Skylar 和 Krsitina 最近想要重新裝潢他們家,因此閒來無事時就會到 Pinterest 上看別人分享的裝潢照片作為參考。另外,Krsitina 也常常在上面看許多關於美甲、食物擺盤等內容。神奇的是,Pinterest 似乎永遠都有源源不絕的內容,並且會隨時依據觀看歷史紀錄調整。
Pinterest 的首頁看起來跟 Instagram 的 Explore 頁面有一點相似,但似乎又不盡相同。我們之前介紹過 Instagram 如何設計 Explore 的演算法,現在讓我們轉移目光到 Pinterest,看看他們又是如何設計的吧!
Pinterest 主要用到的技術為 GNN(Graph Neural Network),按照慣例,為了幫助大家之後的理解,會先花一些篇幅介紹 GNN 相關的內容,之後再深入探討 Pinterest 的演算法。
首先,先來了解什麼是 graph,簡單來說就是一個網絡圖形,每個概念是一個節點(node),節點之間的連接稱為 edge。例如 Alicoco 的節點(node)是商品或一個商業概念,而 Pinterest 的一個節點(node)則是一則內容。
那要怎麼得到 graph 的特徵(feature)呢?既然用 graph 的形式,就應該考慮節點本身、節點和他的鄰居(有被 edge 連接著的節點們),和整個圖形關係,可以分成下列三種層次的特徵:
但是,以上三種層次的特徵都是在餵入模型之前,就需要先行計算的。有點類似於在使用 ML 模型前,需要先做特徵工程(feature engineering),將資料轉成平均數、標準差等等,再輸入至模型中。
那有沒有辦法讓直接將整個 graph 輸入模型,讓模型自己算出 embedding 呢?當然可以!這就是 representation learning 的概念,讓我們繼續看下去吧!
想要將 graph 轉成 embedding 的方法,其實就是找兩個節點 u 和 v 的相似程度。如果他們在原本的 graph 中很相似,則希望投影到 embedding space 之後,他們兩個也可以很相似。
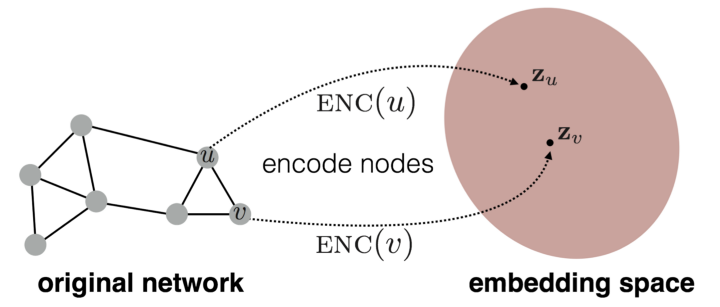
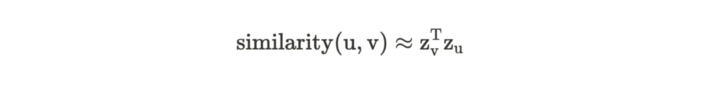
左式是在原本的空間中,而右式是投射的 embedding space,並且需要定義相似函數。
計算 node embeddings 的四個步驟:
好的,看來最重要的事情就是定義相似函數(similarity function)。
兩個節點在什麼時候會很相似?是彼此的鄰居時嗎?或是有共同的鄰居呢?還是有相似的結構呢?
在這裡,我們會介紹一個叫 random walk 的方法,這也是 Pinterest 技術的起點。
會用到的幾個名詞:
什麼是 random walk 呢?其實就是字面上的意思,在圖中隨便亂走。對,就是這麼簡單。
如下圖,我們選定一個起點之後,從他的鄰居中隨便選一個走過去,再從鄰居的鄰居中隨機選一個走過去,並儲存一路上走過的節點。
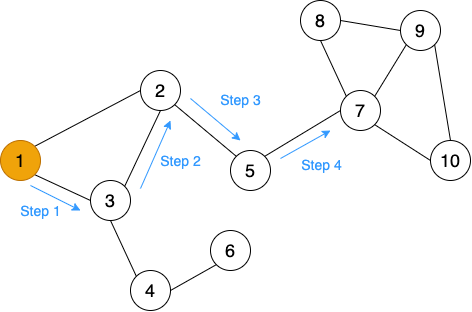
相似函數(similarity function)定義如下:

那要怎麼將 random walks 這個概念運用在 embedding 上呢?
目標:找到投射在 d 維度空間中的 embedding,學習投射函數 f(u) = zᵤ
步驟:
N_R(u)
- 包含 random walk 經過的所有節點。
- 是 multiset,代表裡面可能會有很多重複的節點,因為可能會重複走到相同的節點。
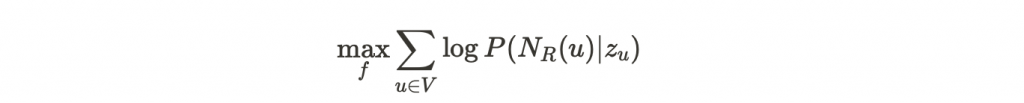
上面的式子可以化簡如下:
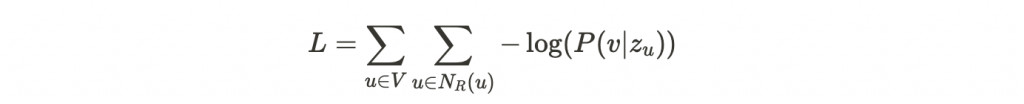
並以 softmax 計算機率,得到最終表示式:
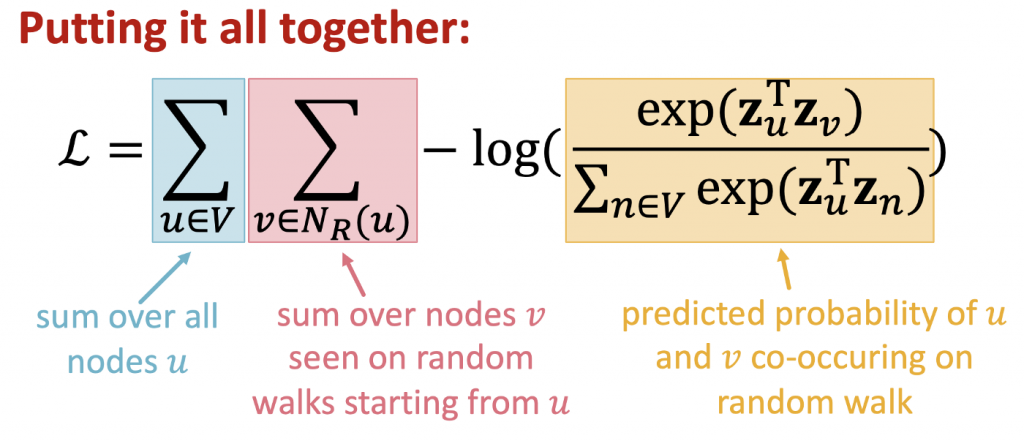
最佳化 random walk embeddings = Finding embeddings zᵤ that minimize L
好耶,我們得到了 loss function,只要最小化這個 loss 之後就可以得到 embedding 了嗎?
不不不,事情還沒有結束,看看我們精美的 loss function,竟然有三個連加符號。先不管 N_R(u) 的總和,光是兩個在所有 nodes v 相加就讓時間複雜度變成 O(|V|²),這樣計算上也太耗時了吧!
為了避免計算繁雜,需要引入 negative sampling 的概念。在計算 log 時,不計算所有節點的總和,而只計算 k 個 random negative samples (nᵢ)。
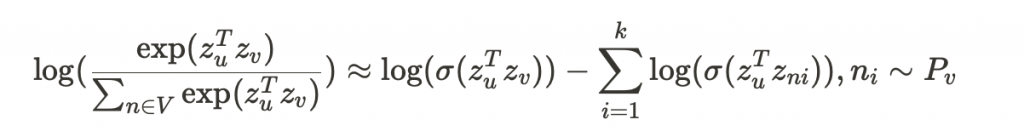
最後,使用 gradient descent 或 stochastic gradient descent,以最小化這個目標函數的損失。可以隨機初始化 zᵢ,經過迭代計算直到收斂。
好唷,以上是 graph 和如何利用 random walk 生成 embedding 的方法。Pinterest 又是如何利用這個方法的呢?明天回來,我們再一起學習吧!
謝謝讀到最後的你,如果喜歡這系列,別忘了按下喜歡和訂閱,才不會錯過最新更新。
也歡迎到我的 medium 逛逛!
如果對 GNN 有興趣了解更多人,可以在 這邊 看我之前寫過的介紹文章。
Reference:


 iThome鐵人賽
iThome鐵人賽