延續上一篇的 pandas pivot_table 函數以及數據分析與思考基本問題。
如果我們想看到按產品細分的銷售額,列變量允許我們定義一個或多個列。Pivot_table 最令人困惑的地方是列和值的使用。列是可選的--它們提供了一種額外的方式來分割實際數值,利用聚合函數被應用於你列出的值,一開始我們一樣先匯入資料集。
df = pd.read_excel("data/funnel.xlsx")
df.head()

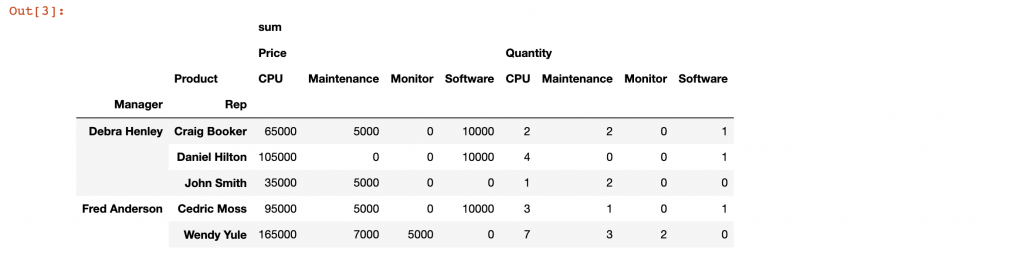
通常來說把我個人會把數量也加進去,通常這樣的方法會對於我們做計算很有幫助,在數值列表中添加數量。我們索引設定為 Manager 和 Rep 來進行運算,在設定 Price 與 Quantity 的同時,設定 columns 以 Product 作為分類,聚合函數以 sum 來做總和運算,最後設定自動填充零值。
pd.pivot_table(df,index=["Manager","Rep"],
values=["Price","Quantity"],
columns=["Product"],
aggfunc=[np.sum],
fill_value=0)
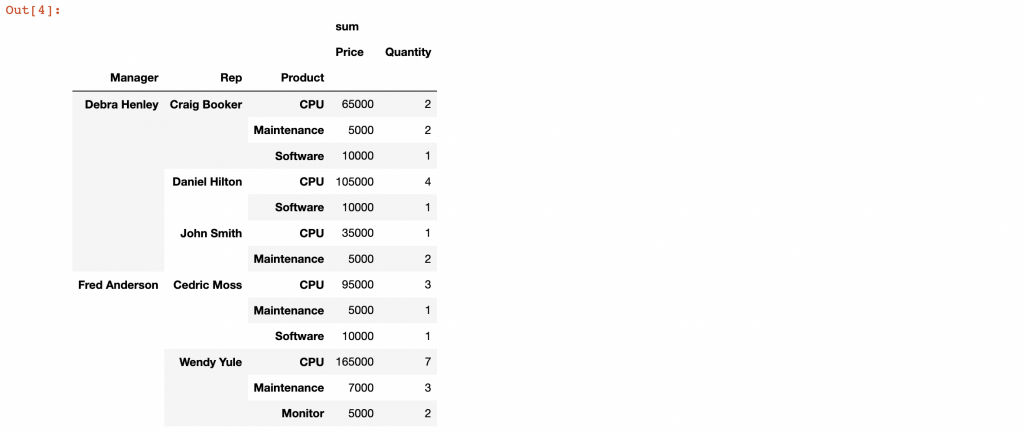
有趣的是,我們也可以將 Product 從 columns 移到索引中,這樣的方法以獲得不同的視覺表現。
pd.pivot_table(df,index=["Manager","Rep","Product"],
values=["Price","Quantity"],
aggfunc=[np.sum],fill_value=0)
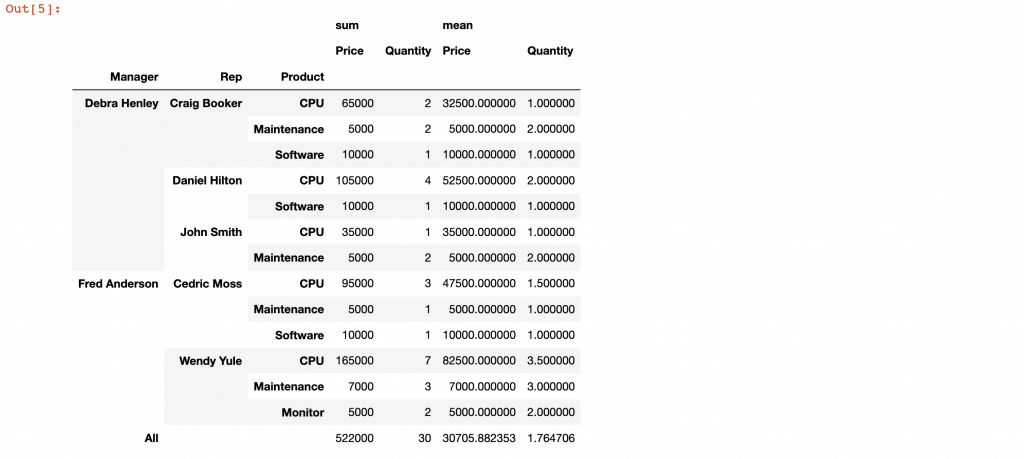
但是當我們將 columns 移到所以後,將沒辦法顯示出 aggfunc 聚合函數所進行的運算值,如果我想看一些總數怎麼辦? 有個方法是 margins=True 能夠協助我們達成需求,我們設定 margins=True,並且讓聚合函數中加入 np.mean 來凸顯我們的製圖方式。
pd.pivot_table(df,index=["Manager","Rep","Product"],
values=["Price","Quantity"],
aggfunc=[np.sum,np.mean],fill_value=0,
margins=True)
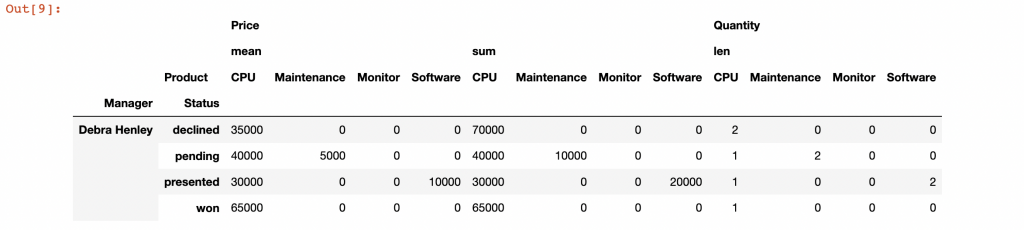
一旦我們利用樞紐分析方式生成了數據,那這項數據就會在一個 DataFrame 中,所以我們可以使用你的標準 DataFrame 函數對它進行過濾。
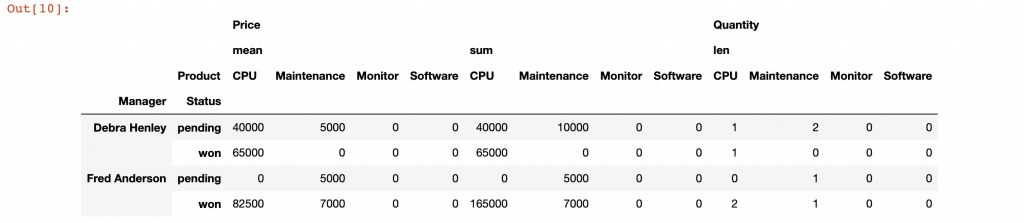
table = pd.pivot_table(df,index=["Manager","Status"],
columns=["Product"],
values=["Quantity","Price"],
aggfunc={"Quantity":len,"Price":[np.sum,np.mean]},
fill_value=0)
table.query('Manager == ["Debra Henley"]')
這是 pivot_table 中強大的功能,所以不要忘記,一旦你把你的數據變成你需要的 pivot_table 格式,你就擁有了整個數據的主宰權,能讓順利的把他應用起來,就能在大量複雜數據處理上得心應手,但是記住在簡單資料處理上,試算表的樞紐分析也許還是更方便些,端看使用的情境怎麼調整。
table.query('Status == ["pending","won"]')
今年沒組團,每一筆一字矢志不渝的獻身精神都是為歷史書寫下新頁,有空的話可以走走逛逛我們去年寫的文章。
Jerry 據說是個僅佔人口的 4% 人口的 INFP 理想主義者,總是從最壞的生活中尋找最好的一面,想方設法讓世界更好,內心的火焰和熱情可以光芒四射,畢業後把人生暫停了半年,緩下腳步的同時找了份跨領域工作。偶而散步、愛跟小動物玩耍。曾立過很多志,最近是希望當一個有夢想的人。
謝謝你的時間「訂閱,追蹤和留言」都是陪伴我走過 30 天鐵人賽的精神糧食。

