在前一天的內容中,我們介紹 Instagram 為了推薦用戶其他公眾帳號,設計三個工具以節省運算資源、快速找到相似帳號。此三工具分別為:IGQL、account embeddings 和 ranking distillation model。
今天,我們一起來探討 Instagram 如何使用這些工具,以設計推薦演算法吧!
如 Day 2 的文章 所言,推薦系統分為兩個階段:candidate generation and candidate selection,不過 Instagram 稱第二階段為 ranking,在本篇文中我們會沿用他們的習慣。
因此,Explore 這個推薦頁面,分為兩階段的方法實作:
(1) The candidate generation stage (aka sourcing stage)
(2) The ranking stage (aka candidate selection stage)
第一步:Instagram 利用用戶互動過的帳號當作種子帳號(seed accounts)。
e.g., Skylar 追蹤 Athena 的帳號,將 Athena 當作種子帳號。
第二步:利用這些種子帳號的 account embeddings,找尋相似的帳號。
e.g., 利用種子帳號 Athena,找到相似的帳號 Claire。
第三步:根據找到的帳號,再進一步找尋這些帳號發的文、或互動過的貼文內容,作為候選清單。
e.g., 無論是 Claire 發過的貼文,如他的烹飪教學,或是 Claire 曾經按讚過 Jenny 的食譜貼文,都全部納入候選清單。

回憶前一篇提過的內容,account embeddings 的算法是藉由 ig2vec。
在 Instagram 上,主要有兩大類特徵,可作為篩選貼文的參考。
除了過濾出用戶可能會感興趣的內容外,Instagram 也會利用 ML 模型,排除不適合的內容,如詐騙貼文。
經過 candidate generation 後,會抽出 500 則內容作為候選清單,再藉由三階段排序的方式,以節省運算資源。
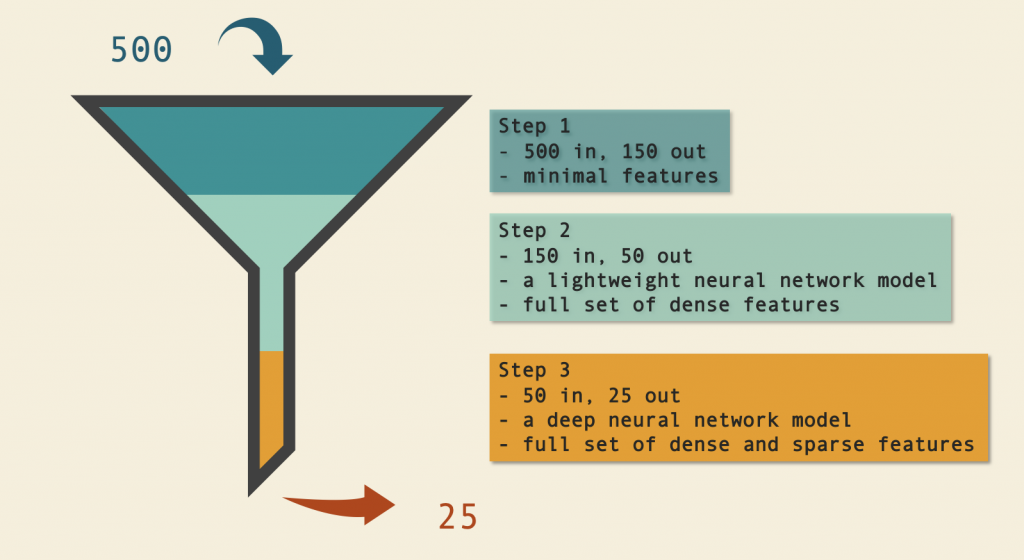
為了選擇和用戶最相關的貼文,Instagram 使用 value model 計算每則內容的分數。他們採用 multi-task multi-label (MTML) neural network 預測用戶的行為,包含正面行為如按讚、儲存;負面行為如「減少顯示這類貼文」。在預測模型中,所有輸入會共享一層 MLP,以捕捉共同的訊號。

經由此模型計算,會得到不同行為的預測值,再藉由 value model 加權計算,得到最終的數值,作為排序貼文的參考。
Value model 的公式為 w_like * P(Like) + w_save * P(Save) - w_negative_action * P(Negative Action)。
最後,為了避免用戶一直看到相似內容,在 value model 中,相同帳號或來自於同一個 seed account 的貼文會加上 penalty factor,讓使用者能夠多接觸到不同內容。
好的,以上就是 Instagram 在 Explore 頁面做的所有努力,希望大家喜歡,我們明天見!
謝謝讀到最後的你,如果喜歡這系列,別忘了按下訂閱,才不會錯過最新更新,也可以按讚給我鼓勵唷!
並歡迎到我的 medium 逛逛!
Reference:


 iThome鐵人賽
iThome鐵人賽