你可能有聽過這麼一句話:
「我以為我在做 AI,但原來我在做資料清理」
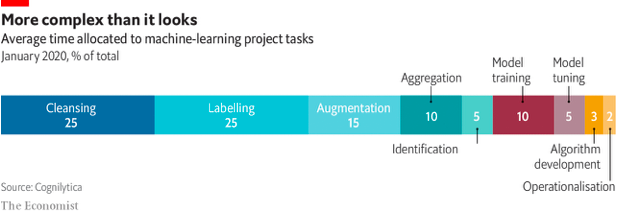
ーー 機器學習任務約 80%的時間花在處理資料上,出處:Cognilytica
前面我們在做模型訓練的時候,資料集都已經是整理好的數位資料,連圖片大小都幫你統一好尺寸,資料也沒有缺失或錯誤處於非常乾淨的狀態,但現實生活中形形色色的各種資料就沒有這麼單純。
身為製造業的軟體工程師,需要處理裝置透過各種感測器捕捉到的訊息資料,例如溫度,大氣壓力等等。早期因為工作的關係需要到各國客戶的工廠出差,到新工廠最常遇到的問題就是為什麼有些資料是錯的?從資料來源的硬體配線接錯,到中間可編程邏輯控制器(PLC)的信號位址設錯,還有神奇的網路 IP 設成別台電腦收錯資料,以及客戶上游裝置資料給錯,只有你想不到,沒有不發生的各種資料錯誤。
隨著系列文一路走來,我們已經了解資料的重要性,也就是沒有資料就沒辦法做機器學習這件事情。所以要開始運用 AI,第一步就是要先收集資料。而我們一直強調讓電腦能夠理解的資料,指的是能存放在電腦的數位資料。
結構性資料
可以呈現表格形式的資料。比方說我們應該都有經驗手寫填過下面這份表單:
| 姓名 | 電話 | 住址 |
|---|
王大X | 09xx-xxx-xxx | xx市xx區xx街xx號
將紙本表格轉成數位資料,可以打字/語音輸入或是用掃描/拍照後做文字辨識(OCR)。
非結構性資料
將傳統的紙本資料或圖片轉成數位資料,叫做數位化(Digitization)。
用深度學習也能有效率地作數位化。現在機車行用照相機拍車牌自動輸入到電腦就是其中一種方法。其他類似的手法還有把信用卡拍照下來直接轉成文字資料。而 Line 的拍照自動抓取文字區域做文字辨識也是圖像辨識的一環。電腦上截圖直接轉換成文字也有一個好用的工具:TextShot

ーー可以從圖片辨識出多國語言(E.g. jpn+eng 同時辨識日英文),出處:TextShot
另外提到數位化就得順便提一個關鍵字:物聯網(IoT,Internet of Things),也就是物體之間的網路,物體透過感測器收集資料,透過無線網路共享資料並傳送給相關裝置做資料處理。
例如:智慧家庭(Smart Home),用語音聲控做各種家電的控制。
實際上依據產業類別要合作夥伴提供資料是有困難性的,至少在尖端科技的製造業,製程相關資料會保密到家。以前出差到韓國某大廠的無塵室工廠,進出門口就像海關一樣嚴格,不要說沒有網路,電腦所有的插槽都被特殊貼紙封死,手機也不能帶進去。記得剛進公司第二個禮拜被派到韓國,就因為電腦包有一片忘記拿出來的 windows 安裝光碟,在凌晨1點準備回飯店時被大門警衛攔下通報,一直弄到凌晨3點才放人,之後還上了全集團的社內報作為負面教材,當時作為社會新鮮人真的瑟瑟發抖以為要被開除了。
對於資料的收集,活用數位資料的公司會提供無償服務甚至給予一些獎勵來取得資料,然後在其他地方利用這些資料獲得收益。譬如 :

得到了資料,我們就能透過一些工具提升作業上的效率,譬如機器學習和資料科學。
| 項目 | 機器學習 | 資料科學 |
|---|---|---|
| 產出 | 一個程式 | 一份報告 |
| 作用 | 用 A 預測 B | 針對 A 和 B 的關係提出假設和建議 |
這邊以製造業的觀點來舉例兩者間的差異:
結果:節省了人去用眼睛檢查製品龜裂的時間,增加客戶信賴也降低了人事成本。
結果:降低了不良率,增加客戶信賴同時減少了生產成本。
而像機器學習和資料科學等工具透過數位化資料來提高工作效率或帶來附加價值的行為,叫做數位優化(Digitalization)。
數位優化還有一個常聽到的工具:機器人流程自動化(RPA,Robotic process automation),將重複性質高的作業流程使用程式來自動完成可以節省人力。
例如:自動彙整定期報表 + 自動寄送報告。
前面介紹完數位化,數位優化,那麼什麼是數位轉型呢?下面這張圖方便幫助理解:
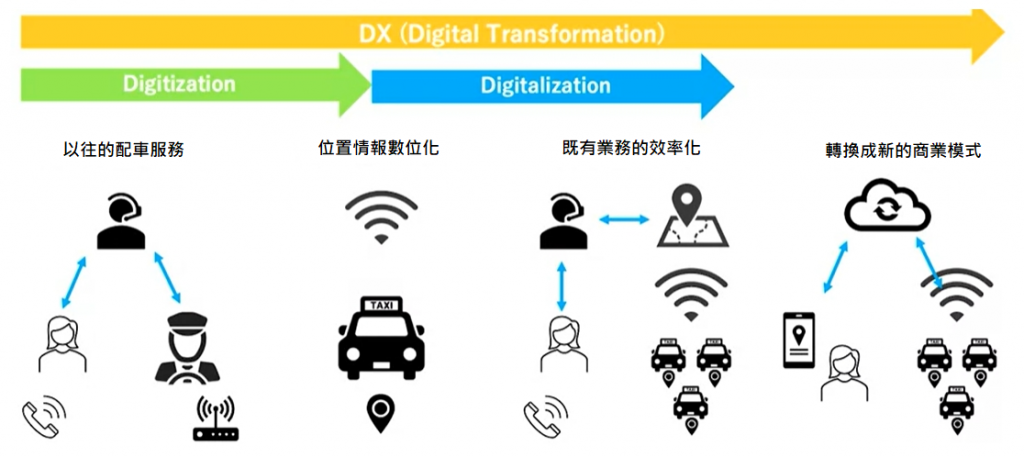
ーー原圖出處:JDLA 日文講義
上述的數位轉型例子就是大家熟知的 Uber。
所以為什麼提到運用 AI ,都會提到數位化和數位轉型。因為有了數位化,就能將傳統資料轉換成數位資料給 AI ,才能運用 AI 做數位優化。也就是對企業而言,用數位轉型取得優勢是目的,AI 只是手段之一。
在商言商,使用數位優化獲取利益,並試圖尋找出新的賺錢契機,打造新的商業護城河才能領先對手,避免被科技的進步所淘汰。
Landing.AI 創辦人 Andrew Ng 教授在2021年舉辦了一場以資料為中心的 AI 競賽,什麼是資料為中心 AI 呢?以 AI 系統來說:
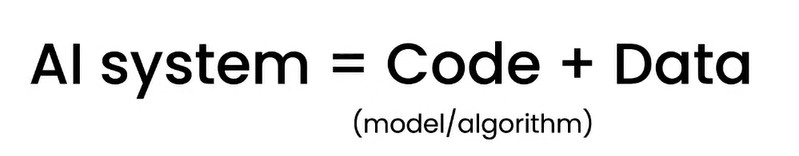
ーー AI 系統 = Code + Data,出處:A Chat with Andrew on MLOps: From Model-centric to Data-centric AI
模型為中心 AI(Model-centric AI)
使用固定的資料(Data),試著從改善程式(Code),也就是更動模型參數或更換演算法來提高 AI 系統的預測準確度。
一般的手法, Kaggle 競賽都是使用這種方法。
資料為中心 AI(Data-centric AI)
使用固定的程式(Code),也就是在不更動模型參數和演算法的情況下,試著改善資料(Data)的品質來提高 AI 系統的預測準確度。
那麼事實上,Andrew Ng 教授提到當 AI 系統訓練到某個不錯的預測準確度時(Baseline),與其改善程式,改善資料的成效會更大,譬如下面的實例:
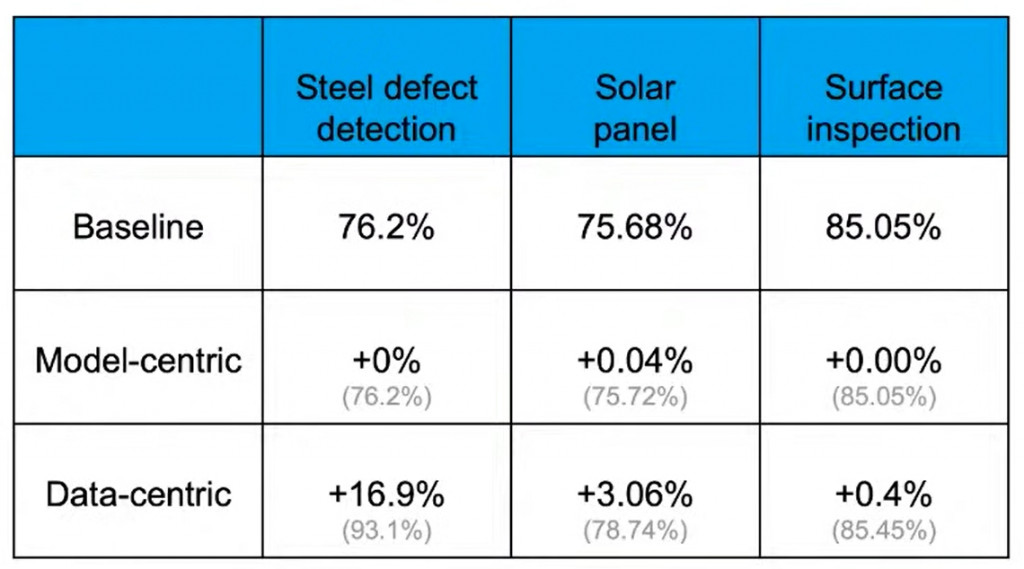
ーー 出處:A Chat with Andrew on MLOps: From Model-centric to Data-centric AI
在鋼材缺陷偵測,太陽能面板缺陷和表面檢查這三種任務時,模型為中心的方法很難再做更好的提升,而資料為中心的手法在2周左右就將鋼材缺陷偵測提高了 16.9%。
今天的文章一開始也提到,資料處理花了我們很多時間,而 AI 系統有點像料理,資料就是食材,食材處理比如說洗菜,切菜,去筋,去皮,切塊也是花了大半的時間,最後開火烹煮(模型訓練)卻只花了一點時間。而食材新不新鮮,乾不乾淨會影響到最後的成品好不好吃(預測準不準確)。這也就是資料處理的重要性,後面的篇章會提到資料為什麼是公司寶貴的資產,有可能成為企業的經濟護城河。


 iThome鐵人賽
iThome鐵人賽