昨天的文章中提到 Uber 計算預估抵達時間(Estimated Time of Arrival,ETA)時,不僅要考慮路線本身,也會被時間、天氣和交通狀況影響。
而計算 ETA 之所以重要,不僅是因為可以提供用戶較好的使用體驗,也能夠幫助 Uber 計算費用、配對司機和乘客,以及計畫配送路線。
今天,讓我們來聊聊傳統估算 ETA 的方式,以及 Uber 是如何改進,符合他們需求。
傳統的 ETA 估計方式是使用 routing engine(又名 route planner),作法是將一段路線分割成很多段小路線,並使用最短路徑演算法(shortest-path algorithms)尋找最好的路線。每一段小路線的權重代表路途時間,整段的 ETA 為每一個小路線的權重加總而成。
現代一點的 routing engine 甚至會考慮實際的交通狀況、交通事故和天氣。
不過,在需要媒合外送員、司機和乘客,以及候餐的情境下,還是會遇到幾個問題:
針對以上問題,Uber 提出一個混合(hybrid)模型,稱為 ETA 後處理系統(ETA post-processing system)。先利用 routing engine 計算 ETA,再利用 DeeprETANet 處理 ETA 和真實抵達時間的差異(residual)。
ETA 後處理系統(ETA post-processing system)= routing engine + DeeprETANet。
DeeprETANet 的 deep 是指 deep neural network、r 是 residual,ETA 是 Estimated Time of Arrival。
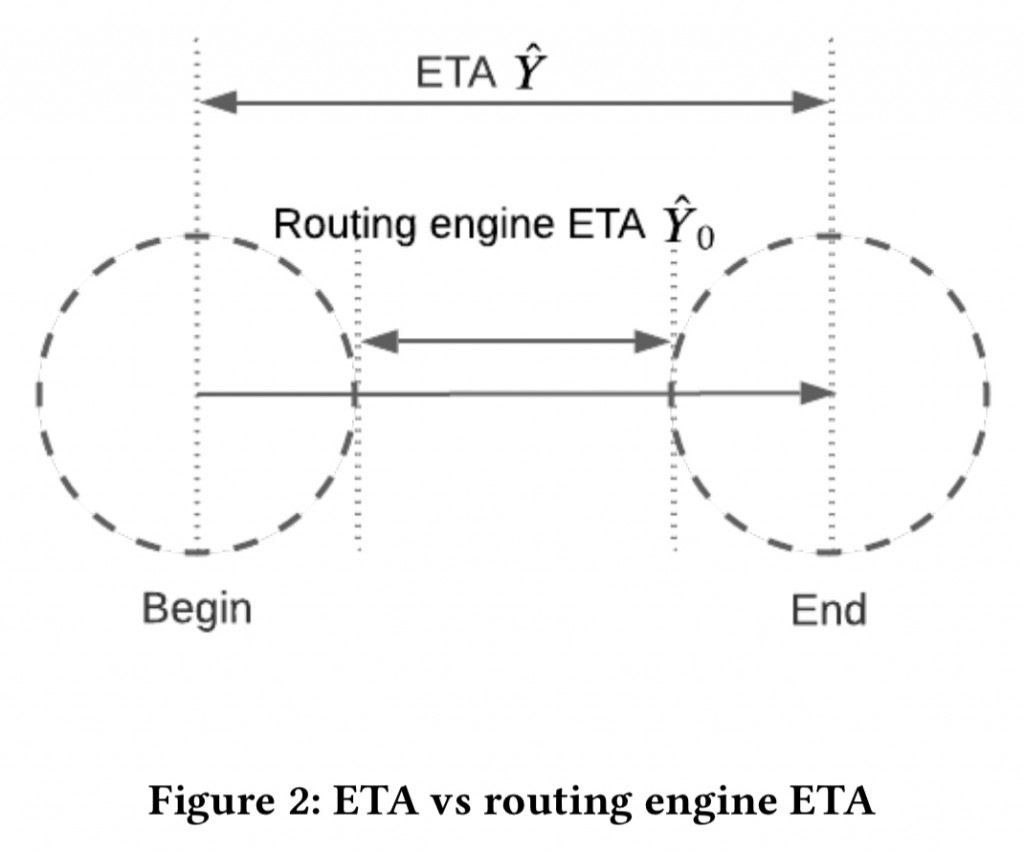
首先,我們來說明為什麼 routing engine 計算的 ETA(稱為 RE-ETA)和真實的 ETA(稱為 ATA,actual arrival time)會有差異。
ATA 根據任務類型,有兩種定義:
(1) Pick-up:從駕駛接受這筆訂單,到開始外送或接到客人為止的時間。
(2) Drop-off:從旅程的開始到結束的時間。
而從 A 點到 B 點的路程時間,會受到實際的交通狀況、駕駛行走的路線,以及任務類型(外送或接送乘客)影響。另外,司機也有可能要找停車位、或需要等待店家備餐等。因此起點和終點會有一些雜訊,需要 ETA 後處理系統(ETA post-processing system)處理 Y hat 和 RE-ETA(Y0 hat) 中間的差異。
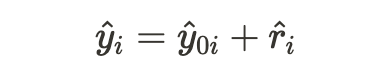
換而言之,routing engine 會估算出 RE-ETA(Y0 hat),再使用 DeeprETANet 處理殘差 r hat(residual)。
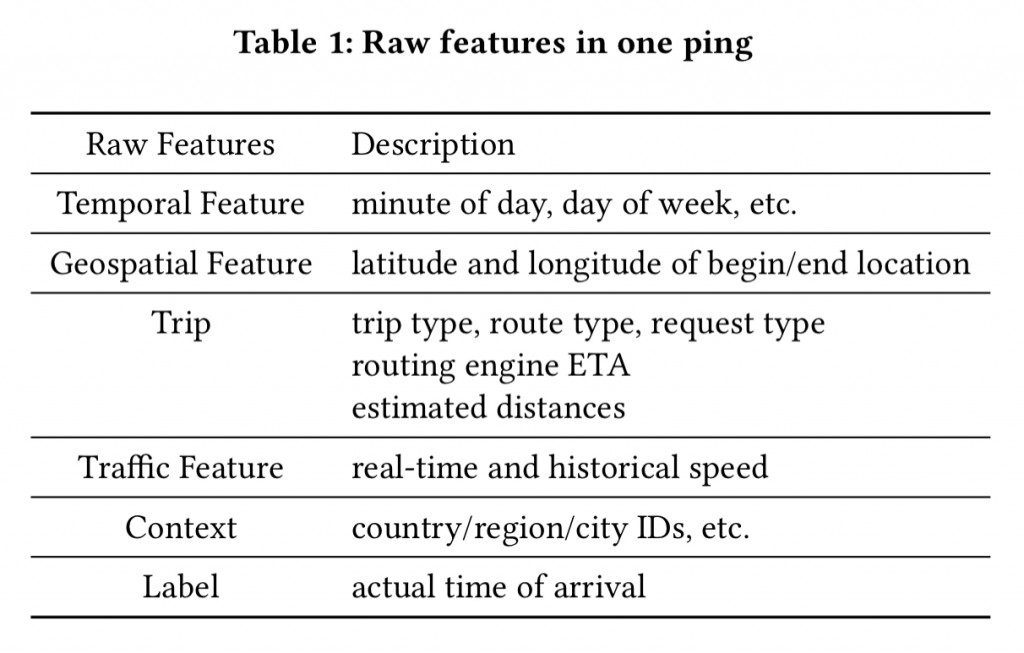
為了更準確地估計 ETA,除了地理資料以外,也會考慮時間、即時交通狀況和叫車情境等等。使用到的所有特徵如 table 1 所示。
DeeprETANet 分為兩部分:Embedding module 和 Two-layer module。
Embedding module:處理類別、連續和空間特徵。Two-layer module:分成 interaction layer 和 calibration layer(fully connected layer)。Embedding module 負責處理 routing engine 的輸出,以及和這筆 Uber 訂單有關的特徵。特徵分為三種形式:類別特徵、連續特徵和校準(calibration)特徵。其中,校準(calibration)特徵包含這段路程的資訊,例如這是一個 drop-off 或是共乘的 pick-up 行程。
特徵的前處理
geohashing
以經緯度(lat, lng)表示空間資訊,目標是轉成長度為 5u 的字串。做法是將經緯度(lat, lng)轉成 [0, 1] 的浮點數後,再轉成整數,最後使用 Base32 編碼成字串。
Feature Hashing
將起點和終點的經緯度分別做 hashing,並使用 multiple feature hashing 避免 collisions 的問題。
將所有特徵經過上述的 embedding module 處理完畢之後,會經過兩層類神經網絡:interaction layer 和 calibration layer。
Uber 利用 interaction layer 學習特徵之間的交互行為,interaction layer 的原理即為上一篇提到的 self-attention 技術。當 self-attention layer 在處理每個特徵時,如同上篇提到,會同時考慮其他特徵,並輸出權重為 attention scores 的總和。因此,憑藉著 self-attention 的技術,能夠在預測 ETA 時同時考慮到所有時間、空間的資訊。
Calibration layer 的目的是處理不同的行程(pick-up 或 drop-off),方法是使用一個全連接層(fully connected layey)專門行程的特徵,以便調整輸出的 residual。
好的,終於說完整個 DeeprETANet 的架構,讓我們來看看結果吧!
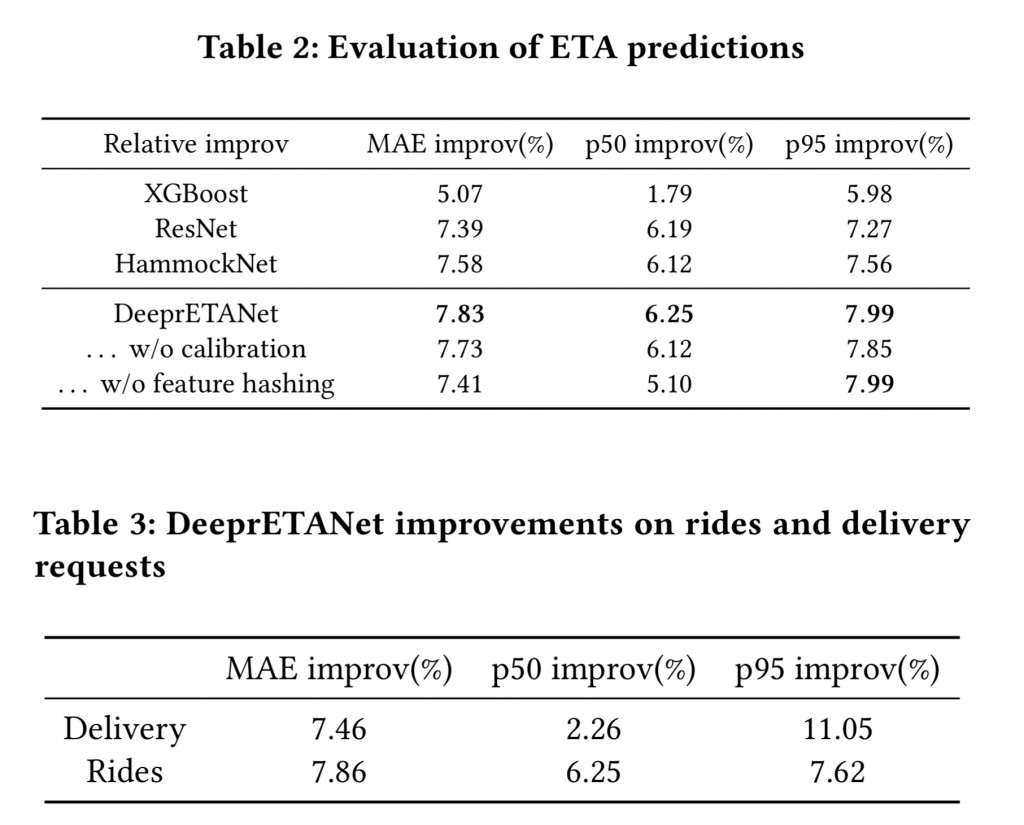
模型訓練的 metrics 是跟 routing engine ETA(RE-ETA)犯下的錯誤比較,簡而言之,可以想像成在使用 DeeprETANet 後,MAE(mean absolute error)和 p50、和 p90 的錯誤率進步多少。
Uber 使用幾個不同的模型做比較,如 Table 2 和 Table 3 所示,DeeprETANet 都有顯而易見的增長,且無論是哪個任務,都是有進步的。
以上就是 Uber 提出的 DeeprETANet 的介紹!那我們明天再見吧!
謝謝讀到最後的你,如果喜歡這系列,別忘了按下喜歡和訂閱,才不會錯過最新更新。
也歡迎到我的 medium 逛逛!
Reference:

