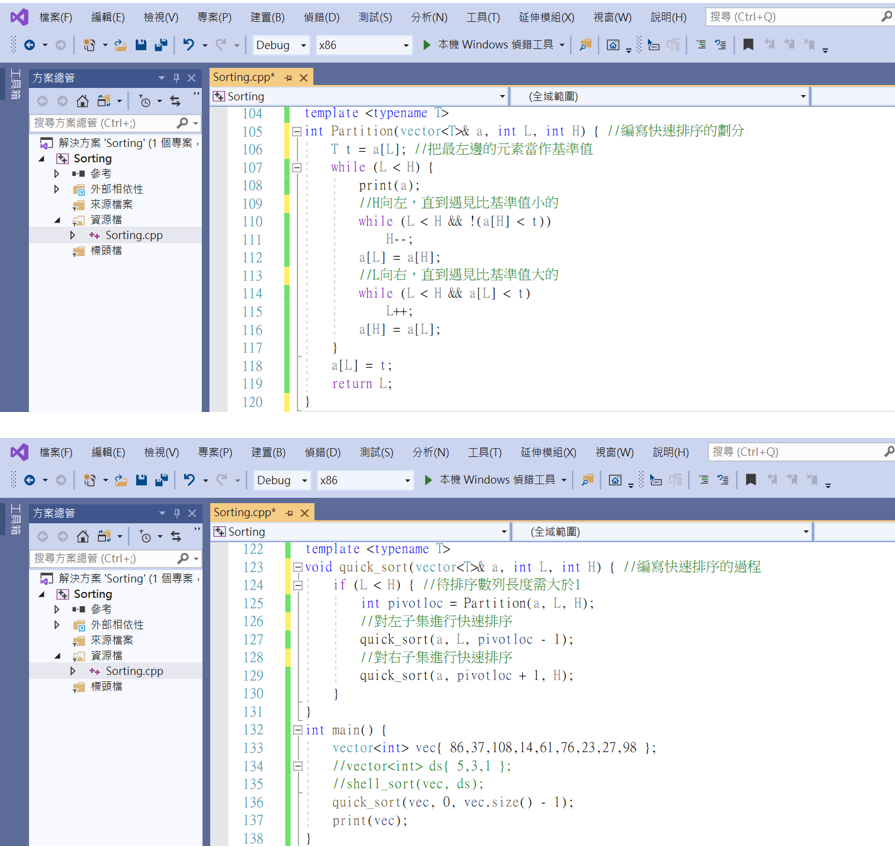
這樣就完成了!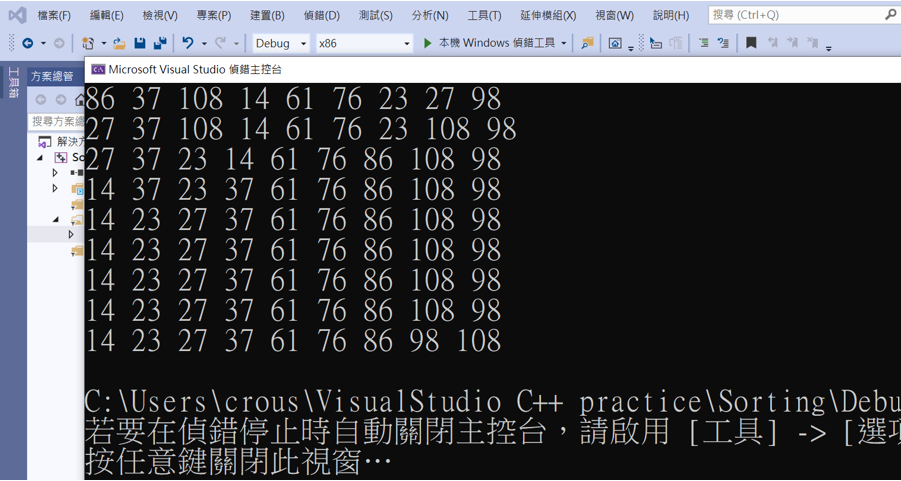
本日小結:快速排序雖然是很有效率的排序法,不過很顯而易見的並沒有像基礎排序法那樣的直觀簡單好理解,而且如果遇到最糟的情況下會慢上很多,但快速排序依舊是非常重要的,還是學起來會比較好,明天要介紹同樣為分割排序「合併排序法」Ꮚ^ꈊ^Ꮚ
template <typename T>
int Partition(vector<T>& a, int L, int H) { //編寫快速排序的劃分
T t = a[L]; //把最左邊的元素當作基準值
while (L < H) {
print(a);
//H向左,直到遇見比基準值小的
while (L < H && !(a[H] < t))
H--;
a[L] = a[H];
//L向右,直到遇見比基準值大的
while (L < H && a[L] < t)
L++;
a[H] = a[L];
}
a[L] = t;
return L;
}
template <typename T>
void quick_sort(vector<T>& a, int L, int H) { //編寫快速排序的過程
if (L < H) { //待排序數列長度需大於1
int pivotloc = Partition(a, L, H);
//對左子集進行快速排序
quick_sort(a, L, pivotloc - 1);
//對右子集進行快速排序
quick_sort(a, pivotloc + 1, H);
}
}

