昨天看完 Uber 如何預測抵達時間,今天來聊聊另外一個主題,看看 Uber 的詐騙偵測(fraud detection)吧!
無論是什麼產業,防止詐騙行為都是非常重要的事情。而詐騙偵測系統並不能單靠有如黑盒子般的 AI 演算法解決,一定需要仰賴人為介入,以判斷何謂詐騙行為。
Uber 主要關心的是兩種關於付款的詐騙類型:DNS 和 Chargeback。
在分析付款的詐騙類型之前,要先認識關於交易金流的資料狀態。付款資料時常會處於一種「不成熟」的狀態,例如一開始沒有搜集完全的付款資訊,可能過幾天就完成了。然而,一開始沒有爭議的款項,也可能在幾天甚至幾週後,有消費者提出申訴。當分析師在看到一筆「不成熟」的資料時,要如何判斷這是正常現象抑或是詐騙行為呢?並且,要如何借助於 ML 模型的力量呢?
由於 Uber 需要處理上百萬筆交易,不可能所有資料都經過人為分析、處理、抓取規則,因此他們引入 RADAR 系統,監控詐欺行為,並產生需要停止交易的規則。值得注意的是,Uber 強調儘管借助於 ML 技術,仍然需要人為介入檢查,只是使用模型後速度快很多,也比較容易。
下圖是整個 RADAR 架構,可以看到最後會被送到 Jira,經由人為判斷,進行後續行為。
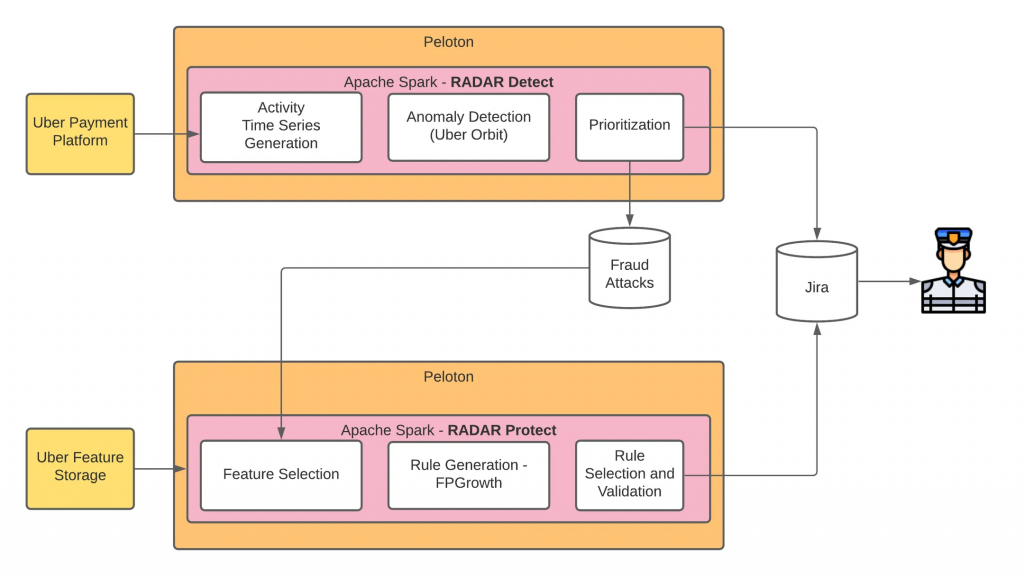
Uber 使用時間序列模型以分析資料,從兩個時間維度觀看資料:
時間序列模型使用的是 Uber 的 Orbit,有興趣的人可以參考這個 repo。
偵測詐騙攻擊的方法是使用一個 time series decomposition 模型,解構在 OT 維度和 PSMT 維度片段的資料。因為一個詐騙攻擊在時間序列資料看起來會特別異常,而 Uber 搜集數十種短期和長期的異常訊號,得以幫助他們判斷此事件是否為攻擊行為。
Uber 會將所有連續數值資料都轉成類別資料。至於需要選擇哪些訊號、patterns 會和詐騙行為有關,使用的是 MRMR feature selection 技術。MRMR feature selection 是選擇彼此距離較遠,但和分類變項都有高度相關的特徵。
至於 RADAR 模型如何抓取規則,以偵測詐騙行為,如下圖所示。Uber 會搜集所有詐騙資料,並將所有特徵轉成 one-hot encoding。找尋所有詐騙行為共同的特徵,再將其轉成規則,以供後續使用。
(圖中資料有誤,id34 應為 3456)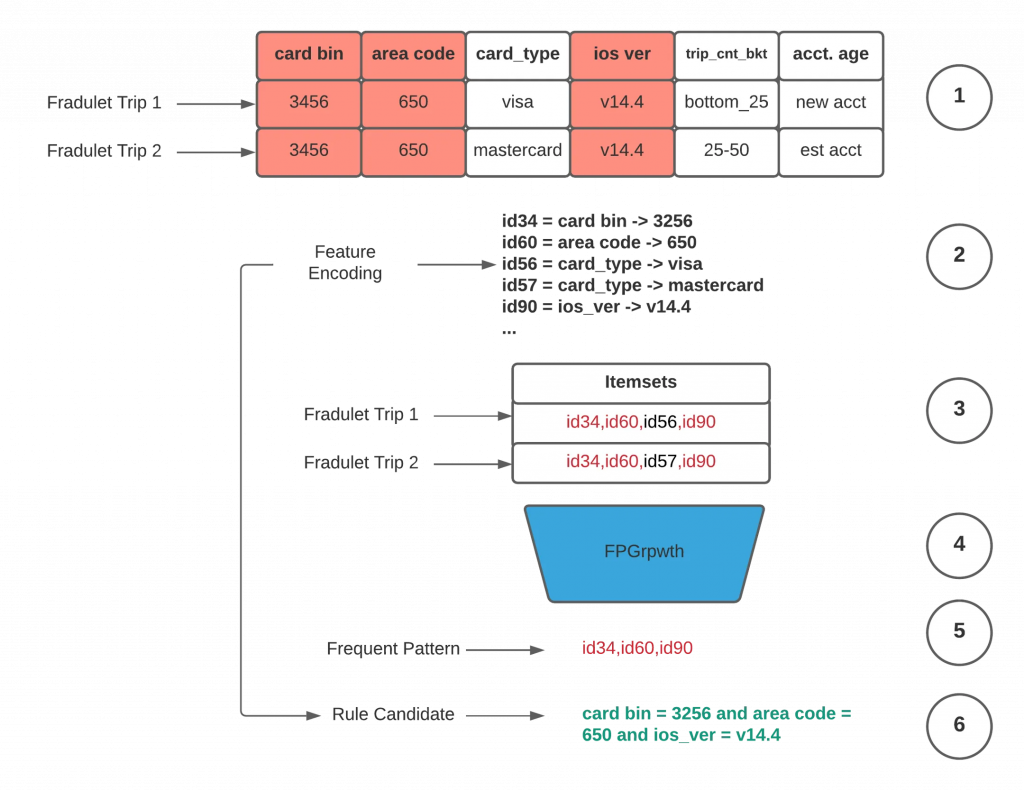
不過,並非所有規則都是有幫助的,因為許多規則也是存在於一般正常交易,仍需要再被驗證。
驗證的方法是將選出來的這些候選規則再反向運用至資料上,確認抓出來的資料都是詐騙行為,並會經由分析師再次確認。
以上是關於 Uber RADAR 的小小介紹。詐騙行為對於各行各樣都是很大的風險與困擾,明天再回來一起看看其他電商如何處理詐騙攻擊吧!
謝謝讀到最後的你,如果喜歡這系列,別忘了按下喜歡和訂閱,才不會錯過最新更新。
也歡迎到我的 medium 逛逛!
Reference:

