2016年 AI 擊敗了圍棋頂尖棋士,那你知道機器人透過 AI 還可以做跑酷和後空翻嗎?讓我們來看一下動作靈活的機器人影片。

ーー出處:Youtube
上述影片是使用了深度強化學習的技術。機器學習模型時有提過強化學習,今天要來談談加入了深度學習的強化學習是怎麼回事。
影片中機器人做平衡微調是深度強化學習的成果,但是除了深度強化學習也加入了其他控制程式才能辦到,不全然只有強化學習。
深度強化學習最早是在 2013年, DeepMind 結合了深度學習和強化學習,可以在 Atari2600(一個街機遊戲機,共57種遊戲)的部分遊戲中超過人類玩家的分數。

ーー 出處: DQN 論文
DeepMind 2014年被 google 收購
使用的是 DQN 演算法,我們順便來複習一下強化學習的馬爾可夫決策過程:
DQN 除了 Q 學習,在步驟 2. 還另外用了2個新技巧:
Double DQN
選最大Q值容易有價值高估的問題,所以 Double DQN 將動作選擇和價值評估兩個獨立出來,這就是雙 Q 學習,目的在減少動作價值被高估的問題。
優先經驗再生(prioritized experience replay)
針對 Q 值誤差較大的部分優先做經驗再生。
Dueling network
將 Q 函數拆成評估狀態的函數(Value fuction)和預測該狀態的動作價值函數(Adavantage function)。
中心思想是,有時候無論你做什麼,狀態的價值都是一樣的,比方說棋盤的局面你怎麼下棋(動作)結果都是要輸,透過狀態的評估可以加快學習的速度。
Distributional DQN
將行動價值函數換成價值分布。實際上成果比用行動價值函數更好。後述的 Rainbow 靠著這個方法和優先經驗再生提高非常多的性能。
Noisy network
使用 Epsilon 貪婪策略會隨機作探索,而 Noisy network則是將來自常態分佈的隨機數(噪聲,Noisy)加到權重,允許網路根據需求控制隨機數大小。也就是對探索做改善。
Rainbow(彩虹)
DQN和上述演算法的集合體,性能飛躍性地成長。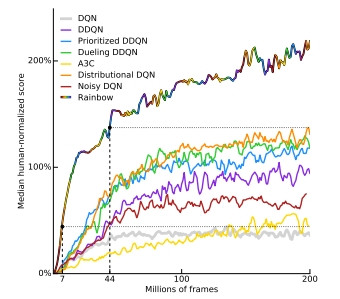
ーー 出處:Rainbow 論文
A3C 在 Day10 有稍微提到,主要就是參與者-評價者(Actor-Critic) 透過複數的 CPU/GPU 做並行運算提高速度。
Agent57
2020年發表的 Agent57 是 DeepMind 集大成的結果,Atari2600 所有的遊戲分數都擊敗人類玩家。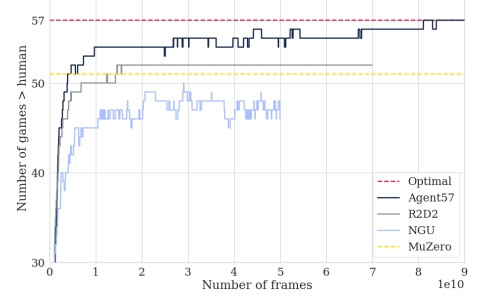
ーー 57種遊戲制霸 by Agent57,出處:Agent57 論文
ーー Agent57 playing Solaris
Day3 有介紹過,如果沒有時間限制,理論上透過搜尋樹作所有組合的暴力搜尋一定可以找到必勝法。但是實際上時間是有限制的,所以就誕生了各種棋盤 AI。
搜尋樹用蒙地卡羅方法,隨機讓遊戲玩到結束(Playout)找到勝率最高的方法。
2016年打敗世界頂尖棋士。透過蒙地卡羅樹和深度強化學習的組合獲勝。
AlphaGo的架構有3個:
簡單來說,先透過監督學習模仿專家(棋譜),站在巨人的肩膀上讓學習的起點更高,再透過這個專家互打來做強化學習,而只要贏了,價值網路就為1,輸了價值網路為-1,反覆用來學習人類評估盤面的方法。而有了策略網路和價值網路來縮小搜尋範圍,就可以透過蒙地卡羅樹模擬數量有限的遊戲找出相對高勝率的方法,
2017年10月発表,完全不使用人類棋譜,單純讓 AlphaGo 自己和自己重複對戰獲得經驗做深度強化學習。 學習初期雖然比人類玩家弱,但透過學習修正,學習的越久就越強,等於是有1個人類玩家無限期的累積對戰經驗。
以電玩來說就是一般人終其一生圍棋等級最高只能升到99級,而 AI 可能隨著花費的時間已經9999級的概念。
已經不侷限在圍棋,各種棋盤遊戲都能夠超過人類玩家,和 AlphaGo Zero 一樣只靠 AI 自己對戰來學習成長。
在棋盤遊戲已經稱霸的 AI,將眼光移到了下一個目標:多人對戰。
2018年 OpenAI 發表 OpenAI Five,在線上多人對戰遊戲 Dota2 打贏了頂尖玩家組成的團隊。比較特別的是和其他模型相比花費了巨大的資源(該說真不愧是 OpenAI 嗎)。5萬個 cpu 和 1024 個 gpu 。
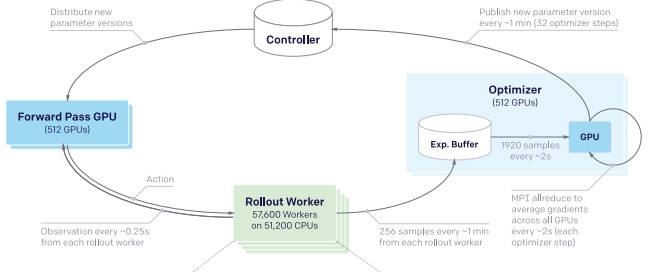
ーー出處:Dota 2 with Large Scale Deep Reinforcement Learning
2019年 DeepMind 在即時戰略(RTS,Real-Time Strategy)星海爭霸2的對戰中,透過 AlphaStar 擊敗有大師(Grandmaster )稱號的頂尖玩家。

ーー AlphaStar訓練過程,出處:youtube
初期 AlphaStar 雖然只能侷限於使用於一張遊戲地圖,但是隨著強化學習越來越適應各種狀況。如下圖使用了圖像和自然語言等多種模型,包含了 ResNet,Attention,Transformer 等等的演算模型。
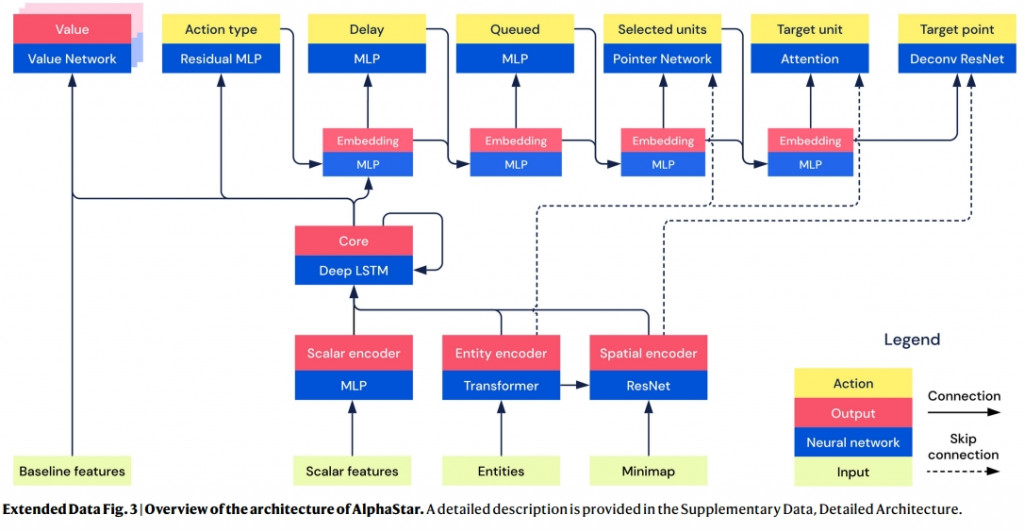
ーー出處:Grandmaster level in StarCraft II using
multi-agent reinforcement learning
目前深度強化學習在遊戲上大放異彩的原因是,和現實世界比起來遊戲的環境相對單純。而現實世界有幾個困難點:
而針對上述的問題有幾個對策:
如果有試著寫強化學習的程式就會用到 OpenAI gym 這個程式庫,可以用來模擬各種環境。
 )
)

 iThome鐵人賽
iThome鐵人賽