在昨天的文章中,我們聊到 Uber 如何使用 RADAR 系統偵測詐騙行為。今天,讓我們再擴大應用場域,看看跟現今生活密不可分的購物網站是如何處理詐騙問題吧!
購物網站的詐騙有許多類型,例如假帳號、假的付款方式、以及假的評論。而機器學習對於詐騙偵測而言是非常重要的技術,而詐騙案例層出不窮,機器學習技術也五花八門,哪些技術適合運用在哪些場域?公司內部又是如何分工處理這些棘手的案例呢?
下圖是一間公司的反詐騙部門在處理案例的流程和技術運用,讓我們來一一分析幾個重要元件。
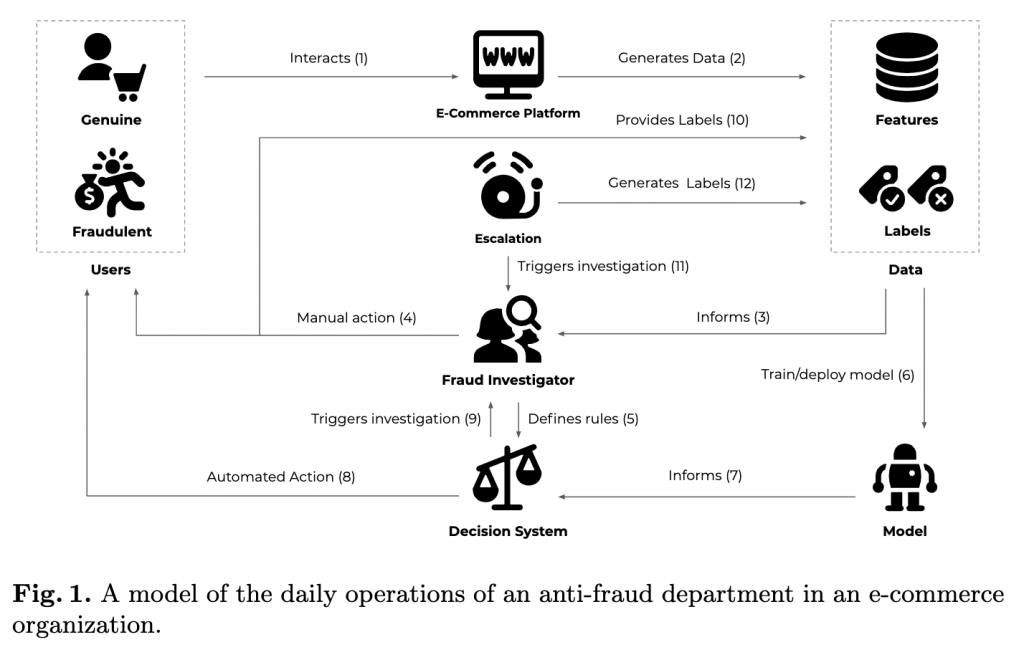
關於上圖中的詐騙流程,可以分成幾個不同部分主題,並各自會使用相對應的技術,如下表的整理。
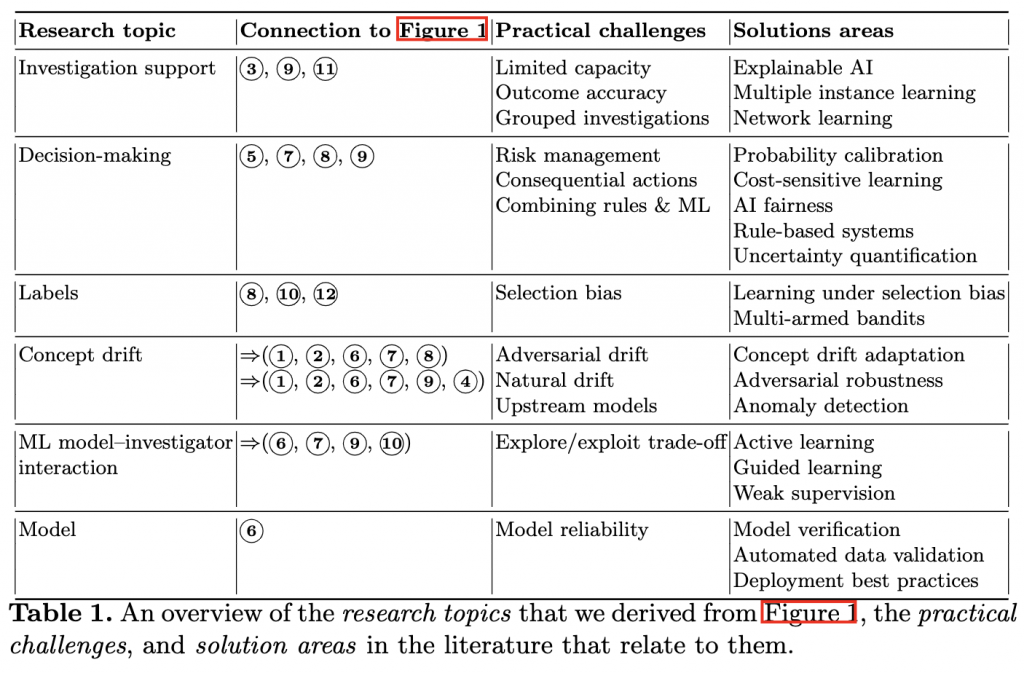
溫馨提醒:本篇文章只選擇其中幾項主題介紹,並且由於提及的技術繁多,每個技術會著重在和詐騙行為有關的內容。有一點像是技術引薦、拋磚引玉,有興趣的人可以再去深入瞭解。
為了減少詐騙行為觀察家(fraud investigators)的工作量、提升效率和準確性,引入機器學習技術以幫助判別詐騙行為。機器學習能夠使用的情境,例如一些相似的詐騙行為,其 ip 位置相同,能夠被放入一個群體一起觀察,減少需要觀察的案例個數。
Explainable AI 和視覺化能夠幫助詐騙行為觀察家(fraud investigators)做決策。另外,在許多詐騙偵測系統中,特徵之間的交互作用是一個很重要的觀察特徵。
MIL 讓 ML 模型能夠一次分類一整群,而不是只分類一個案例。而需要用到這項技術的原因是因為很多詐騙案例會是同樣的攻擊者不斷地攻擊,使用群體層次的觀察會比只觀察單一現象更精準。
Network learning 的概念有點接近於想要一次觀察一整群資料。如果能夠一次觀察一整群資料,就能夠觀察到一些只有詐騙行為會出現的資料特徵,例如 ip 位置或是使用的 email。
Decision system 在懷疑一個事件為詐欺行為時,可以自動處理,也可以送通知請人來觀察。採取行動時要非常謹慎小心,錯誤的判斷可能會造成很嚴重的後果,false positive 可能會封鎖一個正常的使用者,而 false negative 可能會導致詐欺行為的產生。Decision system 有兩種幫助其做決策的資料來源,分別為 ML 和規則,這兩者為互補的,一起考慮有利於詐騙行為的判斷。
Probability calibration 旨在將一個分類器的輸出轉換成預測的模型分數,用以估計其為正向類別的可能性。這種估計之所以重要,是因為能夠衡量 decision making 的危機,並是一些其他工具的先備知識。能夠計算 probability calibration 的工具包含 Platt scaling、Beta calibration 和 isotonic regression。
為了盡量降低分類錯誤造成的損失,cost-sensitive learning 不僅是想要降低犯錯的數量,也將在商業上的損失納入考量。
估計損失的方法是利用混肴矩陣(confusion matrix)中的四格內容:false positive、false negative、true positive 和 true negative。以詐騙的情境為例,false positive 發生在阻擋一筆交易後,造成的訂單損失;而 false negative 發生於當產生詐騙行為所造成的損失。
Uncertainty quantification 發生於當 ML 模型預測的不確定性太高,而模型能夠選擇拒絕交易、或是延遲一筆交易時。此時可以使用 classification with a reject option。
Classification with a reject option 是指在詐騙偵測時,會有一個系統稱為「信任系統(trusting system)」,在此系統中的客戶都是白名單,是一群重要客戶且明確知道他們不是詐騙用戶。然而,如果小心將詐騙用戶列入這個名單中,會造成很嚴重的後果。因此,在模型下判斷時,如果認為某次行為有太多不確定的因素時,需要能夠拒絕交易。
詐騙行為觀察家(fraud investigators)為了幫助 ML 模型,而制定的規則。當詐騙行為觀察家(fraud investigators)發現一些新的、沒有被 ML 模型偵測的詐騙攻擊時,會先制定一些規則。此有助於在 ML 模型學到新的攻擊行為之前,先有一層過濾的機制。
詐騙行為的標記有兩個來源:詐騙行為觀察家(fraud investigators)和銀行的通報系統。然而,在標記時可能會有選側偏誤(selection bias)。產生的原因有很多,例如在上一篇 Uber 的介紹中提到,付款資料可能會有延遲,使資料處於不成熟階段。或是因為在等待手動標記的期間太久,而造成類似的詐騙行為再次發生。
為了避免此現象,可以借助於以下三種機器學習的技術以標注辨別。
同時考慮標記和未標記的資料。
在 target domain 中增加一點標記的資料。
讓一個交易通過後,可以觀察到兩種不同面向的結果:其一是贊同此交易的結果,另一方面是如果這個交易被拒絕的話,會帶來的損失。而每筆交易是否會通過,並非隨機決定,而是希望能夠使用之前在 Day 11 的文章中,有提過的 Multi-Armed Bandit。
分析時會希望在最佳化的情境下 explore,也就是讓一個交易通過。而最佳的時機為有兩個:當一個交易的預期損失最少,或是當模型有很高的不確定性時。
偵測詐騙行為是一種跟犯人對抗的事情,因為當 decision system 成功阻擋一筆詐騙交易,犯人很可能會再想辦法繞過系統偵測,因此系統又需要學習新的方法以偵測詐騙。除了詐騙用戶,一般的消費者也有可能會因為季節、購物網站的改變、或不可預期的事件(如 Covid 19)發生,而改變行為。
常使用到的技術有 Concept drift adaptation、anomaly detection。
要分辨一個用戶改變行為是因為在從事詐欺行為(不斷試著要繞過系統),抑或是因為購物網站的介面改變,其實很好方便。因為前者的行為會是緩慢而逐漸地改變,而後者是直接突然改變。因此這一類的行為可以利用 concept drift adaptation 分析。
Anomaly detection 是一個可以從正常資料中看到異常資料的方法,因此可以利用這個方法偵測詐欺行為。不過並非所有離群值(outliers)都是詐騙行為,有可能只是因為如上述所說,網站設計改版、或不可預期的事件發生,需要詐騙行為觀察家(fraud investigators)進一步確認。
此處有兩個目標:辨識詐騙行為,和產生可以應用在模型中的標籤。
AL 模型會決定哪些資料點需要先被標示,讓詐騙行為觀察家(fraud investigators)能夠先標記這些行為,模型再跟著修正、學習新的判斷方式。如此一來,模型能夠更快速地學習如何適應 concept drift,也能夠減少詐騙行為觀察家(fraud investigators)決定哪些資料需要被標記的方法。
好了,終於把所有的技術介紹完畢。不過由於篇幅關係,每個技術都只有簡單介紹應用場域,如果想要知道更細節內容,可以參考原始 paper 的內容,或是再用這些關鍵字額外延伸。

謝謝讀到最後的你,如果喜歡這系列,別忘了按下喜歡和訂閱,才不會錯過最新更新。
也歡迎到我的 medium 逛逛!
Reference:
N. Tax et al., “Machine Learning for Fraud Detection in E-Commerce: A Research Agenda.” arXiv, Jul. 05, 2021. Accessed: Sep. 28, 2022. [Online]. Available: http://arxiv.org/abs/2107.01979


 iThome鐵人賽
iThome鐵人賽