「孩兒,你看清楚了沒有?」「看清楚了」
「都記得了沒有?」「已忘記了一小半。」
「現下怎樣了?」「已忘記了一大半。」
「好,我再使一遍。」
「孩兒,怎樣啦?」「還有三招沒忘記。」
「這我可全忘了,忘得乾乾淨淨的了。」
張無忌、張三丰《倚天屠龍記》
前面講了這麼多,終於要講模型了嗎?我們這十天一起度過的旅程,目的只有一個,就是將文本資料轉化成數值資料。因為機器學習模型沒有辦法透過文字資料進行學習,唯有將其轉成數值資料,模型才有辦法從這些數字中學習洞見。前面所學都是非常重要的基礎,我認為要打好這些基礎,再來學習後面的機器學習的模型才有意義。就像是武俠小說中,渾厚內力才能帶來強大武功,若沒有強大的內力,即便你會九陽神功、九陰真經、降龍十八掌,也只是空有華麗的外殼、空虛的內在;像是死神中,強大的個體都帶有很強的靈壓,若靈壓不夠強,即便你所擁有的是規則殺的能力,在強大的靈壓面前都是毫無用處的。

今天的文章,你可以帶走這些機器學習的基本知識:
想像今天你有一份已經經過完善的前處理、以及正常的正規化,也就是可以直接丟進去模型的完整資料集。一般來說,我們會將資料集依照比例分成兩份:一份訓練資料集(training set)、一份測試資料集(test set),而這個比例有時候是8:2,有時候是7:3,依照個人配置會有所不同,沒有絕對的正確答案。首先,先給予機器學習模型訓練資料集,讓模型學習資料中的特徵,接著再給訓練好的模型進行考試,以模型預測測試資料集的目標資料(例如正負面評論),並將這些答案與原始資料的「正確答案」(Golden label)進行比對。
若是碰到資料量較小的狀況,抑或是你的資料極度不平衡的情況,就要對資料進行交叉驗證。所謂的交叉驗證就是,除了前面所提到的訓練資料集、測試資料集、還會再多分出新的一部分的開發測試資料集。首先會將資料集分成k個,然後選其中一部分做為剛剛多分出來的開發測試資料集,並以另外k-1份的資料集作為訓練資料集,並計算準確率,接著再從那k份資料中選擇下一份資料作為開發測試資料集,直到所有的資料集都已經輪過後,再以這份模型去測試測試資料集。

我們剛剛說到,模型預測之後,要與正確答案(Golden Label)進行比對。那麼該怎麼呈現這個比對結果,來決定一個模型的表現好壞呢?我們可以先來看以下這張圖:
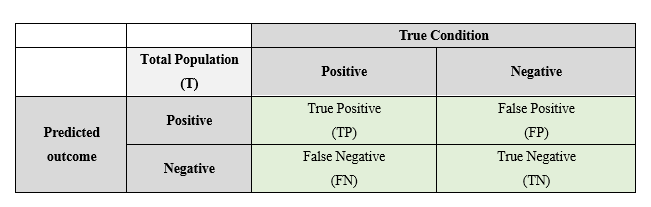
假如模型預測A文本是正面評價,與正確答案相符,那麼我們就會將其納入true positive;假如模型預測B文本是負面評價,正確答案也標記為負面評價,那麼就屬於true negative;假如模型預測C文本是正面評價,但正確答案卻是負面評價,那麼就屬於false positive;若模型判斷D文本是負面評價,但事實上卻是正面評價時,就屬於false negative。
接著就會產生了以下四種衡量的方式:

在做二元分類時,可以透過以上的表格來衡量模型,這矩陣也稱為confusion matrix。而我們可以這麼理解這些指標:
我們可以透過這個比喻來理解何謂生成式模型,何謂判別式模型。假如說我們今天需要模型判別圖片中的動物是貓貓還是狗狗,生成式模型會先透過訓練資料的照片學習狗與貓的 整體大致長相 ,接著在測試資料的照片判斷圖中的動物比較接近貓貓還是狗狗,最後再下判斷。判別式模型則是透過照片學習貓貓有哪些特徵、狗狗有哪些特徵,例如貓貓有長鬍鬚,狗狗較常吐舌頭,接著再在新圖片中觀察是否有這些觀察到的特徵。
所以我們大致上可以這麼解釋:
好,大致上就是這樣,我們接下來就可以進入機器學習的領域啦!剩下二十天,一起加油!

