筆者決定用以下三點結論規劃接下來的實作:
overfitting 等問題。平均數作為預測基準戴久永教授現代統計學的發展
一文提到:「對於集中趨勢的測度。最早的集中趨勢的測度實際上可追溯至古希臘,是算術平均數......對大多數的目的而言算術平均數是最常用的集中趨勢測度,這當然有它學理上的意義。」
而在林嘉澍教授迴歸分析的三個基本概念一文中,認為可以用平均值來作為預測以及將來預測的比較基準:「我們想像一下最簡單的迴歸公式,其實就是一直線! 比方我要預測期末可成績,就用Y=85這個全班平均值來預測即可。當然,我們想要做更精密的預測,所以引入了X變項(出席時間),看看加入個別出席時間這個變項以後,得到的預測值會不會比Y=85來得更好。」
這句話給了我當頭棒喝,仔細想想其實我們問題的本質並不複雜!雖然用平均數作為預測結果或許會導致一些誤差(例如他們最近兩個月可能因為人員流動,導致將來三個月內每個人都會晚 10 分鐘下班),但這些優化都是後事,讓我們先取得一個參考基準作為 POC (Proof of concept)。
根據「迴歸分析的三個基本概念」,我們可以有兩種模式來預測:
模式A,亦即針對每一個同樣的星期幾,都使用一樣算術平均數來作出預測。將來若要設計其他的預測模型,我們可以用平均數作為比較的基準。例如,我們最初的需求是十分鐘前發出通知提醒要關門了,所以假設今天預測值提前了五分鐘,那麼這五分鐘便可以特別記錄,思考是什麼因素造成誤差,如季節、溫度等。
所以我們也需要一併記錄後續的誤差以及其他可能的影響因素。在沒有更好的點子之前,我們後續的記錄除了維持 Day 07 提到的「小時分鐘+日期+星期幾+備註」以外,至少還要加入預測時間以及實際關門時間的欄位。
讓我們再看一次昨天生成的散佈圖: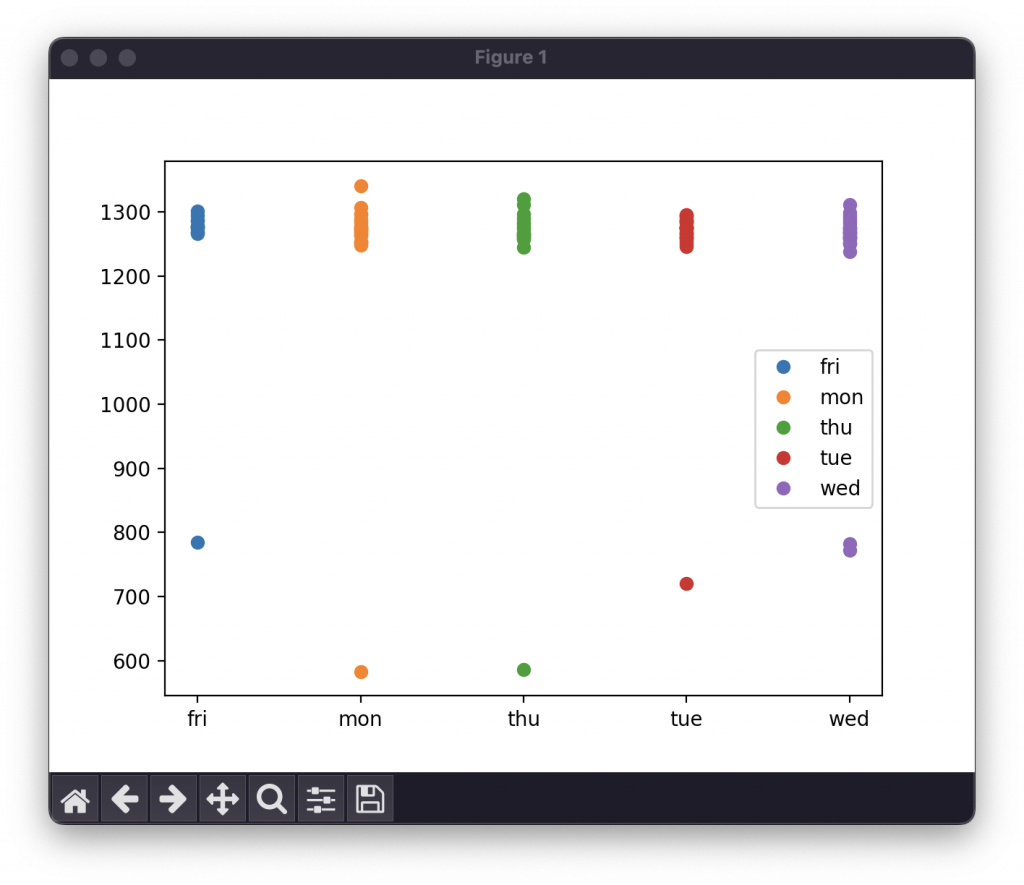
週五的預測值當作週六以及週日的預測值。待後續有記錄後,再來觀察校準。平均數作為每一天的早上時間預測。透過後續記錄,再來校準誤差。明天讓我們開始實作。
今天收工!

