昨天 Skylar 訂完露營和烤肉用具後,今天他想在 Airbnb 上搜尋適合渡假的房源,而當他在瀏覽時,Airbnb 是如何排序出 Skylar 看到的頁面呢?
不知道大家會不會好奇,在 Google 學術搜尋中,隨便輸入一個關鍵字(如「推薦系統(Recommendation System)」,都有成千上萬種結果。究竟一間大公司(如 Airbnb)在建立自己的機器學習模型時,是如何參考前輩的文獻,抑或是從頭到尾自己手刻呢?
Airbnb 的平台上,同時間會有非常多的預測模型在執行,例如預測屋主是否會接受房客的預定、房客是否會評高分、房源的排序等等。每個模型都有五花八門的演算法可供挑選,從最簡單的純 ML 模型,到開始使用較少層數的簡單類神經網絡(Neural Network, NN)、Lambdarank NN,再到 Gradient Boosted Decision Tree (GBDT)(GBDT 的概念可參考這篇文章),最後到多層的深度類神經網絡(Deep Neural Network)。
Airbnb 在挑選模型時,會參考文獻、實作,並使用 A/B testing 測試不同模型的表現。然而,時間久了,他們發現模型沒有特別進步。所謂的 deep learning 是什麼呢?最直觀的想法似乎就是多加幾層神經網絡,但是在研讀各大文獻、加上不同層數後,表現並無特別起色。
因此,他們決定跳脫「讀文獻 -> 實作 -> A/B testing」的迴圈,提出「ABCD 改善方案」,此方案的內容如下所示:
不過,在認識 ABCD 改善方案之前,我們需要先認識一個評量排序清單優劣的指標 -- NDCG。Airbnb 的系列會花三篇文章介紹:NDCG、AB 方案 和 CD 方案。
想要更認識 Airbnb 的房源排序方式嗎?讓我們開始吧!
NDCG 的全名是 Normalized Discounted Cumulative Gain,是用以衡量一個排序的準確性,主要的核心概念有兩個:
換句話說,我們會希望較高相關的物件可能排名在越前面越好,且此時的 NDCG 分數會比較高。藉由 NDCG,我們可以比較兩個不同排序清單的優劣。
要計算 NDCG 的話,需要先認識兩個數值:CG 和 DCG。
只考慮每個物件關聯性的分數(rel)總和,不考慮位置。
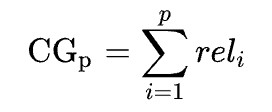
例如一個清單中有六個物品:ABCDEF,其關聯分數分別對應如下:
|x|A|B|C|D|E|F|
|--|--|--|--|--|--|
|rel|3|2|3|0|1|2|
這個清單的 CG = 3 + 2 + 3 + 0 + 1 + 2 = 11
無論最後清單的順序是 ACBFED 或是 DEFBCA,CG 分數都一樣。但是這樣的結果很奇怪,因為第一個清單是最理想的狀況,關聯分數從高排到低;第二種排法(DEFBCA)卻是從低分排到高分,不是一個很好的排法。
為了改善此問題,提出 DCG 的概念。
DCG 的概念將位置 i 資訊納入考量,將每個關聯分數(rel)除以折損分數 log_2(i+1),排名越前面者,分母越小,損失越少。其目的就是讓排名前面的物件價值越高,而排名往後的物件價值較低。
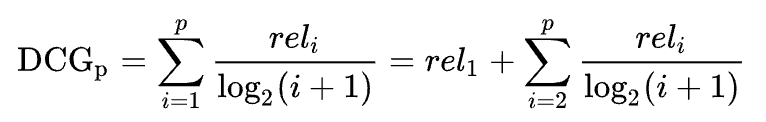
以同樣的六個物品為例:
|x|A|B|C|D|E|F|
|--|--|--|--|--|--|
|rel|3|2|3|0|1|2|
考量兩種不同的排序方式:
(1) ACBFED
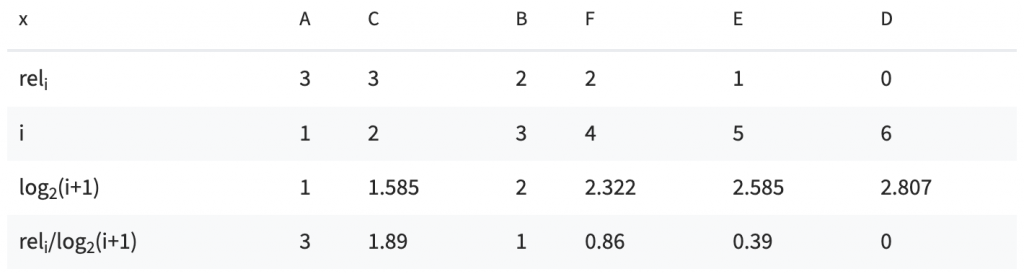
DCG = 7.14
(2) DEFBCA
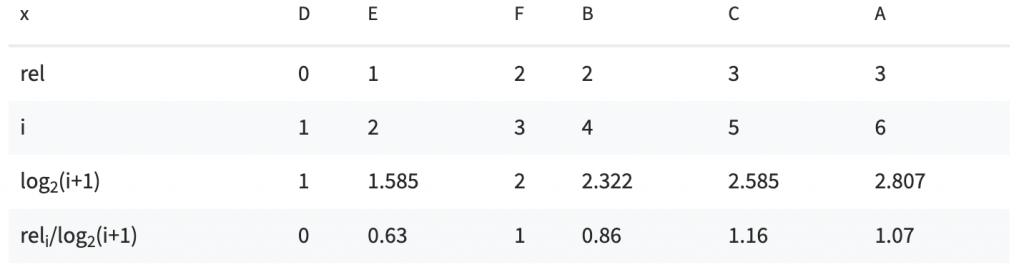
DCG = 4.72
由上述的兩個表格,可以很明顯地看到排名越後者,由於折損項的影響,影響分數越小。而兩種排序方式孰優孰劣,也能夠明確地從 DCG 看到。
那為什麼還需要 NDCG 呢?
NDCG 比 DCG 多一個 N,意思是正規化 normalized。因為不同模型、不同情境下產生排序清單的長度可能不一致,為了比較不同長度的清單,需要將所有清單有一個統一比較的標準。
算法很簡單,只要將每個清單的 DCG 除以 IDCG 即可。IDCG 是在最理想情況下的物品排序,並只取前 p 個物品,因此每個清單的長度都為 p。
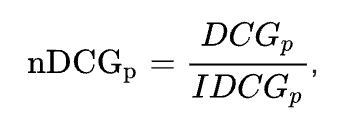
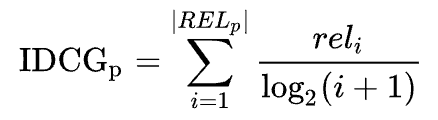
回到上例,假設清單多了兩項物品 G 和 H,其關聯分數(rel)分別為 3 和 0,其最理想的排序方式則為:ACGBFE。
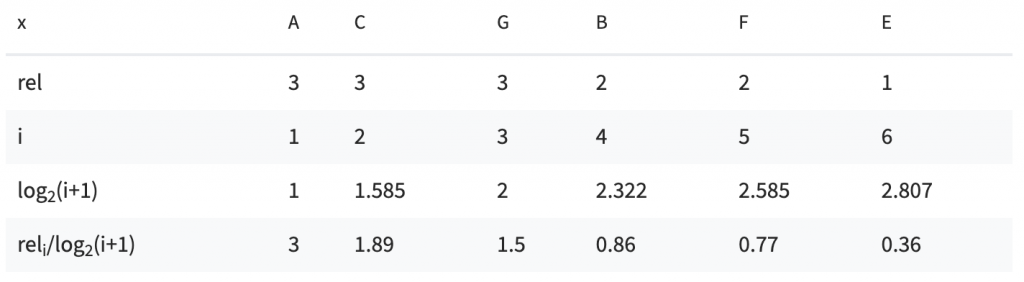
IDCG_6 = 8.38
而 ACBFED 此清單的 NDCG_6 = 7.14 / 8.38 = 85%,因此跟 ACGBFE 相比,後者的分數較高。
我們可以藉由 NDCG 比較不同搜尋結果、不同長度的排序清單,藉此選擇最適合的排序模型。
好的,我們知道要如何比較各種房源排序清單的好壞,進而知道要如何評斷不同模型。明天會介紹 Airbnb 在排序房源時遇到的問題,以及如何解決。
謝謝讀到最後的你,如果喜歡這系列,別忘了按下喜歡和訂閱,才不會錯過最新更新。
也歡迎到我的 medium 逛逛!
Reference:

