在昨天的文章中,我們提到 Airbnb 為了做出更好的房源排序模型,決定跳脫「讀文獻 -> 實作 -> A/B testing」的迴圈,提出「ABCD 改善方案」:
今天,讓我們來細探 A 和 B 分別代表什麼問題,又是怎麼解決的吧!
為了得到更好的模型,他們認為最好的方式是直接觀察使用者的需求,遵循「users lead, model follows」的原則。這句話的核心概念是:觀察並量化用戶的問題,藉此修改模型,以回應此問題。
以房源排序模型為例,當他們在測試各種版本的排序模型(ranking model)時,發現能夠增加用戶實際訂購量的模型,其產出的排序清單之平均房價也較低。這些所謂的成功模型,其預測結果會朝向顧客的偏好靠攏。
因此,他們假設用戶的需求是「傾向訂購更經濟實惠的選項」,並繪製 Fig 1 的圖形觀察被訂購的房源價格和搜尋價格中位數的差異。結果顯示多數用戶集中於圖形左半邊,意即用戶的確是偏好較低的房價。
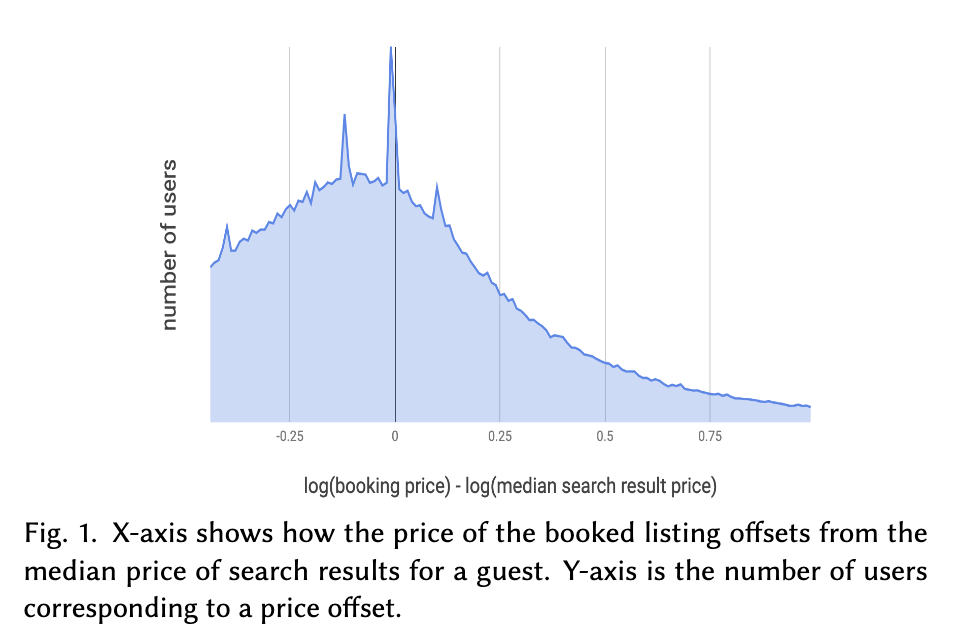
然而,他們不敢確定模型是否懂這個「便宜即是好(cheaper is better)」的原則,因此著手研究是否價格較低的物件需要有較高的排序順位。他們設計一套新的模型,讓模型強化「便宜即是好(cheaper is better)」的條件。但是,儘管搜尋結果的價格下降 -5.7%,訂房率卻也慘痛地下降 1.5%。
為什麼會失敗呢?他們不是聆聽使用者的需求了嗎?
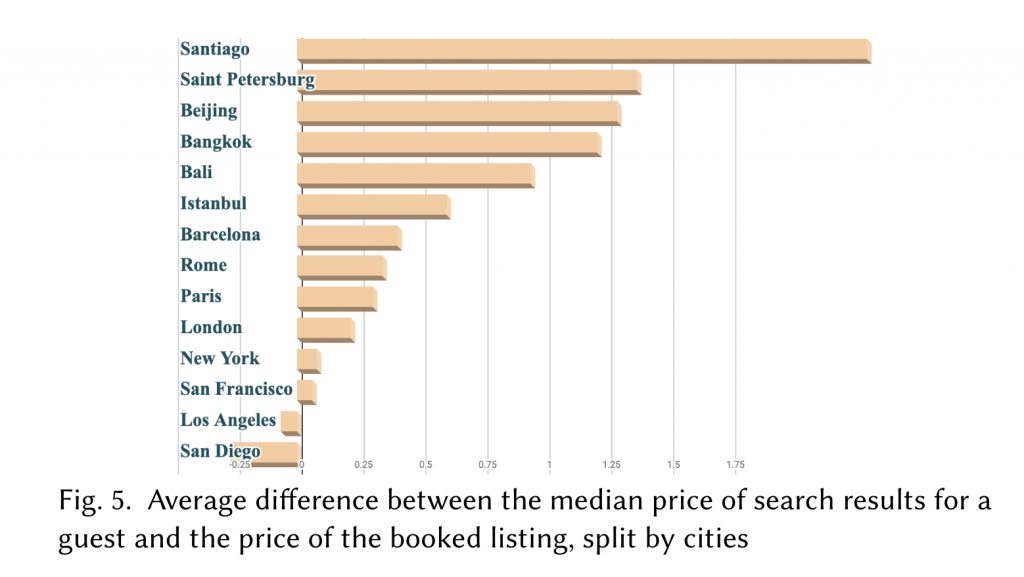
原因是儘管價格的確是消費者的考量重點,但是何謂「正確的旅遊價格」?並非越便宜越好,也要考慮到旅遊地點和消費者本身的特徵。如下圖所示,不同旅遊城市的「搜尋清單的房價中位數」和「被訂購房源的房價中位數」差異都不同,因此不能單單只是推薦便宜的房型,也要考慮用戶特徵和搜尋的旅遊地點。
最後,設計出一套稱為「雙塔模型(two tower architecture)」的模型架構,如下圖所示。
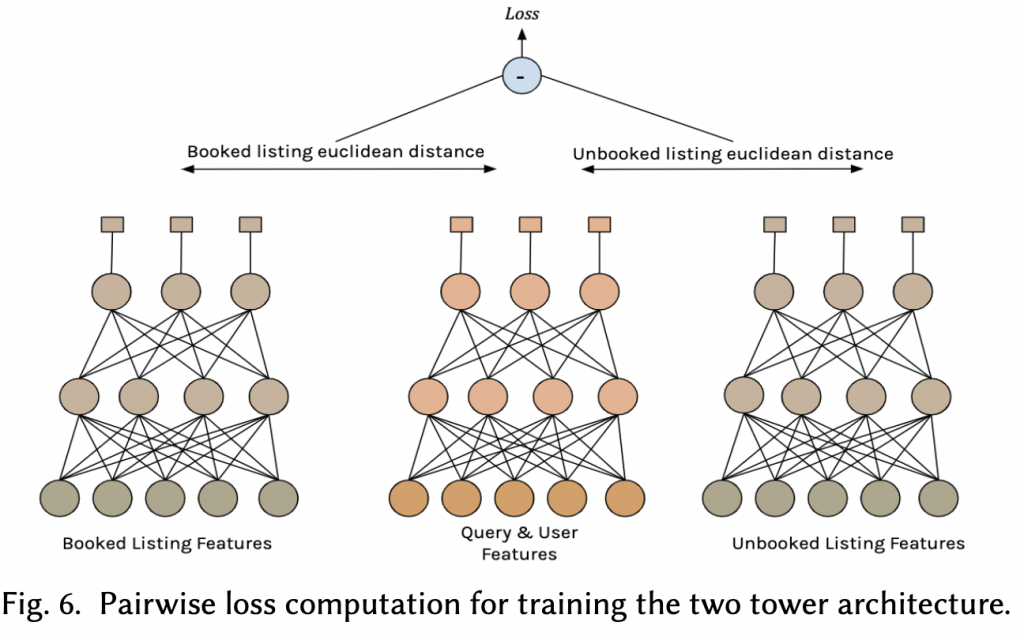
第一座塔(中間)輸入用戶特徵(user features)和搜尋內容(query features)至一個一百維的兩層的全連結網路(fully connected),預測對於此用戶和搜尋內容結合,最適合的房源排序。第二座塔的輸入為房源排序的特徵,而訓練資料會是有訂購的房源(左塔)和沒有訂購的房源(右塔)配對。
在訓練時,希望第一座塔(中間)和左塔(訂購房源)的距離越小越好,而和右塔(未訂購房源)的距離越大越好。
在使用新的模型架構後,訂購的房源數量增加了 0.6%。
Airbnb 在觀察頁面時,發現某些房源的排序會比模型預測的還低,例如一些小旅館,或是傳統的 B&B 形式的客房。這些房源的供給雖然在近年來迅速增加,然而排名卻不如預期。
資料科學家提出一個假設,認為也許這一類的房源在以前的清單中較少出現,因此在訓練資料中被低估,因此被排序在叫後面。而因為排名較後、比較不會被使用者看到並訂購,惡性循環下導致其排名不斷落後。
以用戶(user, u)執行一次搜尋(query, q),看到一組房源排序(listing l)為例,此頁面的產生可以被解構成兩個原因:
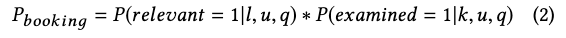
而當使用這兩個機率結合的公式去訓練模型時,模型會不斷地學到被舊有排序影響的資料,使一些在底層的房源永不得翻身。
為了解決這個偏誤,Airbnb 將位置當作訓練模型時使用的其中一個特徵,並使用 0.15 的 dropout rate。結果顯示此解法的確能夠改善此問題,在 online A/B testing 時觀察到訂房率增加 0.7%,且收益增加 1.8%。特別是原本排序較低的小旅館,其訂房率增加 1.1%。
以上是 Airbnb 發現的兩個問題,和相對應的解法。明天再回來看看 C 和 D 分別對應什麼問題,以及如何解決吧!
謝謝讀到最後的你,如果喜歡這系列,別忘了按下喜歡和訂閱,才不會錯過最新更新。
也歡迎到我的 medium 逛逛!
Reference:

