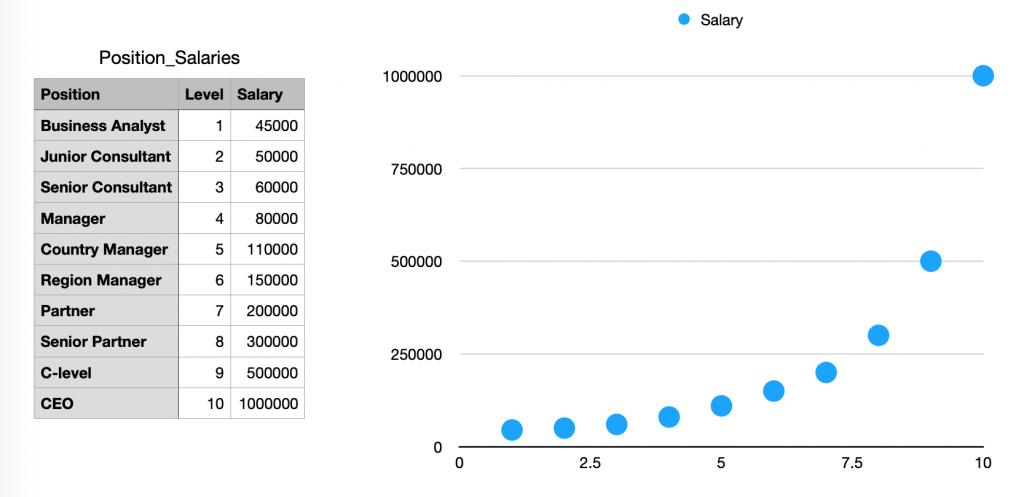
左邊是我們今天要處理的資料範例
今天的故事是A公司HR想要知道某位面試者說他在前公司的薪資是160000的真實性有多高
於是他想利用machine learning 來分析手邊現有B公司的薪資表, 看看算出來的薪資是否如
面試者所說的一樣高(已知面試者在B公司大約level=6.5)
我們從右邊的圖可以發現 Position & Level 並不是線性的
因此我們預備利用多項式是回歸來擬合
在進行擬合之前需要決定自變數與應變數是什麼
看一下table 會發現 Position 其實就相當於level(因為一個position 對應一個level)
所以自變量x = Level, 應變量y = Salary
接著開始來做資料前處理
dataset.iloc[:,1].values 表示取出Level 當作x
dataset.iloc[:, 2].values 表示取出Salary 當作y
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
# Importing the dataset
dataset = pd.read_csv('Position_Salaries.csv')
x = dataset.iloc[:, 1].values
y = dataset.iloc[:, 2].values
然後執行程式後可以發現
x size = (10,) 代表這是一個向量不是矩陣
但是x應該要是矩陣才行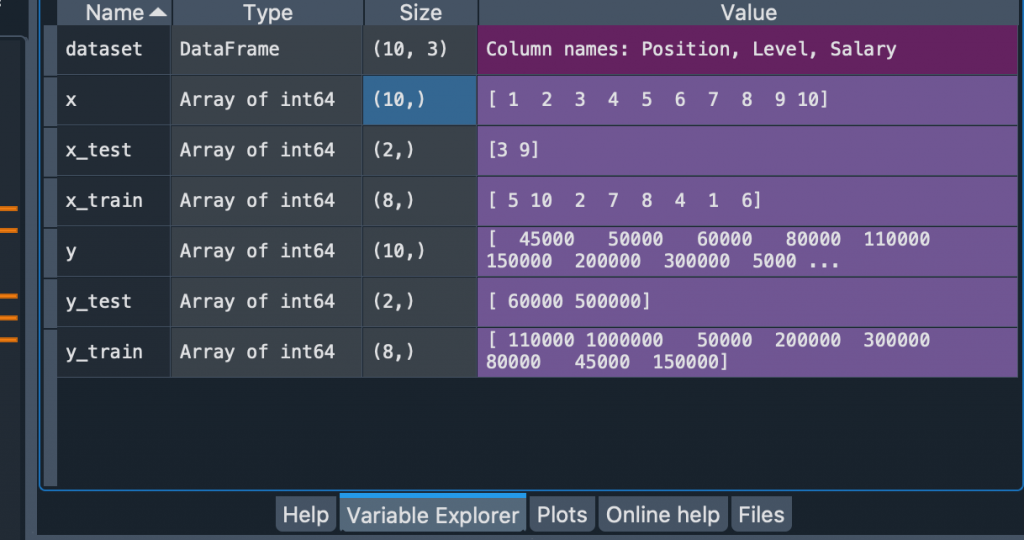
因此我們要將** x 改為 dataset.iloc[:,1:2].values**
1:2 代表取第一行~第二的前一行, 因此會得到一個 10 * 1 的矩陣
x = dataset.iloc[:, 1].values
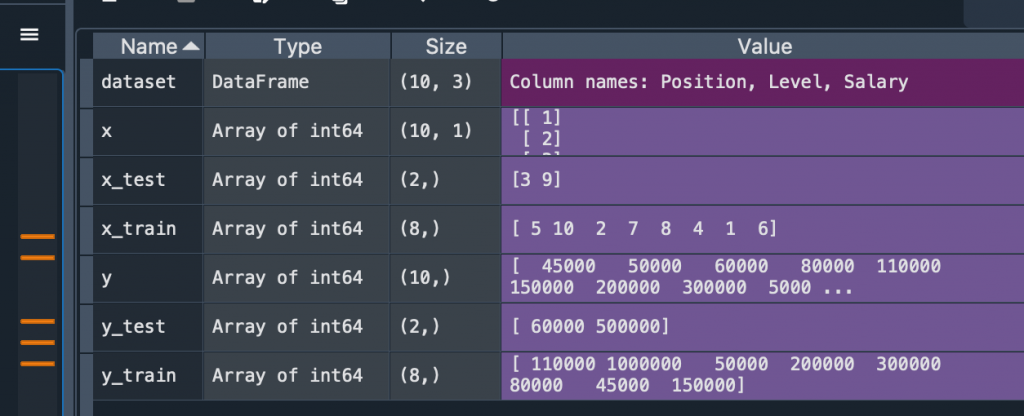
改完後x size 成為(10,1), 也就是一個 10 * 1 的矩陣
接著需要分割資料成測試集和數據集嗎?
答案是“不用” 因為
(1)數據只有十組(很少)若再將資料切成兩份可能會讓數據集不夠拿來擬合模型
(2)面試者給的薪資就已經是測試集數據了
因為開頭提到HR是想知道用這些資料取出來的level 6.5 的薪資
有沒有等於面試者開出的薪資
因此為了要使結果更精準, 能用越多的數據集是最好的
另外特徵縮放也不需要, 因為library 本身會處理
(跟多元線性回歸用一樣的library所以不需要)
前處理結束之後下一篇繼續學習多項式回歸的實作


 iThome鐵人賽
iThome鐵人賽